
R-描述性統計
RT。。。老實說這一章我是抖的。。。但是,加油~
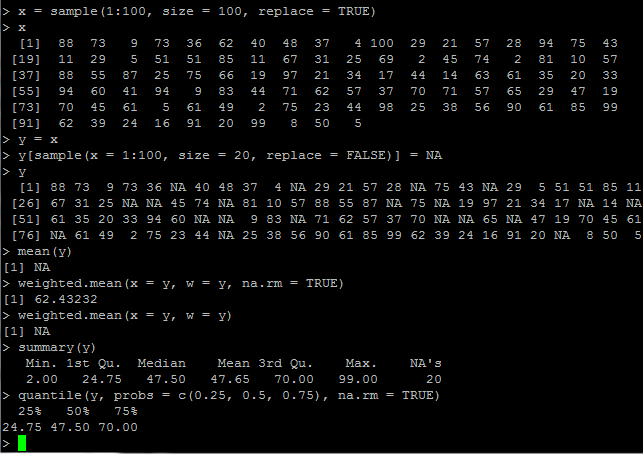
# 從1:100中均勻抽取size個數據,replace=TRUE指有放回抽樣,資料可以重複 x = sample(1:100, size = 100, replace = TRUE) y = x # 隨機設定y中有20%的缺失值 y[sample(x = 1:100, size = 20, replace = FALSE)] = NA # 不設定na.rm=TRUE的話,mean會返回NA,哪怕只有一個缺失值 # mean, weighted.mean, var, sd, min, max, median mean(y, na.rm = TRUE) # weighted.mean weighted.mean(x = y, w = y, na.rm = TRUE) # min, 1st quantile, median, mean, 3rd quantile, max, #NA summary(y) # probs設定想要的分位數,要設定na.rm quantile(y, probs = c(0.25, 0.5, 0.75), na.rm = TRUE)
相關推薦
R-描述性統計
RT。。。老實說這一章我是抖的。。。但是,加油~ # 從1:100中均勻抽取size個數據,replace=TRUE指有放回抽樣,資料可以重複 x = sample(1:100, size = 100, replace = TRUE) y = x # 隨機設定y中有20%的缺失值 y[sample
R語言實戰 - 基本統計分析(1)- 描述性統計分析
4.3 summary eas 方法 func -- 4.4 1.0 6.5 > vars <- c("mpg", "hp", "wt") > head(mtcars[vars]) mpg hp wt Maz
R-基本統計分析--描述性統計分析
及其 pre dice 數據集 returns length 平均值 sun 52.0 描述性統計分析主要包括 基本信息:樣本數、總和 集中趨勢:均值、中位數、眾數 離散趨勢:方差(標準差)、變異系數、全距(最小值、最大值)、內四分位距(25%分位數、75%分位數) 分布
R語言統計分析技術研究——嶺回歸技術的原理和應用
gts 根據 誤差 med 分享 jce not -c rt4 嶺回歸技術的原理和應用
留學生R經管統計作業代寫代做、Stat/ME代寫
not 學生 搭建 網站 ria ova reat coo HA 留學生R經管統計作業代寫代做、Stat/ME代寫Requirements for Stat/ME 424 Class Project? This is an individual project. You c
描述性統計的matlab實現
pre tool nes http 調用 一點 bsp log 文件 理論講的再多不會做也白弄 直接上手 一.針對接近正態分布的(均值,方差,標準差,極差,變異系數,偏度,峰度) 這裏我必須提前說明一點就是,你在寫好函數後,函數的名是dts,你保存的文件名也必須是dts.m
第二章 描述性統計
nbsp 頻率 高度 相對 個數 常用 定性 中心 定義 2.1 描述定性數據的圖形法和數值法 定義2.1 類(或組)頻數:落入這個類中的觀測值的個數 類(或組)相對頻率:落入這個類中的觀測值的個數相對於觀測值總數的比例 定性數據描述常用條形圖和餅圖 條形圖:給出每一類的頻
R-基本統計分析--獨立、相關性及其檢驗
獨立性檢驗-(卡方、Fisher) 獨立性檢驗_百度百科 https://baike.baidu.com/item/%E7%8B%AC%E7%AB%8B%E6%80%A7%E6%A3%80%E9%AA%8C/4031921?fr=aladdin R之獨立性檢驗 -
R語言統計入門課程推薦——生物科學中的資料分析Data Analysis for the Life Sciences
Data Analysis for the Life Sciences是哈佛大學PH525x系列課程——生物醫學中的資料分析(PH525x series - Biomedical Data Science ),課程全部採用R語言進行統計分析理論教學與實戰。教材採用Rmarkdo
