
pandas之DataFrame資料框
DataFrame資料框
1.建立資料框
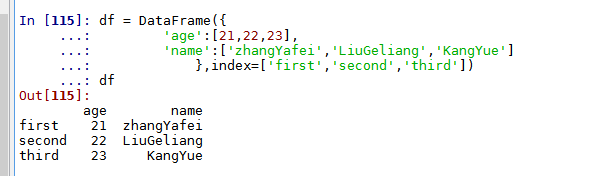
df = DataFrame({ 'age':[21,22,23], 'name':['zhangYafei','LiuGeliang','KangYue'] },index=['first','second','third'])
columns={}
columns['id'] = 1
columns['title'] = 'python'
columns['url'] = 'http://www.baidu.com'
data1 = DataFrame.from_dict(columns,orient='index').T
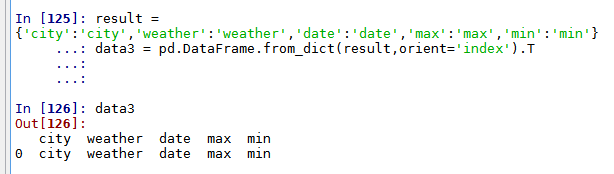
result = {'city':'city','weather':'weather','date':'date','max':'max','min':'min'}
data3 = pd.DataFrame.from_dict(result,orient='index').T
2.資料框的增刪改查
#增加行 注意:這種方法,效率非常低,不應該用於遍歷中 df.loc[len(df)]=[24,'scrapy'] #增加列 df['sex'] = [1,1,1,0]

刪
#根據行索引剔除 df = df.drop(4,axis=0)#根據列名剔除 df.drop('age2',axis=1) #第二種剔除列的方法 del df['age2']
df.drop(3,axis=0) Out[148]: age name sex first 21 zhangYafei 1 second 22 LiuGeliang 1 third 23 KangYue 1 df.drop('age',axis=1) Out[149]: name sex first zhangYafei 1 second LiuGeliang1 third KangYue 1 3 scrapy 0 df['sex2'] = [12,23,53,12] df Out[151]: age name sex sex2 first 21 zhangYafei 1 12 second 22 LiuGeliang 1 23 third 23 KangYue 1 53 3 24 scrapy 0 12 del df['sex2'] df Out[153]: age name sex first 21 zhangYafei 1 second 22 LiuGeliang 1 third 23 KangYue 1 3 24 scrapy 0
改
#修改列名 df.columns df.columns = ['age2','name2'] #修改行索引 df.index df.index = range(1,4) df.index
查
#按列名訪問 df['age'] df[['age','name']] #按行訪問 df[1:2] ix可以用數字索引,也可以用index和column索引 df.ix[0] d = df.ix[1:2,['age','name']]#取第0、1行列 #按行列號訪問 df.iloc[0:1,0:1] df.iloc[1] #loc只能通過index和columns來取,不能用數字 df.loc['first']) df.loc['first',['age','name']] #按行索引,列名訪問 df.at[0,'name'] df.at['first','name'] 根據條件邏輯值取值 df = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],'attr': [22, 33, 22, 44, 66]}, index=[10,20,30,40,50]) print(df) value= df[(df.BoolCol==3)&(df.attr==22)].values.tolist()[0] type(value) print(" ".join(str(id) for id in value)) index = df[(df.BoolCol==3)&(df.attr==22)].index.tolist() print(index)
3.資料框的遍歷
#遍歷列名
for r in df:
print(r)
#遍歷列
for cName in df:
print('df的列:\n',cName)
print('df的值:\n',df[cName])
print("-"*10)
遍歷行
第一種:apply方式 推薦
def new_data(row):
"""增加別名列"""
drug_name = row['藥品名稱']
try:
row['別名'] = drug_name.rsplit('(',1)[1].strip(')')
row['藥品名稱'] = drug_name.rsplit('(',1)[0]
except IndexError as e:
row['別名'] = np.NAN
return row
new_drug = data.apply(new_data,axis=1)
第二種:dataframe.iterrows
for row in data[10:13].iterrows():
drug_name = row['藥品名稱'].values
drug_alias = drug_name.rsplit('(',1)[1].strip(')')
print(drug_name)
print(drug_alias)
第三種:index方式
resoved_drug_list = []
for row in data.index:
drug_name = '{}[{}]'.format(data.iloc[row]['藥品名稱'],data.iloc[row]['藥品ID'])
resoved_drug_list.append(drug_name)
第四種:values方式
for r in df.values:
print(r)
print(r[0])
print(r[1])
print('-'*10)
第五種:while遍歷DataFrame
df = DataFrame({
'age':Series([21,22,23]),
'name':Series(['zhang','liu','kang'])
})
rowCount = len(df)
i = 0
while i<rowCount:
print(df.iloc[i])
i+=1
補充:
#遍歷字串
for letter in 'python':
print('現在是:',letter)
#遍歷陣列
fruits = ['banana','apple','mango']
for fruit in fruits:
print('現在是:',fruit)
#遍歷序列
x = Series(['a',True,1],index=['first','second','third'])
x[0]
x['second']
x[2]
for v in x:
print('x中的值:',v)
for index in x.index:
print('X中的索引:',index)
print('x中的值:',x[index])
print('*'*10)
4.讀取檔案和資料框寫入檔案
讀取檔案 data = pandas.read_csv('drug_name.csv',encoding='utf-8') 寫入檔案 new_dataframe.to_csv('unique_chinese_name.csv',mode='w',encoding='utf_8_sig',index=False)