3、Spark2x 基於記憶體的計算引擎
Spark2x 基於記憶體的計算引擎
一、Spark 概述
Spark 是一種基於記憶體進行計算的分散式批處理引擎,他的主要工作是執行以下幾種計算:
(1) 資料處理,可以進行快速的資料計算工作,具備容錯性和可拓展性。
(2) 迭代計算,Spark 支援迭代計算,可以對多步資料邏輯處理進行計算工作。(3) 資料探勘,在海量資料基礎上進行挖掘分析,可以支援多種資料探勘和機器學習演算法。
對比於 hadoop 來說,Spark 更適用於資料處理,機器學習,互動式分析,最主要的是迭代計算中,它可以提供比 hadoop 更低的延遲,更高效的處理,並且開發效率更高,容錯性也更好,但是需要注意的是,Spark 的效能只有在進行多層迭代計算的時候才會有顯著的效能提升,相對於迭代層數少的現象,Spark 的計算效能提升的並不明顯,基本和 Hadoop 持平。
Spark 是基於記憶體的分散式批處理引擎,它最大的特點是延遲小,具有很高的容錯性和可拓展性,它和其他引擎的最大的區別在於,它支援進行迭代計算, Spark 主要適用的場景在低延遲的迭代計算中,它和傳統的資料處理引擎最大的不同,在於 Spark 會將計算中的臨時檔案或者臨時資料存放在記憶體中,這樣在進行反覆的引用時,就不需要再從磁碟中進行資料讀取,而是選擇更快的記憶體進行該操作。那麼相比於傳統 Hadoop 架構,Spark 理論速度會高於 Hadoop100 倍以上,但是,這個引數是有條件的,在迭代的層級較少的時候,這個差距並不明顯,還有可能 Spark 的計算速度沒有 hadoop 快,但是當反覆的重複引用和迭代層數多以後,這個差距就會越來越明顯。

(1) SparkCore:類似於 MR 的分散式記憶體計算框架,Core 是整體 Spark 計算的核心程序,上層的計算按照計算的型別進行區分,用於適應不同層面的和不同目的的計算,然後計算的流程和中間處理程序都是由 Core 來進行的計算,所以
本身從原理上來說,Spark 通過各種上層程序,滿足了不同需求的計算,並且進行轉化,下層的 Core 只進行計算,這樣做就可以保證整體的所有元件都正常執行,並且達到資源的利用最大化,最大的特點是將中間計算結果直接放在記憶體中,提升計算效能。自帶了 Standalone 模式的資源管理框架,同時,也支援 YARN、 MESOS 的資源管理系統。FI 整合的是 SparkOnYarn 的模式。其它模式暫不支援。(2) SparkSQL:SparkSQL 是一個用於處理結構化資料的 Spark 元件,作為
Apache Spark 大資料框架的一部分,主要用於結構化資料處理和對資料執行類SQL 查詢。通過 SparkSQL,可以針對不同資料格式(如:JSON,Parquet,ORC 等)
和資料來源執行 ETL 操作(如:HDFS、資料庫等),完成特定的查詢操作。當我們需要對 Sql 進行相關的操作的時候,就像之前所說,首先使用者通過 SQL 語句傳送對應的請求到達 Spark 的 SQL 執行引擎,SQL 執行引擎將我們提交的請求做語義執行,轉化為對應的對資料的操作,之後,將對應的操作和執行處理任務交給 Core 來進行計算。
(3) SparkStreaming :微批處理的流處理引擎,將流資料分片以後用 SparkCore 的計算引擎中進行處理。相對於 Storm,實時性稍差,優勢體現在吞吐量上。
(4) Mllib 和 GraphX 主要一些演算法庫。
(5) FusionInsight Spark 預設執行在 YARN 叢集之上。
(6) Structured Streaming 為 2.0 版本之後的 spark 獨有。它是構建在
SparkSQL 上的計算引擎,其將流式資料理解成為是不斷增加的資料庫表,這種流式的資料處理模型類似於資料塊處理模型,可以把靜態資料庫表的一些查詢操作應用在流式計算中,Spark 執行標準的 SQL 查詢,從無邊界表中獲取資料。
三、SparkCore 技術原理
1.Spark 的流程角色和基本概念
角色基本概念:
(1)Client:使用者方,負責提交請求 Client 和之前的概念一樣,是一個引擎內的程序,提供了對外訪問的介面和對內元件程序的互動。
