
機器學習-7(實戰演練k-近鄰演算法)
首先,這裡不討論你如何獲取資料,我們假設這些都已存在我們的庫裡面了,並已經建立好了正確的分類了。
這裡我直接截圖我的實驗庫吧:

現在我們的任務就是隨便輸入一個經緯度,來看看它屬於哪一個國家
先來把我們的讀取任務搞定吧

OK,初步清洗完成,把標籤國家拿出來了,經緯度拿出來了
先來拿10%來做測試樣本吧

錯誤率58,等於只對了42個,無法接受啊!我們繼續來用歸一的思想來計算一次

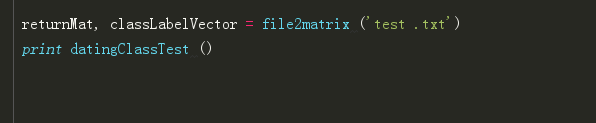
計算出來,錯誤率依然很高,OK,演示就到這裡了,我們來分析一下why?
我去看了下歷史資料,oh my god,原來是我的資料太少了,在這個演算法裡排序的時候,最近的3個,有的時候發現,3個最近的國家計數都是1.。。。。那這演算法他就按最先出來的那一個算老大了。。當然就錯誤了。。
所以這個演算法並不適合對於經緯度處於哪個國家的計算,或者說是因為我的資料太少,而且k取的太小
最後我反思了下,及時我的資料倉庫存在了很多很多資料,但是對於兩國或者多國邊界,即便我把k放大,如果是個小國家呢,比如越南和中國交界處。。。明顯中國的更多。。所以,總結就是,在此處我們需要另尋他法來解決這個問題了
如何解決,我們留到以後的章節再來細說了
相關推薦
機器學習-7(實戰演練k-近鄰演算法)
首先,這裡不討論你如何獲取資料,我們假設這些都已存在我們的庫裡面了,並已經建立好了正確的分類了。 這裡我直接截圖我的實驗庫吧: 現在我們的任務就是隨便輸入一個經緯度,來看看它屬於哪一個國家 先來把我們的讀取任務搞定吧 OK,初步清洗完成,把標籤國家拿出來了,經緯度拿出
機器學習實戰之k-近鄰演算法(3)---如何視覺化資料
關於視覺化: 《機器學習實戰》書中的一個小錯誤,P22的datingTestSet.txt這個檔案,根據網上的原始碼,應該選擇datingTestSet2.txt這個檔案。主要的區別是最後的標籤,作者原來使用字串‘veryLike’作為標籤,但是Python轉換會出現Val
py2.7 : 《機器學習實戰》 k-近鄰演算法 11.19 更新完畢
主要有幾個總結的: 1.python支援檔案模組化,所以在同一個目錄下import就可以呼叫了; 2.中文註釋要加上 # -*- coding: utf-8 -*- 3.import numpy 和 from numpy import * 區別是, 對於前者,呼叫的時候需要
《機器學習實戰》——kNN(k近鄰演算法)
原作者寫的太好了,包括排版都特別整齊(其中有一個錯誤之處就是在約會網站配對效果判定的時候,列表順序不對,導致結果有誤,這裡我已做出修改)執行平臺: Windows Python版本: Python3.x IDE: Sublime text3一 簡單k-近鄰演算法 本文將
機器學習實戰之k-近鄰演算法(4)--- 如何歸一化資料
歸一化的公式: newValue = (oldValue - min) / (max - min) 就是把資料歸一化到[0, 1]區間上。 好處: 防止某一維度的資料的數值大小對距離就算產生影響。多個維度的特徵是等權重的,所以不能被數值大小影響。 下面是歸一化特徵值的程式碼
機器學習實戰:K近鄰演算法--學習筆記
一、KNN的工作原理 假設有一個帶有標籤的樣本資料集(訓練樣本集),其中包含每條資料與所屬分類的對應關係。 輸入沒有標籤的新資料後,將新資料的每個特徵與樣本集中資料對應的特徵進行比較。 1) 計算新資料與樣本資料集中每條資料的距離。 2) 對求得的所有距離進
機器學習實戰筆記-K近鄰演算法2(改進約會網站的配對效果)
案例二.:使用K-近鄰演算法改進約會網站的配對效果 案例分析: 海倫收集的資料集有三類特徵,分別是每年獲得的飛行常客里程數、玩視訊遊戲所耗時間百分比、 每週消費的冰淇淋公升數。我們需要將新資
《機器學習實戰》——k-近鄰演算法Python實現問題記錄
《機器學習實戰》第二章k-近鄰演算法,自己實現時遇到的問題,以及解決方法。做個記錄。 1.寫一個kNN.py儲存了之後,需要重新匯入這個kNN模組。報錯:no module named kNN. 解決方法:1.將.py檔案放到 site_packages 目錄下
機器學習實戰之K-近鄰演算法總結和程式碼解析
