
Django中ORM操作#2
文章目錄
- 必知必會的13條查詢方法
- 單表查詢之神奇的雙下劃線
- 一對多 ForeignKey
- 多對多 ManyToManyField
- 在Python指令碼中呼叫Django環境
- Django終端列印SQL語句
- 關於Mate類
- 聚合查詢 aggregage()
- 分組查詢 annotate()
- F查詢
- Q查詢
- 事務
- 其它鮮為人知的操作
必知必會的13條查詢方法
1. all()
查詢所有結果
.
2. get(**kwargs)
返回與所給篩選條件相匹配的物件,返回結果有且只有一個.
如果符合篩選條件的物件超過一個或者沒有,都會跑出異常.
.
3. filter(**kwargs)
返回所有符合篩選條件的物件.
.
4. exclude(**kwargs)
返回所有不符合篩選條件的物件
.
5. values(*field)
返回一個ValueQuerySet(一個特殊的QuerySet).
執行後得到的並不是一系列model的例項化物件,而是一個可迭代的字典序列.
例如(返回值):
<QuerySet [{‘id’: 1, ‘name’: ‘zyk’, ‘age’: 24, ‘birth’: datetime.datetime(2018, 10, 11, 1, 17, 47, 380591, tzinfo=), ‘phone’: ‘17600390376’}]>
.
6. values_list(*field)
它與values()非常類似,它返回的是一個元組序列,values返回的是一字典序列
.
7. order_by(*field)
對查詢結果排序.
引數接收字串型別的欄位,指定按某個欄位排序.
使用負號(例如"-1")可以實現降序.
.
8. reverse()
對查詢結果反向排序.
通常只能在具有以定義順序的QuerySet上呼叫(在model類的Meta中指定ordering或呼叫order_by()方法).
.
9. distinct()
從返回結果中剔除重複記錄.
如果查詢操作跨越多個表,可能在計算QuerySet時得到重複的結果,此時可以使用distnct(),注意只有在PostgreSQL中支援按欄位去重.
它是對整個物件的去重,不是對資料去重.
.
10. count()
返回資料庫中匹配查詢(QuerySet)的物件那個數量.
.
11 first()
返回第一條記錄
.
12 last()
返回最後一條記錄
.
13 exists()
如果QuerySet包含資料返回True,否則False.
.
.
.
返回物件列表(QuerySet)的有:
all()
filter()
exclude()
order_by()
reverse()
distinct()
values() -> [{}]
values_list() -> [()]
.
返回具體物件的有:
get()
first()
last()
create()
.
返回布林值的有:
existe()
.
返回數字的有:
count()
單表查詢之神奇的雙下劃線
filter(id__gt=2, id__lt=4)
獲取id 大於2 且 小於4 的物件.
.
filter(id__gte=2, id__lte=4)
獲取id 大於等於2 且 小於等於4 的物件.
.
filter(id__in=[2, 4])
獲取所有id等於2, 4的資料.
.
filter(name__contains=‘yk’)
獲取所有name欄位包含’yk’的物件.
.
filter(name__icontains=‘yk’)
獲取所有name欄位包含’yk’的物件,忽略大小寫.
.
filter(id__range=[1, 3])
獲取id範圍在1-3的物件,顧頭顧尾.
等價於SQL語句的bettwen and
.
filter(date__year=2018)
獲取date欄位時間為2018年的物件.
.
__isnull = True
判斷欄位是否為空, 為空返回True.
.
類似的還有:startswith, istartswith, endswith, iendswith
一對多 ForeignKey
正向查詢
1. 物件查詢(跨表)
語法:物件.關聯表.關聯表的欄位
示例:
# 獲取第一個學生物件:
stu_obj = models.Students.objects.first()
# 獲取這個學生的班級物件:
stu_obj.classes
# 獲取這個學生的班級物件名稱:
stu_obj.classes.name
2. 欄位查詢(跨表)
語法:關聯表__關聯表的欄位
示例:
# 獲取id為7的學生的班級姓名:
models.Students.objects.filter(id=7).values_list('classes__name')
反向操作
1. 物件查詢
語法:obj.表名_set
示例:
# 獲取第一個班級:
class_obj = models.Classes.objects.first()
# 獲取這個班級的所有學生:
students = class_obj.students_set.all()
# 獲取這個班級所有學生的姓名:
students.values_list('name')
2. 欄位查詢
語法:表名__欄位
示例:
# 獲取id為9的班級的所有學生的姓名:
models.Classes.objects.filter(id=9).values_list('students__name')
多對多 ManyToManyField
"關聯管理器"是在一對多或者多對多的關聯上下文中使用的管理器.