(2)Driver:負責應用的業務邏輯和執行規劃(DAG)
Driver 是一個新的元件,和之前的處理引擎最大的不同在於,我們處理 Spark 的資料時,由於 Spark 是一個基於記憶體的處理引擎,所以其資料計算時有一個很典型的特點就是迭代化的計算處理,所以我們在具體將任務切分的時候,就不能像之前的處理引擎一樣,只是單純的將任務做切分下發,因為任務和任務之間這次存在了強耦合或者是弱耦合的關聯性關係,而計算的結果又會出現相互的呼叫,也就是結果之間存在有依賴關係,所以我們在處理 Spark 的計算時,就必須對任務的執行過程做一個非常詳細的控制,什麼時候需要做什麼計算,需要呼叫什麼樣的結果,這都是 Driver 需要進行規劃和控制的,所以在我們執行相關的任務之前,Driver 就需要對任務做相關的劃分和處理的順序的控制,將任務的執行規劃整合為 DAG 執行規劃圖來進行下發(DAG:DAG 是一個應用被切分為任務之後的執行的相關處理流程,主要是用來控制任務的執行順序和呼叫的資料,DAG
是一個有向無環圖,也就是說,任務執行是有相關的執行順序的,這就保證了有向,但是任務同時又是一定會執行完畢的,所以無環就保證了任務一定會有終止。)(3)ApplicationMaster:負責應用的資源管理,根據應用需要,向資源管理部門(ResourceManager)申請資源。
這裡說的 AppMaster 和 MR 的有一定的不同,區別如下:
①MR 的 AppMaster 需要負責的功能很多,但是 Spark 的 AppMaster 功能較單一
②MR 的 AppMaster 在建立完成之後需要和 RM 模組進行註冊操作,Spark 的不需要
③在向 RM 申請資源之後,MR 的 AppMaster 需要自己和 NM 通訊要求其拉起
Container,Spark 的不需要,Executor 是由 RM 直接下發建立的。 ④Container 和 Executor 建立完成之後,如果是 MR 的 AppMaster,則會下發 task 到 Container 中,如果是 Spark,則由 driver 下發 task。
⑤如果使用者需要查詢相關的處理進度資訊,MR 的 AppMaster 負責返回執行進度,如果是 Spark,則由 Driver 執行。
⑥執行完成之後 MR 的 AppMaster 需要登出,Spark 的 AppMaster 不需要登出。
⑦如果執行過程中出現故障,那麼 MR 的 AppMaster 負責重新下發 task 執行,在
Spark 中這個工作由 Driver 做。
所以綜上所述,MR 和 Spark 的 AppMaster 最大的區別在於,MR 的 AppMaster 是
一個綜合管理的程序,但是 Spark 中,這個工作就由 Driver 來做,AppMaster 只負責資源的計算和申請操作。Driver 是一個固定程序,MR 的 AppMaster 是一個臨時程序。
(4)ResourceManager:資源管理部門,負責整個叢集資源統一排程和分配。 RM 是 Yarn 中的元件,和 MR 和 Spark 沒關係,這裡兩個引擎只是呼叫了 Yarn 中的 RM,沒有在自身引擎內建立和維護 RM。
(5)Executor:負責實際計算工作,一個應用會分拆給多個 Executor 來進行計算。
Executor 是一個更小化的概念,我們的 AppMaster 在申請的時候,申請的是 Container 容器,然後 RM 將對應的資源做封裝,然後和 NM 進行通訊,要求 NM 啟動 Container,在 Container 中,我們又將資源做了進一步的切分,最終形成一個個的 Executor,所以這裡所說的 Executor 是屬於 Container 的,我們在下發任務時,可以給一個 Executor 中下發多個 task 進行執行。而 Executor 之間的計算又是分散式的。
流程基本概念:
(1)Application:Spark 使用者程式,提交一次應用為一個 Application,一個 App 會啟動一個 SparkContext,也就是 Application 的 Driver,驅動整個 Application 的執行。