分享《機器學習與資料科學(基於R的統計學習方法)》高清中文PDF+原始碼
下載:https://pan.baidu.com/s/1Lrgtp7bnVeLoUO46qPHFJg 更多資料:http://blog.51cto.com/3215120 高清中文PDF,299頁,帶書籤目錄,文字可以複製。配套原始碼。 本書指導讀者利用R語言完成涉及機器學習的資料科學專案。作者: Da
分享《機器學習與數據科學(基於R的統計學習方法)》高清中文PDF+源代碼
data 圖片 intro enc proc 文字 目錄 baidu fff 下載:https://pan.baidu.com/s/1Lrgtp7bnVeLoUO46qPHFJg 更多資料:http://blog.51cto.com/3215120 高清中文PDF,299頁
分享《機器學習與數據科學(基於R的統計學習方法)》+PDF+源碼+Daniel+施翔
目錄 intro r語言 ges ati href ext 學習方法 learn 下載:https://pan.baidu.com/s/1TBuxErDDcKQi4oJO3L-fEA 更多資料:http://blog.51cto.com/14087171 高清中文PDF,2
python描述性統計分析
1、 數值分析 from numpy import array from numpy.random import normal, randint list_data = [1, 2, 3] #使用List來創造一組資料 array_data = array([1, 2
pandas 學習彙總12 - 描述性統計(比較全 tcy)
描述性統計 2018/12/4 1.統計函式說明: 大部分是聚合函式(因此產生低維結果)採用 軸引數(通過名稱或整數) 可選level引數,該引數僅在物件具有分層索引時才適用 可選skipna引數,一般預設排除系列輸入上的NA值。 2.視窗函式:
R語言--統計--PCA
test<-data.frame( x1=c(150,142,164,160,189,132,220,167,176,120,169,122,154,247,180,220,176,157,160,138 ), x2=c(30,28,30,32,35,36,38,34,31,33,40,50,
R語言--統計--決策樹
library(tree) Heart = read.csv("yumath.csv",header=TRUE,na.strings="NA") fit = tree(y1 ~ x1 + x2+ x3+x4+x5, Heart) summary(fit) plot(fit) text(fit)
MATLAB R2018a 統計和機器學習工具箱學習(一) 描述性統計與視覺化
MATLAB R2018a 統計和機器學習工具箱學習(一) 描述性統計與視覺化 該內容被分為三個部分: 一、資料管理(Managing Data); 二、描述性統計(Descriptive Statistics);
R語言--統計(六)
1. 平均值、中位數和模式 Mean平均值 I. 語法 用於計算R中的平均值的基本語法是 - mean(x, trim = 0, na.rm = FALSE, ...) 以下是所使用的引數的描述 - -- x是輸入向量。 -- trim用於從排序向量的兩端丟棄一些觀察結果。
機器學習與資料科學 基於R的統計學習方法(一)-第1章 機器學習綜述
1.1 機器學習的分類 監督學習:線性迴歸或邏輯迴歸, 非監督學習:是K-均值聚類, 即在資料點集中找出“聚類”。 另一種常用技術叫做主成分分析(PCA) , 用於降維, 演算法的評估方法也不盡相同。 最常用的方法是將均方根誤差(RMSE) 的值降到最小, 這一數值用於評價測試集的預測結果是否準確。 R
用python學概率與統計(第二章)描述性統計:表格法,圖形法
頻數分佈 2.1彙總定性資料 柱狀圖 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as pl