他存在與下面兩種情況:
- 外來鍵關係的反向查詢
- 多對多關聯關係
簡單來說,就是當點(.)後面的物件可能存在多個的時候就可以使用以下的方法:
create()
示例:# 通過班級物件反向建立教師: models.Classes.objects.first().teachers_set.create(name='teacher07').
add()
把指定的model物件新增到關聯物件集中.
新增物件:# 獲取id為9, 10, 11的班級物件 class_objs = models.Classes.objects.filter(id__in=[9, 10, 11]) # 將這些班級新增到指定的教師物件行中 models.Teachers.objects.first().classes.add(*class_objs)新增id:
models.Teachers.objects.first().classes.add(*[9, 10 ,11]).
set()
更新model物件的關聯物件.# 獲取教師物件 tea_obj = models.Teachers.objects.first() # 將其重新設定班級 tea_obj.classes.set([9, 10, 11]).
remove()
從關聯的物件集中移除指定的model物件.# 獲取教師物件 tea_obj = models.Teachers.objects.first() # 刪除id為9的班級 tea_obj.classes.remove(9).
clear()
清空# 獲取教師物件 tea_obj = models.Teachers.objects.first() # 刪除所有班級 tea_obj.classes.clear().
對於ForeignKey物件,clear() 與 remove() 方法僅在關聯欄位設定了null=True時存在.
注意:
對於所有型別的關聯欄位,add()、create()、remove()、clear()、set() 都會立即更新資料庫。換句話說,在關聯的任何一端,都不需要再呼叫save()方法.
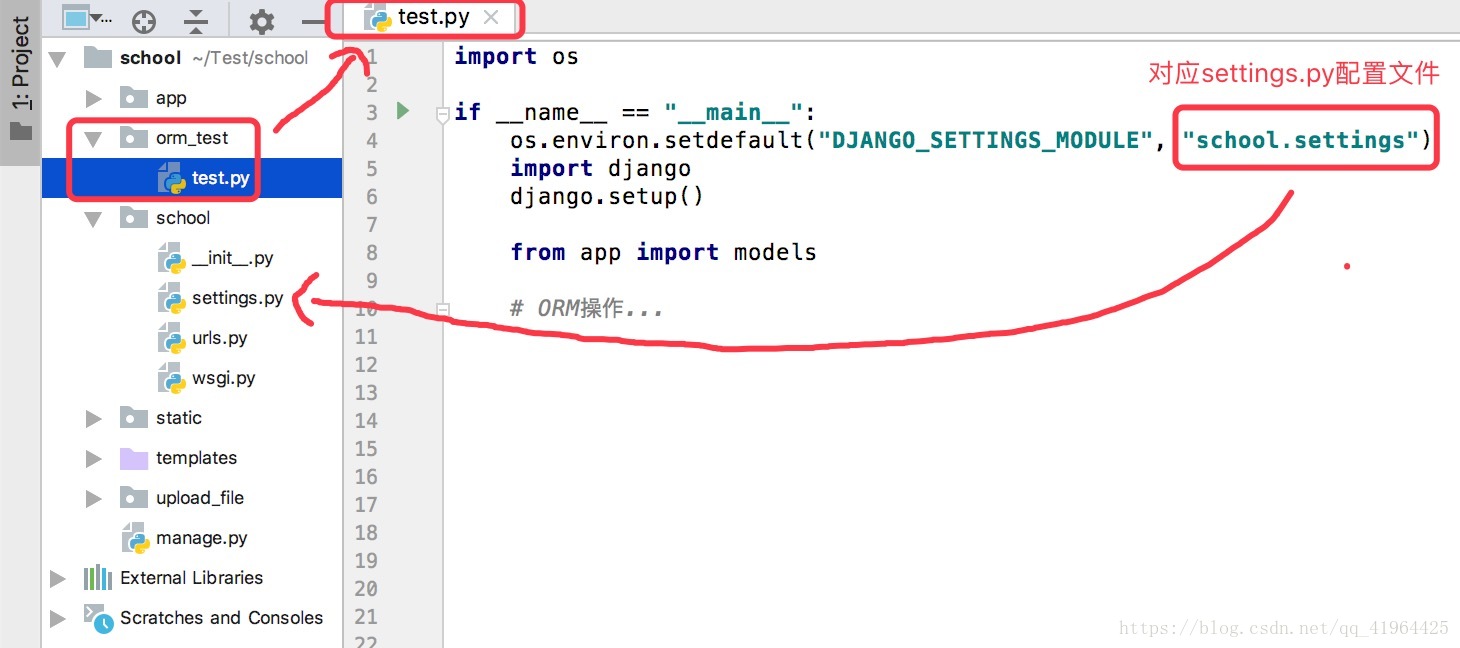
在Python指令碼中呼叫Django環境
Django終端列印SQL語句
在Django專案的settings.py檔案中,在最後複製貼上如下程式碼:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
關於Mate類
# 班級
class Classes(models.Model):
name = models.CharField(max_length=64, verbose_name='姓名', db_column='myname')
# db_column:自定義資料庫列名 verbose_name:自定義admin網頁中顯示的欄位名
class Meta:
# 自定義資料庫中生成的表名稱:
db_table = 'classes'
# admin網頁中顯示的表名稱:
# verbose_name = "班級" # 會在名稱後面加"s"
verbose_name_plural = "班級資訊" # 不會在名稱後面加"s"
# 聯合索引:
# index_together = [
# ("欄位1", "欄位2") # 應為兩個存在的欄位
# ]
# 聯合唯一索引:
# unique_together = (("欄位1", "欄位2"),) # 應為兩個存在的欄位
聚合查詢 aggregage()
aggregate()是QuerySet的一個終止子句(必須放在語句的最末尾),意思是說,他返回一個包含一些鍵值對的字典.
鍵的名稱是聚合值的標識,值是計算出來的聚合值.
鍵的名稱是按照欄位和聚合函式的名稱自動生成出來的.
需要用到的函式:
from django.db.models import Avg, Sum, Max, Min, Count
示例:
# 計算所有書的平均價格:
models.Book.objects.all().aggregate(Avg('price'))
可以為聚合的值指定名稱(key):
