
對應分析及R使用
阿新 • • 發佈:2018-11-12
目錄
什麼是對應分析
對應分析是在因子分析基礎上發展起來的,因子分析分為R型和Q型因子分析,R型是對變數(指標)做因子分析,Q型是對樣品做因子分析,研究樣品之間的相互關係,對應分析是把R和Q統一起來,通過R型因子分析直接得到Q型因子分析的結果,同時把變數(指標)和樣品反映到相同的座標軸(因子軸)的一張圖形上,以此來說明變數(指標)與其樣品之間的關係。
對應分析的計算步驟
(1)由資料矩陣x,計算規格化的概率矩陣p
(2)計算過度矩陣
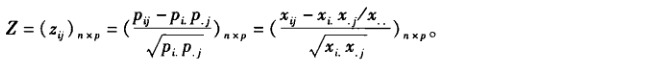
(3)進行因子分析
R型:
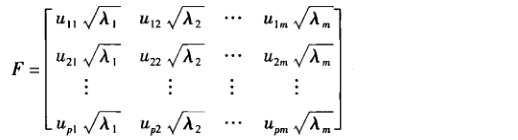
Q型:
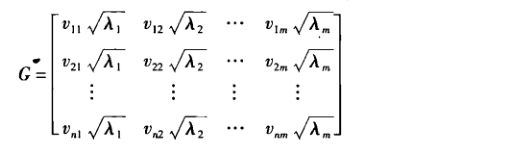
(4)做變數點圖與樣本點圖
R語言實現
高 中高 中 中低 低
好 121 57 72 36 21
輕微症狀 188 105 141 97 71
中等症狀 112 65 77 54 54
受損 86 60 94 78 71
> X=read.table("clipboard",header=T)#讀取例11.1資料
> chisq.test(X)#卡方檢驗
Pearson's Chi-squared test
data: X
X-squared = 45.594, df = 12, p-value = 8.149e-06
> > library(MASS)#載入MASS包 > ca1=corresp(X,nf=2)#對應分析 > ca1#對應分析結果 First canonical correlation(s): 0.16131842 0.03708777 Row scores: [,1] [,2] 好 -1.60963036 0.3578469 輕微症狀 -0.18259493 0.6086516 中等症狀 0.08802881 -1.8862612 受損 1.47098263 0.5310007 Column scores: [,1] [,2] 高 -1.13377133 -0.4184972 中高 -0.36589975 -0.6051416 中 0.05506891 1.1414935 中低 1.02532006 1.1682280 低 1.78331343 -1.6684803 >
> par(mar=c(4,4,3,1),cex=0.8)
> biplot(ca1)#雙座標軸圖
> abline(v=0,h=0,lty=3)#新增軸線
在影象中,相似的類會聚在一起,靠得很近,因而我們根據兩種定性變數之間的距離,就可以看出兩個變數的那些類相似,從而進行分組。
對應分析應注意的幾個問題
(1)不能用於相關關係的假設檢驗,對應分析兩個變數之間的聯絡,而不能說明這兩個變數存在的關係是否顯著,只是用來揭示這兩個變數內部類別之間的關係。
(2)維度有研究者根據變數所含的最小類別數決定,由於維度取捨不同,其所包含的資訊量也有所不同,一般來講,如果各變數所包含的類別較少,則在兩個維度進行對應分析時損失的資訊量才能減少。
(3)對極端值應該做敏感性研究
(4)研究物件要有可比性
(5)對應分析的基礎是交叉彙總表,即是列聯表,也表示行列的對應關係
(6)變數的類別應涵蓋所有可能出現的情況
(7)對應分析、因子分析和主成分分析雖然都是多變數統計分析,但對於分析的目的與因子分析或主成分分析的目的是完全不同的,前者是通過影象直觀地表現變數所含類別間的關係,後者則是降維。
(8)在解釋影象變數類別間關係時,要注意所選擇的資料標準化方式,不同的標準化方式會導致類別在影象上的不同分佈。