我們所做的一個任務就是指提交一個 Application,一個應用中包含的就是對資料所需要執行的計算,以及對計算相關的控制操作,除了這兩部分之外,我們在 Application 中還封裝了相關的執行所需要的一些程序驅動,比如對 Driver 和 AppMaster 的相關配置和處理檔案。那麼在 Application 中我們提交的計算就是一個整體的計算程序。
(2)Job:一個 Application 可能包含多個 Job,每個 action 運算元對應一個 Job; action 運算元有 collect,count 等。
Driver 將一個 Application 中提交的計算程序,切分為執行的幾個計算,比如說使用者下發一個做菜的要求,那麼 Driver 就會將該請求解析切分為洗菜、切菜、炒菜的一步步的 job 來進行執行。
(3)Stage:每個 Job 可能包含多層 Stage,劃分標記為 shuffle 過程;Stage按照依賴關係依次執行。
那麼在每一個 job 子任務中,我們又需要做很多的計算工作,這個時候,我們會檢查當前需要執行的計算中的資料之間的關聯性和相關的執行的耦合度,然後根據資料以及結果之間的依賴關係,將其分為寬依賴和窄依賴,我們從 Driver 一開始分析出的 DAG 圖中,從最末端開始向總結果的方向去執行,一旦在 DAG 中發現出現寬依賴,則將其拆分為窄依賴來進行計算工作,重新規劃 DAG 圖,並認為凡是從開始執行直到遇到寬依賴的中間計算流程,都屬於是一個計算階段。當所有的 job 中不在存在有寬依賴時,我們的計算規劃就保證已經處於是一個最小化計算的,最小化迭代的這麼一個狀態了。那麼我們這個時候就可以將一層一層的迭代計算中所需要執行的每一步操作都封裝為一個 task 然後下發執行了,這個時候整體的計算流程就已經劃分為了 Application—Job—Stage—task
(4)Task:具體執行任務的基本單位,被髮到 executor 上執行。
Task 是整體計算中的最小單位,只有 task 的計算是不存在迭代關係的,但是 task 在執行的時候可能會依賴於某一些其他 task 的計算結果。
2.Spark 的應用執行流程

(1)Client 向 Driver 發起應用計算請求,將 Driver 啟動,並且同時申請 JobID保證全域性應用的唯一合法性。
首先,使用者通過相關的介面連線到 Client,然後提交 Application 應用到 Client, Client 將請求轉發到 Spark,啟動 Driver,Driver 會根據 Application 中的資料和資訊,對任務進行相關的計算工作,然後把 Application 中的計算請求解析,並且拆解,最終成為 DAG 的形式提交,按照如上的基本概念(2)Driver 向 RM 申請 AM,來計算本次的應用資料
Driver 在執行完如上的計算之後,會根據使用者提交的 Application 中關於 AppMaster 的控制檔案和相關資訊,計算其所需要使用資源,然後將請求傳送給RM,請求建立一個 Container,並在其中拉起 AppMaster。
(3)RM 在合適的裝置節點上啟動 AM,來進行應用的調配和控制 RM 在收到請求之後,首先會發送相關的請求到各個 NM,檢查每個 NM 的負載情
況,並且選擇當前負載最小的 NM 節點進行通訊,下發相關的請求給 NM,要求其在自身封裝對應的資源,拉起一個 Container,並在 Container 建立完成之後在其中開啟 AppMaster。
(4)AM 向 RM 申請容器進行資料的計算 AppMaster 拉起之後,會根據 Driver 中記錄 DAG 計算當前執行任務所需要消耗
的資源,然後根據計算的結果向 RM 發起資源的申請請求,這裡的 AppMaster 和 RM 中的相同,會按照輪詢式的請求方法,計算每一步操作所需要消耗的資源,然後逐個下發申請,而不是根據計算所需要消耗的資源總量去進行一次性申請。
(5)RM 選擇合適的節點進行容器的下發,並且在容器上啟動 Executor RM 按照之前的方式,根據負載在 NM 上拉起 Container,並且要求 Container 在
建立完成之後在內部繼續建立 Executor。
(6)Executor 建立完成之後,會向 Driver 進行註冊。保證其合法性。
(7)Driver 會將任務按照 DAG 的執行規劃,一步步的將 Stage 下發到 Executor上進行計算
計算的過程中,資料會根據呼叫的依賴關係,先快取在記憶體中,如果記憶體中的容量不足,我們也需要根據時間戳將最先寫入到記憶體中的部分資料下盤。計算全部結束之後,Executor 就會關閉自身程序,然後 NM 將資源做回收操作。
(8)任務計算完成之後,Driver 會向 RM 程序傳送登出資訊,完成應用的計算,並且向 Client 返回對應的執行結果。
如果在執行的過程中,我們有相關的查詢操作,這個時候,請求會通過 Client 下發給 Driver 進行查詢,如果 Driver 查詢到某一個 task 執行卡住,或者執行的速度過慢,這個時候就會選擇一個 Executor 下發一個相同的任務,那個任務先執行完,就使用哪一個任務的結果,這樣就可以保證在整體執行的時候不會由於某一個程序的執行速度過慢,而導致的整體計算被卡住。
3.RDD 彈性分佈資料集
由於 Driver 整體是將資料切分成了階段去進行執行,那麼 DAG 本身就是一個關於計算執行的控制流程。DAG 主要是用於控制計算的順序和計算的結果呼叫的規劃。那麼在實際進行計算的時候,一個大的資料也就會按照這種 DAG 被切分成了很多小的資料集被反覆呼叫或者根據依賴關係快取。這個時候,這種由階段性計算產生的小的資料集就被稱為 RDD 彈性分散式資料集。
彈性分佈資料集,指的是一個只讀的,可分割槽的分散式資料集。這個資料集的全部或部分可以快取在記憶體,在多次計算之間重用。
(1)RDD 的生成:從 Hadoop 檔案系統(或與 Hadoop 相容的其它儲存系統)輸入建立(如 HDFS)。或者從父 RDD 轉換得到新的 RDD。
在實際的操作中,我們提交業務的時候是按照整體檔案進行的提交,提交進來之後,我們首先在 Duiver 中會進行 Application 到 task 的 DAG 切分,這個時候計算的資料,就由原先的整體檔案被切分為了一個個的 RDD,我們計算的時候是按照 DAG 的執行反向順序進行的建立,由一個大的檔案,也就是量級比較大的父 RDD,逐步的切分為多個子 RDD,直到最終子 RDD 的對應關係可以和 task 進行匹配。

(2)RDD 的儲存和分割槽:使用者可以選擇不同的儲存級別儲存 RDD 以便重用(11種)。當前 RDD 預設儲存於記憶體,但當記憶體不足時,RDD 會溢位到磁碟中。RDD在需要進行分割槽時會根據每條記錄 Key 進行分割槽,以此保證兩個資料集能高效進行 Join 操作。
我們在執行相關的計算時,主要有兩種大類的操作,為 transfermation 和action, 其中 transfermation 執行的操作結果還是一個 RDD,相當於在執行計算的過程中,transfermation 產生的是臨時的資料集,對資料做一些基本的操作和處理。如 map 、filter 、join 等。Transformation 都是 Lazy 的,程式碼呼叫到 Transformation 的時候,並不會馬上執行,需要等到有 Action 操作的時候才會啟動真正的計算過程。 action 產生的是結果,如 count,collect,save 等,Action 操作是返回結果或者將結果寫入儲存的操作。Action 是 Spark 應用真正執行的觸發動作。

RDD 的 11 種儲存級別:
(3)RDD 的優點:RDD 是隻讀的,可提供更高容錯能力。RDD 的不可變性,可以
實現 HadoopMapReduce 的推測式執行。RDD 的資料分割槽特性,可以通過的本地性來提高能。RDD 都是可序列化的,在記憶體不足時自動降級為磁碟儲存。
HadoopMapReduce 推測執行(SpeculativeExecution)(SpeculativeExecution):
是指在分散式叢集環境下,因為負載不均衡或者資源分佈等原造成同一個 job 的個別的個別 task 執行速度明顯慢於其他 task,最終延長整個 Job 的執行時間。為了避免這種情況發生,Hadoop 會為該 task 啟動備份任務,讓該 speculative task 與原始 task 同時處理一份資料,哪個先執行完則將誰的結果作為最終結果,以提高整 Job 的執行時間。
RDD 的特點:失敗自動重建。可以控制儲存級別(記憶體,磁碟等)來進行重用。是靜態型別的。
4.RDD 的寬依賴和窄依賴
RDD 父子依賴關係:
在 RDD 中,我們可以根據某個 RDD 進行操作(計算或者轉換等)得到一個新的RDD,那麼這個 RDD 在執行 Application 類操作的時候是會產生對原 RDD 的依賴關係,那麼此時,原 RDD 成為父 RDD,新的 RDD 為子 RDD。
窄依賴(Narrow)指父 RDD 的每一個分割槽最多被一個子 RDD 的分割槽所用。

寬依賴(Wide)指子 RDD 的分割槽依賴於父 RDD 的所有分割槽,是 Stage 劃分的依據。
(1)窄依賴對優化很有利。邏輯上,每個 RDD 的運算元都是一個 fork/join(此 join 非 join 運算元,而是指同步多個並行任務的 barrier);把計算 fork 到每個分割槽,算完後 join,然後下一個 fork/join。如果直接轉換到物理實現,是很不經濟的:一是每一個 RDD(即使是中間結果)都需要物化到記憶體或儲存中,費時費空間;二是 join 作為全域性的 barrier,是很昂貴的,會被最慢的那個節點拖死。如果子 RDD 的分割槽到父 RDD 的分割槽是窄依賴,就可以把兩個 fork/join 合為一個;如果連續的變換運算元序列都是窄依賴,就可以把很多個 fork/join 併為一個,不但減少了大量的全域性 barrier,而且無需物化很多中間結果 RDD,這將極大地提升效能。Spark 把這個叫做 pipeline 優化。
RDD 的序列化,我們在進行計算時,由於 RDD 之間包括我們執行的計算之間都是有依賴關係的,那麼在進行實際的計算時,也會存在計算的順序。那麼,當記憶體的容量不足時,我們就需要將一部分的 RDD 儲存在硬碟中,這個時候,由於 RDD 存在序列化編號,這樣我們就可以根據編號繼續按順序進行計算操作,而不會導致由於 RDD 沒有編號產生的計算混亂的問題。
(2)窄依賴的優勢:首先,narrow dependencies 可以支援在同一個 cluster node 上以管道形式執行多條命令,例如在執行了 map 後,緊接著執行 filter;其次, 則是從失敗恢復的角度考慮。narrow dependencies 的失敗恢復更有效,因為它只需要重新計算丟失的 parent partition 即可,而且可以並行地在不同節點進行重計算。
(3)Stage 劃分:stage 的劃分是 Spark 作業排程的關鍵一步,它基於 DAG 確定依賴關係,藉此來劃分 stage,將依賴鏈斷開,每個 stage 內部可以並行執行, 整個作業按照 stage 順序依次執行,最終完成整個 Job。實際應用提交的 Job 中 RDD 依賴關係是十分複雜的,依據這些依賴關係來劃分 stage 自然是十分困難的, Spark 此時就利用了前文提到的依賴關係,排程器從 DAG 圖末端出發,逆向遍
歷整個依賴關係鏈,遇到 ShuffleDependency(寬依賴關係的一種叫法)就斷開,遇到 NarrowDependency 就將其加入到當前 stage。stage 中 task 數目由 stage 末端的 RDD 分割槽個數來決定,RDD 轉換是基於分割槽的一種粗粒度計算,一個 stage 執行的結果就是這幾個分割槽構成的 RDD。
整體來說,由於本身我們在提交計算的時候,計算之間就存在有相關的依賴關係,各個計算結果相互進行迭代和呼叫,這也就導致了在轉化為 DAG 的過程中,我們的資料與資料之間,包括計算的臨時結果之間也是存在有相關的呼叫關係的,這樣的話,某一些計算的 RDD 運算元,就會依賴於其之前計算的 RDD,產生了相關的依賴關係,如果某個 RDD 只依賴於一個 RDD 的運算就可以執行自身的計算,那麼我們稱之為叫做窄依賴,如果某一個 RDD 需要多個 RDD 反饋的結果才能夠滿足執行下一步執行的條件,這個時候我們就稱之為 RDD 之間的關係叫做寬依賴。在具體的實際執行過程中窄依賴要遠遠優秀於寬依賴,所以我們需要將寬依賴拆分為窄依賴,這樣就可以提升整體的執行效率,那麼每遇到一個寬依賴之後,我們將其拆分為窄依賴,然後就可以稱之為是一個新的階段,也就是 stage。如圖所示:

在上圖中,我們可以看到計算流程中一共由 4 個 RDD,RDD2/3/4 中有兩個分割槽,所以我們可以發現 RDD2 和 RDD3 之間是具有寬依賴的,那麼我們就需要將寬依賴拆分為窄依賴,如下圖所示:

我們可以發現,在這張圖中,我們其實本質上並沒有拆分原本的寬依賴,而是將執行的階段做了一個劃分,從原理性的角度上來說,依賴問題其實解決的主要就是記憶體的佔用問題,作為 Spark 來說,它利用記憶體作為資料的臨時快取空間的計算方式速度的確很快,但是同時它也造成了對記憶體佔用過大的情況,所以就可以出現這種情況,當寬依賴出現的時候,由於寬依賴的子 RDD 需要依賴的父 RDD 中的所有分割槽,所以一旦有一個分割槽資料的計算卡住就會導致整個 RDD 計算被卡住,但是父 RDD 中計算出的分割槽的資料結果是不會等待所有的分割槽都計算完成才會加入到子 RDD 的,這就導致每當父 RDD 算出一個分割槽資料就會被馬上載入到子 RDD 的所有分割槽。這樣的話,本身計算由於父 RDD 中的某個分割槽卡住無法繼續進行,但是已經計算出的資料卻被複制多份載入到了子 RDD 的所有分割槽,這樣做的話對於記憶體佔用過高,所以我們需要避免這種情況的產生,這個時候我們就通過拆依賴的方式來實現,當拆依賴之後,我們必須等到某個階段執行完成之後才能執行下一階段,如上圖中,我們必須要等待 Stage1 執行完畢,所有的分割槽資料都計算完成才能執行 Stage2,資料也才能被載入到下一個 Stage 中,這樣的話,我們就節約了記憶體,減小了佔用率。這就是拆依賴的原理。

RDD Objects 產生 DAG,然後進入了 DAGScheduler 階段,DAGScheduler 是面向
stage 的高層次的排程器,DAGScheduler 把 DAG 拆分成很多的 tasks,每組的 tasks 都是一個 stage,每當遇到 shuffle 就會產生新的 stage,DAGScheduler
需要記錄那些 RDD 被存入磁碟等物化動作,同時需尋找 task 的最優化排程,例如資料本地性等;DAGScheduler 還要監視因為 shuffle 輸出導致的失敗;DAGScheduler 劃分 stage 後以 TaskSet 為單位把任務交給底層次的可插拔的排程器 TaskScheduler 來處理;一個 TaskScheduler 只為一個 SparkContext 例項服務,TaskScheduler 接受來自 DAGScheduler 傳送過來的分組的任務, DAGScheduler 給 TaskScheduler 傳送任務的時候是以 Stage 為單位來提交的, TaskScheduler 收到任務後負責把任務分發到叢集中 Worker 的 Executor 中去執行,如果某個 task 執行失敗,TaskScheduler 要負責重試;另外如果 TaskScheduler 發現某個 Task 一直未執行完,就可能啟動同樣的任務運行同一個 Task,哪個任務先執行完就用哪個任務的結果。
Spark 的應用排程全部都是由 Driver 來完成的,當一個請求從 Client 傳送到 Driver 中時,Driver 就開始執行相關的排程執行 1.Driver 會根據使用者提交的請求建立 DAG。Driver 主要分為兩個核心程序,一個是 DAG 排程器,主要用來對提交的業務來進行相關的規劃,需要控制對應的 RDD 的依賴關係並且根據該 RDD 的依賴關係做任務的切分,也就相當於是將 Application 切分為 Stage 的過程,切分完成之後,對應的執行控制是由 task 控制器來做的,它需要下發任務,監控任務,並且在任務出現問題的時候重啟或者是重新下發任務。所以 DAG 排程器做的是計算的邏輯控制,task 排程器做的是具體的執行控制。
2.建立完成之後就開始進行排程階段,DAG 的排程器會將 DAG 切分為 task,其實也就相當於將 Application 切分為 task。task 是以組的形式存在的,一個組其實就是一個 stage,stage 中究竟有多少個 task 取決於 stage 中有多少個子 RDD,一個 RDD 對應的就是一個 task。
