
二.線性神經網路
自適應線性元件20世紀50年代末由Widrow和Hoff提出,主要用於線性逼近一個函式式而進行模式聯想以及訊號濾波、預測、模型識別和控制等。
線性神經網路和感知器的區別是,感知器只能輸出兩種可能的值,而線性神經網路的輸出可以取任意值。線性神經網路採用Widrow-Hoff學習規則,即LMS(Least Mean Square)演算法來調整網路的權值和偏置。線性神經網路在結構上與感知器非常相似,只是神經元啟用函式不同。在模型訓練時把原來的sign函式改成了pureline函式(y=x)
只能解決線性可分的問題。
與感知器類似,神經元傳輸函式不同。
線性神經網路結構
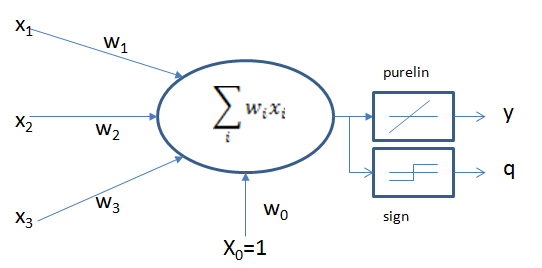
兩個啟用函式,當訓練時用線性purelin函式,訓練完成後,輸出時用到sign函式 (>0, <0)
假設輸入是一個N維向量(公式1),從輸入到神經元的權值為wi,則輸出為公式2.
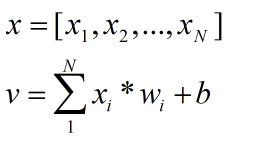
若傳遞函式採用線性函式purelin,則輸入與輸出為一個簡單的比例關係,x(n),w(n),y,q寫成矩陣的形式,公式如下、

若網路中包含多個神經元節點,則可以形成多個輸出,這種可以以兩種間接的方式解決線性不可分問題
- 用多個線性函式對區域進行劃分,然後對各個神經元的輸出做邏輯運算
- 或者對神經元新增非線性輸入,引入非線性成分。
LMS 最小均方規則
LMS 學習規則可以看作是δ學習規則的一個特殊情況
LMS演算法只能訓練單層網路,,但是單層網路理論上講不會比單層網路差。
該學習規則與神經元採用的轉移函式無關,因而不需要對轉移函式求導,不僅學習速度較快,而且具有較高的精度,權值可以初始化為任意值,通過權值調整使得神經元實際輸出與期望輸出之間的平方差最小:
定義某次迭代時的訊號為 e(n)=d(n)-xT(n)w(n)
n為迭代次數,d表示期望輸出,採用均方誤差作為評價指標。
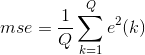
Q是輸入訓練樣本的個數。線性神經網路學習的目標是找到適當的w,使得均方差mse最小。mse對w求偏導,令偏導等於0求得mse極值,因為mse 必為正,二次函式凹向上,求得的極值必為極小值。
實際運算中,為了解決權值w維數過高,給計算帶來困難,往往調節權值,使mse從空間中的某一點開始,沿著斜面向下滑行,最終達到最小值。滑行的方向使該店最陡下降的方向,即負梯度方向。
實際計算中,代價函式常定義為
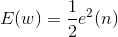


Delta學習規則
1986年,認知心理學家McClelland和Rumelhart 在神經網路訓練中引入該規則,也成為連續感知器學習規則
該學習規則是一種利用梯度下降法的一般性的學習規則
代價函式(損失函式) (Cost Function, Lost Function)
誤差E是權向量Wj的函式,欲使誤差E最小,Wj應與誤差的負梯度成正比