models.Book.objects.all().aggregate(avg=Avg('price'))
還可以生成不止一個聚合函式(多個鍵值對):
# 同時獲取書的平均價格, 最高價格, 最低價格:
models.Book.objects.all().aggregate(Avg('price'), Max('price'), Min('price'))
分組查詢 annotate()
我們使用原生SQL語句,按照出版社分組求書的平均價格:
select pub,AVG(price) from book group by publisher;
如果使用ORM查詢,語法如下:
models.Book.objects.values('publisher').annotate(avg=Avg('price')).values('publisher', 'avg')
連表查詢的分組:
SQL查詢:
select publisher.name,AVG(price) from book
inner join book
on (book.publisher_id=book.id)
group by book_id;
ORM查詢:
models.Publisher.objects.annotate(avg=Avg('book__price')).values('name', 'avg')
更多示例:
統一每一本書的作者個數:
models.Book.objects.all().annotate(count=Count('author')).values('title', 'count')
統計出每個出版社賣的最便宜的書的價格:
# 方法一:
Publisher.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
# 方法二:
models.Book.objects.values('publisher__name').annotate(min_price=Min('price'))
統計不止一個作者的圖書:
models.Book.objects.annotate(author_num=Count('author')).filter(author_num__gt=1)
根據一本圖書作者數量的多少對查詢集 QuerySet進行排序:
models.Book.objects.annotate(author_num=Count('author')).order_by('author_num')
查詢各個作者出的書的總價格:
models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
F查詢
在上面的例子中,我們構造的過濾器都只是將欄位值與某個常量做比較。如果我們要對兩個欄位的值做比較,那該怎麼做呢?
Django提供了F()來做這樣的比較,F()的例項可以在查詢中引用欄位,來比較同一個model例項中兩個不同欄位的值.
匯入:
from django.db.models import F
# 查詢庫存大於銷量的書:
models.Book.objects.filter(sale__gt=F('inve')).values('sale', 'inve')
Djano支援F()物件之間,以及 F()物件和常數之間的加減乘除和取模的操作:
# 查詢庫存大於銷量2倍的書:
models.Book.objects.filter(sale__gt=F('inve') * 2).values('sale', 'inve')
修改操作也可以使用F()函式:
# 將每一本書的價格提高10元:
models.Book.objects.update(price=F('price') + 10)
引申:
如果要修改char欄位咋辦?
如:把所有書名後面加上(第一版):
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value("("), Value("第一版"), Value(")")))
Q查詢
filter()等方法中的關鍵字引數查詢都一起進行"AND"的,如果要執行更復雜的查詢(例如OR查詢),你可以使用Q物件.