機器學習實戰是入手機器學習和python實戰的比較好的書,可惜我現在才開始練習程式碼!先宣告:本人菜鳥一枚,機器學習的理論知識剛看了一部分,python的知識也沒學很多,所以寫程式碼除錯的過程很痛可!但是還是挨個找出了問題所在,蠻開心的!看了很多大牛
機器學習(四) 分類算法--K近鄰算法 KNN
class 給定 sort sta shape counter 3.5 解釋 sqrt 一、K近鄰算法基礎 KNN------- K近鄰算法--------K-Nearest Neighbors 思想極度簡單 應用數學知識少 (近乎為零) 效果好(缺點?) 可以解
【2】機器學習之兄弟連:K近鄰和K-means
關鍵詞:從K近鄰到最近鄰,監督學習,資料帶lable,效率優化(從線性搜尋到kd樹搜尋),缺點是需要儲存所有資料,空間複雜度大。可以利用kd數來優化k-means演算法。 學習了kNN和K-means演算法後,仔細分析比較了他們之間的異同以及應用場景總結成此文供讀者參
《機器學習系統設計》之k-近鄰分類演算法
前言: 本系列是在作者學習《機器學習系統設計》([美] WilliRichert)過程中的思考與實踐,全書通過Python從資料處理,到特徵工程,再到模型選擇,把機器學習解決問題的過程一一呈現。書中設計的原始碼和資料集已上傳到我的資源:http://downloa
web安全之機器學習入門——3.1 KNN/k近鄰算法
數據收集 完成 整合 ada set acc eat true orm 目錄 sklearn.neighbors.NearestNeighbors 參數/方法 基礎用法 用於監督學習 檢測異常操作(一) 檢測異常操作(二) 檢測rootkit 檢測websh
機器學習-9(資訊熵的簡單介紹)
這一節介紹一下資訊熵,這個跟熱力學的熵是有區別的,所以現在讓我們忘記熱力學第二定律,我們不需要去聯想。在這裡我將按0基礎的思維來討論資訊熵到底是什麼 我們先把基礎公式摘出來 H(X)=−∑xεXP(x)logP(x)) 看公式,我們已經能感受到了,這是離散型的,每個特徵值是獨立
機器學習-10(最優決策樹演算法的實際展示)
網上一大堆的文章,但是他們的介紹並沒有實際上說明為什麼使用最優決策樹,決策樹到底是什麼玩意 我這裡也不做類似的白話文解釋了,直接附圖來詳細生動的例子給大家演示why OK,現在我們先以是否浮出水面來分類 最終結果如圖 ok,經過我們層層的決策,結果如圖
kNN(k近鄰演算法)
K近鄰分析(KNN) 一、概述 KNN演算法是一種有監督學習的分類演算法。所謂有監督學習,就是在應用演算法之前我們必須準備一組訓練集,訓練集中的每個例項都是由一些特徵和一個分類標籤組成;通常還會存在一個測試集,用來測試訓練出來的分類模型的準確性。其實KNN演算法並沒有體現
機器學習基礎——簡單易懂的K鄰近演算法,根據鄰居“找自己”
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天的文章給大家分享機器學習領域非常簡單的模型——KNN,也就是K Nearest Neighbours演算法,翻譯過來很簡單,就是K最近鄰居演算法。這是一個經典的無監督學習的演算法,原理非常直觀,易於理解。 監督與無監督 簡單介紹一下
python學習日記(初識遞迴與演算法)
遞迴函式 定義 遞迴的定義——在一個函式裡再呼叫這個函式本身 遞迴的最大深度——997,即棧溢位。 使用遞迴函式需要注意防止棧溢位。在計算機中,函式呼叫是通過棧(stack)這種資料結構實現的,每當進入一個函式呼叫,棧就會加一層棧幀,每當函式返回,棧就會減一層棧幀。由於棧的大小不
Python3《機器學習實戰》學習筆記(一):k-近鄰演算法
**轉載:**http://blog.csdn.net/c406495762執行平臺: WindowsPython版本: Python3.xIDE: Sublime text3 他的個人網站:http://cuijiahua.com 文章目錄
《機器學習實戰》 筆記(一):K-近鄰演算法
一、K-近鄰演算法 1.1 k-近鄰演算法簡介 簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離的方法進行分類。 1.2 原理 存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一資料 與所屬分類的對應關係。輸入沒有標籤的新資料