梯度即是導數,對誤差(代價/損失)函式求導,

 該學習規則可以推廣到多層前饋網路中,權值可以初始化為任意值。
該學習規則可以推廣到多層前饋網路中,權值可以初始化為任意值。
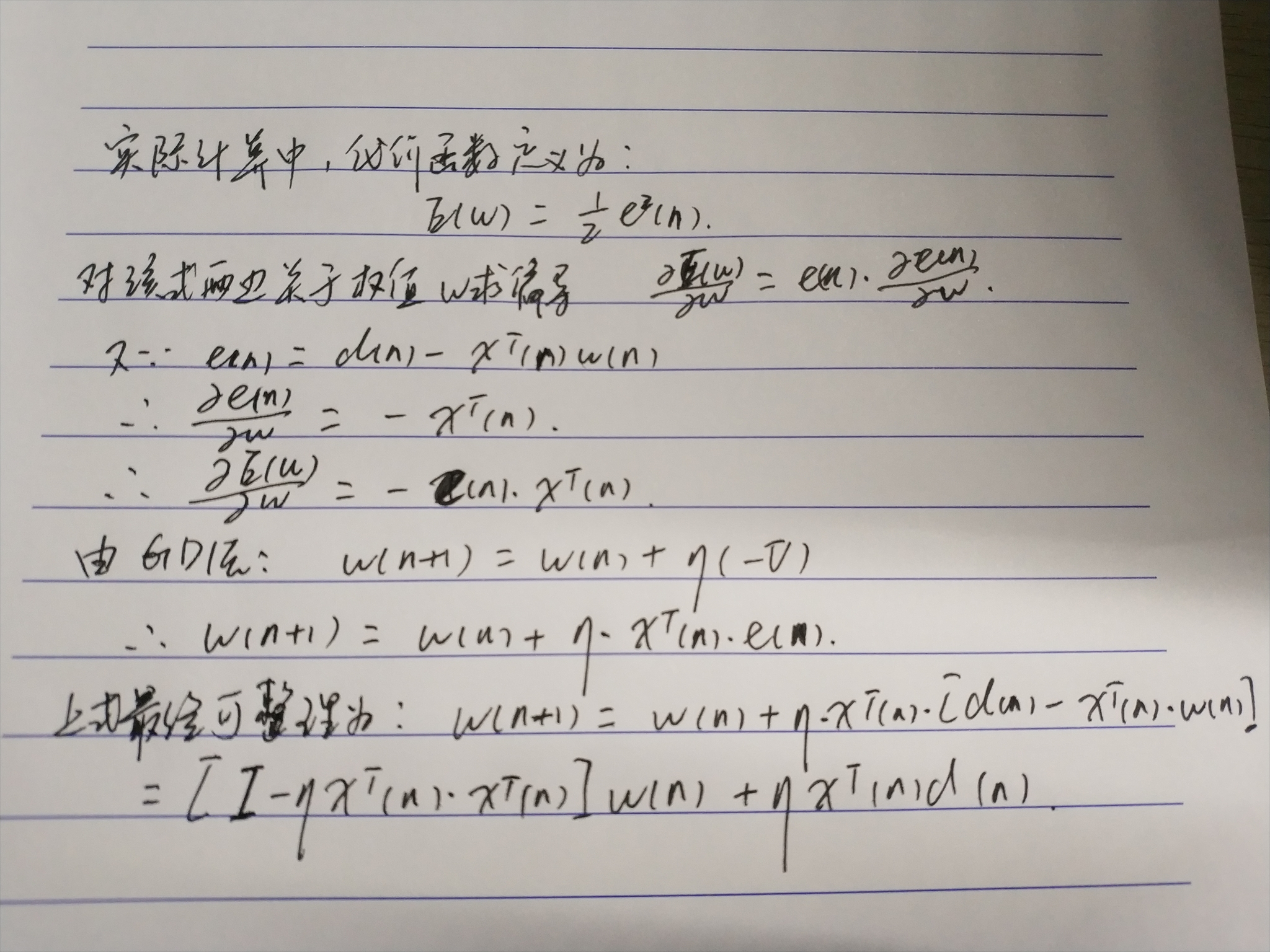
梯度下降法的問題
- 學習率難以選取,太大會產生振盪,太小收斂緩慢
- 容易陷入區域性最優解
- 第一個問題解決方法,開始的學習率可以設的較大,後面逐漸調小學習率
LMS演算法步驟
(1)定義變數和引數。
x(n)=N+1維輸入向量=[+1,x1(n),x2(n),...,xN(n)]T
w(n)=N+1維權值向量=[b(n),w1(n),w2(n),...,wN(n)]T
b(n)=偏置
y(n)=實際輸出
d(n)=期望輸出
η(n)=學習率引數,是一個比1小的正常數
(2)初始化。n=0,將權值向量w設定為隨機值或全零值,n=0。
(3)輸入樣本,計算實際輸出和誤差,根據給定的期望輸出d(n),計算得:e(n)=d(n)-xT(n)*w(n)
(4)更加所算的的結果調整權值向量(由上圖所給公式)
(5)判斷演算法是否收斂,若滿足收斂條件,則演算法結束,否則繼續
收斂條件:當權值向量w已經能正確實現分類時,演算法就收斂了,此時網路誤差為零。收斂條件通常可以是:
誤差小於某個預先設定的較小的值ε。即
|e(n)|<ε
兩次迭代之間的權值變化已經很小,即
|w(n+1)-w(n)|<ε
設定最大迭代次數M,當迭代了M次就停止迭代。
LMS演算法中學習率的選擇
LMS演算法中,學習率的選擇十分重要,直接影響了神經網路的效能和收斂性。
1996年Hayjin證明,只要學習率η滿足 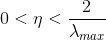 LMS演算法就是按方差收斂的。
LMS演算法就是按方差收斂的。
其中,λmax是輸入向量x(n)組成的自相關矩陣R的最大特徵值。往往使用R的跡(trace)來代替。矩陣的跡是矩陣主對角線元素之和。
可改寫成 0<η<2/向量均方值之和。
學習率逐漸下降:
學習初期,用比較大的學習率保證收斂速度,隨著迭代次數增加,減小學習率保證精度,確保收斂。
學習率逐漸下降如何設計:多種方式,自己可以思考思考
線性神經網路與感知器的對比
LMS演算法運用梯度下降法用於訓練線性神經網路,這個思想後來發展成為反向傳播演算法用於訓練多層神經網路。
兩者的傳輸函式不一樣導致感知器只能用於分類,而線性神經網路還可以用於擬合或者逼近
LMS演算法的分類邊界往往處於兩種模式的中間,容錯能力強,感知器演算法則在剛好能正確分類的地方就停下了,容錯能力差。