匯入:
from django.db.models import Q
示例:
# 查詢作者名是"zyk"或"zyk01"的書:
models.Book.objects.filter(Q(author__name="zyk") | Q(author__name="zyk01")).values_list('title', 'author__name')
可以組合使用 & 和 | 操作符以及使用括號進行分組來編寫任意複雜的Q物件。同時,Q物件可以使用 ~ 操作符取反,這允許組合正常的查詢和取反(NOT)查詢.
示例:
# 查詢作者名字是"zyk"並且不是2018年出版的書的書:
models.Book.objects.filter(Q(author__name="zyk") & ~Q(publish_date__year=2018)).values_list('title', 'author__name', 'publish_date')
查詢函式可以混合使用Q物件和關鍵字引數。所有提供給查詢函式的引數(關鍵字引數或Q物件)都將"AND"在一起。但是,如果出現Q物件,它就必須位於所有關鍵字引數的前面。也就是所,Q物件必須放在關鍵字引數的前面.
示例:
# 查詢出版年份是2017或2018,書名中帶"邏輯"的所有書:
models.Book.objects.filter(Q(publish_date__year=2017) | Q(publish_date__year=2018), title__icontains="邏輯")
更多用法(專案摘):
def get_search_contion(self, query_list):
"""
模糊查詢
:param query_list: 資料庫欄位列表
:return:
"""
query = self.request.GET.get('query', '')
q = Q()
q.connector = 'OR'
for i in query_list:
q.children.append(Q(('%s__contains' % i, query)))
return q
# 呼叫:
q = self.get_search_contion(sql_field)
all_customer = models.Customer.objects.filter(q, consultant__isnull=True)
事務
要麼都成功,要麼都失敗.
import os
if __name__ == '__main__':
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'blog.settings')
import django
django.setup()
from blog01 import models
try:
from django.db import transaction
with transaction.atomic():
new_publisher = models.Publisher.objects.create(name="西二旗程式設計師太多出版社")
models.Book.objects.create(title="Python終極爬蟲", publisher_id=100)
# 這裡的"publisher_id=100"指定了一個不存在的id, 因此這兩條語句都失敗.
except Exception as e:
print(str(e))
其它鮮為人知的操作
行級鎖:
def multi_apply(self):
"""公戶變私戶"""
ids = self.request.POST.getlist('id')
apply_num = len(ids)
# 判斷當前銷售的客戶加上要轉為私有的客戶的總量是否大於最大限制
if self.request.user.customers.count() + apply_num > settings.CUSTOMER_MAX_NUM:
return HttpResponse("做人不要太貪心,給別人的機會")
# 如果同時有多個銷售搶一個客戶:
with transaction.atomic():
# 事務
# select_for_update:加鎖
obj_list = models.Customer.objects.filter(id__in=ids, consultant__isnull=True).select_for_update()
if apply_num == len(obj_list):
obj_list.update(consultant=self.request.user)
else:
return HttpResponse("手速太慢")
Django ORM執行原生SQL:
# extra
# 在QuerySet的基礎上繼續執行子語句
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# select和select_params是一組,where和params是一組,tables用來設定from哪個表
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
舉個例子:
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
"""
# 執行原生SQL
# 更高靈活度的方式執行原生SQL語句
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
QuerySet方法大全:
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 獲取所有的資料物件
def filter(self, *args, **kwargs)
# 條件查詢
# 條件可以是:引數,字典,Q
def exclude(self, *args, **kwargs)
# 條件查詢
# 條件可以是:引數,字典,Q
def select_related(self, *fields)
效能相關:表之間進行join連表操作,一次性獲取關聯的資料。
總結:
1. select_related主要針一對一和多對一關係進行優化。
2. select_related使用SQL的JOIN語句進行優化,通過減少SQL查詢的次數來進行優化、提高效能。
def prefetch_related(self, *lookups)
效能相關:多表連表操作時速度會慢,使用其執行多次SQL查詢在Python程式碼中實現連表操作。
總結:
1. 對於多對多欄位(ManyToManyField)和一對多欄位,可以使用prefetch_related()來進行優化。
2. prefetch_related()的優化方式是分別查詢每個表,然後用Python處理他們之間的關係。
def annotate(self, *args, **kwargs)
# 用於實現聚合group by查詢
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用於distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct進行去重
def order_by(self, *field_names)
# 用於排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 構造額外的查詢條件或者對映,如:子查詢
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse則是倒序,如果多個排序則一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter