
Word2Vec --學習總結筆記
學習自此處
致謝李沐大神!
0、Word2vec
它將每個詞表示成一個定長的向量,並使得這些向量能較好地表達不同詞之間的相似和類比關係。Word2vec 工具包含了兩個模型:跳字模型(skip-gram)和連續詞袋模型(continuous bag of words,簡稱 CBOW),此外還有兩種訓練方法,分別為負取樣和層次softmax。
1、skip-gram
跳字模型假設基於某個詞來生成它在文字序列周圍的詞。舉個例子,假設文字序列是“the”、“man”、“loves”、“his”和“son”。以“loves”作為中心詞,設背景視窗大小為 2。跳字模型所關心的是,給定中心詞“loves”,生成與它距離不超過 2 個詞的背景詞“the”、“man”、“his”和“son”的條件概率,即
假設給定中心詞的情況下,背景詞的生成是相互獨立的,那麼上式可以改寫成:

skip-gram訓練:
跳字模型的引數是每個詞所對應的中心詞向量和背景詞向量。訓練中我們通過最大化似然函式來學習模型引數,即最大似然估計。
最大似然估計是將文字序列中的所有條件概率連乘,然後求使該乘積最大化的引數。
這等價於最小化以下損失函式:
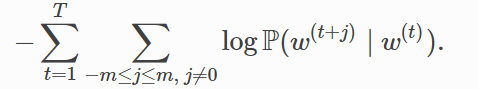
如果使用隨機梯度下降,那麼在每一次迭代裡我們隨機取樣一個較短的子序列來計算有關該子序列的損失,然後計算梯度來更新模型引數。梯度計算的關鍵是對數條件概率有關中心詞向量和背景詞向量的梯度。根據定義,首先看到:
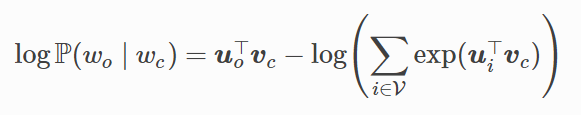
通過微分,我們可以得到上式中中心詞向量Vc的梯度:
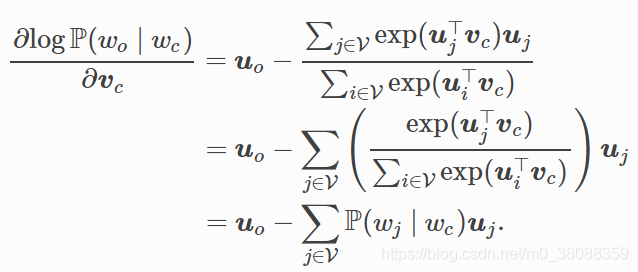

2、連續詞袋模型(CBOW)
連續詞袋模型與跳字模型類似。與跳字模型最大的不同在於,連續詞袋模型假設基於某中心詞在文字序列前後的背景詞來生成該中心詞。在同樣的文字序列“the”、 “man”、“loves”、“his”和“son”裡,以“loves”作為中心詞,且背景視窗大小為 2 時,連續詞袋模型關心的是,給定背景詞“the”、“man”、“his”和“son”生成中心詞“loves”的條件概率:

注意以上的視窗大小為m!

CBOW訓練:
連續詞袋模型訓練同跳字模型訓練基本一致。連續詞袋模型的最大似然估計等價於最小化損失函式:
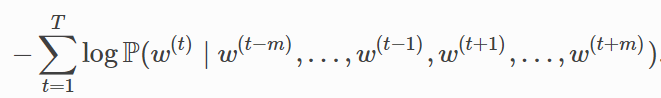
其中:
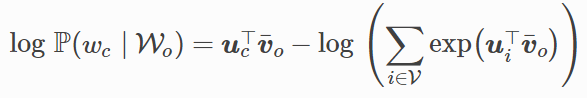
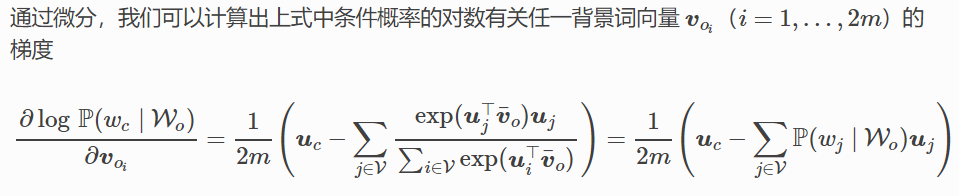
有關其他詞向量的梯度同理可得。同跳字模型不一樣的一點在於,我們一般使用連續詞袋模型的背景詞向量求平均作為詞的表徵向量。
綜上,發現用softmax做條件概率計算,每一步的梯度計算都包含詞典大小V數目的項的累加。對於含幾十萬或上百萬詞的較大詞典,每次的梯度計算開銷可能過大。也即計算複雜度為O(|V|),如此訓練顯然有些不友好。
所以延伸了以下的兩個近似訓練方法:負取樣(negative sampling)或層序 softmax(hierarchical softmax),使得計算複雜度降低,減少時間開銷。
3、negative sampling
以skip-gram為例:



可以發現對數損失中的每一項的複雜度不再是與詞典大小V線性相關,而是噪聲詞的數量大小K線性相關,當K取值較小時(不能為負),負取樣在每一步的梯度計算開銷較小。
補充:
噪聲詞概率P(w)在實際中被建議設為w的單字概率的3/4次方。原因是這樣可以使生僻詞更容易被取樣。
要表示一個短語的向量,原論文裡是直接將組成該短語的單詞的向量線性相加。當然實際工程中也可以對這些單詞求平均。
4、層次softmax
層序 softmax 是另一種近似訓練法。它使用了二叉樹這一資料結構,樹的每個葉子節點代表著詞典 V 中的每個詞。所以第一步我們需要先構建霍夫曼樹,霍夫曼樹的構建依賴的是詞頻統計,然後按照霍夫曼樹的規則建立起來,樹的每個節點表示詞典每個詞。規定左子樹[x]=1,右子樹[x]=−1。
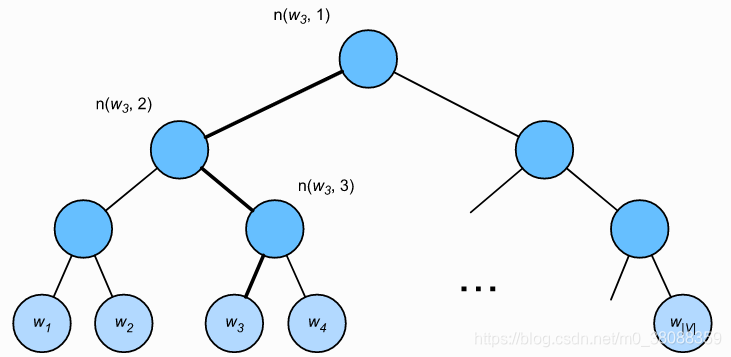

5、小結
(1)負取樣通過考慮同時含有正類樣本和負類樣本的相互獨立事件來構造損失函式。其訓練中每一步的梯度計算開銷與取樣的噪音詞的個數線性相關。
(2)層序 softmax 使用了二叉樹,並根據根節點到葉子節點的路徑來構造損失函式。其訓練中每一步的梯度計算開銷與詞典大小的對數相關。
(3)在使用softmax的跳字模型和連續詞袋模型中,詞向量和二叉樹中非葉子節點向量是需要學習的模型引數。
(4)層序softmax已經通過Huffman編碼唯一的確定了所有遍歷路徑。