3.DAG 從 Application 的層級開始逐層向下進行相關的檢查操作,每遇到一個寬依賴就將其切分為窄依賴,然後將對應層級的 RDD 做切分,然後形成一個 stage。4.切分完成之後,DAG 就需要安排具體的執行的順序和操作,其實這裡也就相當於根據 RDD 之間的依賴關係開始做執行的安排。DAG 需要通過相關的規劃執行,保障整體執行的最優化。效率達到最高。
5.DAG 的排程器將任務安排好之後,就會將對應的 stage 分組任務交給 task 排程器去執行,task 排程器收到的執行要求是以 stage 為單位的,裡面會根據 RDD 的個數產生對應多個的 task。
6.task 排程器會將 Stage 中的 task 下發給 worker 中的 Executor 來執行,其實也就相當於是 task 是下發給 container 中的 executor 來執行的。
7.task 排程器會實時的對計算的進度進行監控,當一個計算產生延遲並且長時無法返回對應的結果時,其會選擇一個其他的 Executor 拉起該計算,兩個程序誰先執行完,就使用誰的結果
四、SparkSQL 技術原理
SparkSQL 是 Spark 中基於 SparkCore 的一個計算工具,其將使用者提交的SQL 語句解析成為 RDD,然後交由 SparkCore 執行,這樣做我們就可以在 Spark
中無縫對接 SQL 的語句查詢,執行相關的任務。在 SparkSQL 中,我們使用的資料資源叫做 DataSet 和 DataFrame。具體的解釋下文中將會詳細闡述。
DataSet 是一個由特定域的物件組成的強型別集合,可通過功能或關係操作並行轉換其中的物件。Dataset 是一個新的資料型別。Dataset 與 RDD 高度類似,效能比較好。DataSet 以 Catalyst 邏輯執行計劃表示,並且資料以編碼的二進位制形式儲存,不需要反序列化就可以執行 sort、filter、shuffle 等操作。Dataset 與 RDD 相似, 然而, 並不是使用 Java 序列化或者 Kryo 編碼器來序列化用於處理或者通過網路進行傳輸的物件。 雖然編碼器和標準的序列化都負責將一個物件序列化成位元組,編碼器是動態生成的程式碼,並且使用了一種允許 Spark 去執行許多像 filtering, sorting 以及 hashing 這樣的操作,
不需要將位元組反序列化成物件的格式。
jvm 中儲存的 java 物件可以是序列化的,也可以是反序列化的。序列化的物件是將物件格式化成二進位制流,可以節省記憶體。反序列化則與序列化相對,是沒有進行二進位制格式化,正常儲存在 jvm 中的一般物件。RDD 可以將序列化的二進位制流儲存在 jvm 中,也可以是反序列化的物件儲存在 JVM 中。至於現實使用中是使用哪種方式,則需要視情況而定。例如如果是需要最終儲存到磁碟的,就必須用序列化的物件。如果是中間計算的結果,後期還會繼續使用這個結果,一般都是用反序列化的物件。
本質上來說,RDD 和 DataSet 的區別並不大,他們都屬於是特殊的資料形式,我們講計算引擎在進行計算的時候,必須需要兩個東西,一個是資料,一個是對資料的計算方法,也就是我們需要應用和資料。資料是資訊載體,應用是對資料的操作手段和計算方法。
由於 Spark 是在記憶體中進行計算的一種引擎,所以為了避免對記憶體的過度佔用,我們一般會將資料進行序列化操作,也就是將原本正常的資料轉換成為二進位制表示來進行儲存,這樣做的好處就是節省記憶體,而 SparkCore 可以將源資料進行序列化操作,之後將產生的二進位制資料直接封裝到 RDD 中,當我們需要對其進行計算的時候,再把二進位制資料轉換為正常的資料,這樣就是反序列化操作。Dataset 的優勢就在於,其可以不進行反序列化,SparkSQL 可以直接識別出二進位制資料的含義,這樣節省了大量的計算延遲和轉換開銷。
DataFrame 提供了詳細的結構資訊,使得 Spark SQL 可以清楚地知道該資料集中包含哪些列,每列的名稱和型別各是什麼。DataFrame 多了資料的結構資訊,即 schema。這裡主要對比 Dataset 和 DataFrame,因為 Dataset 和 DataFrame 擁有完全相同的成員函式,區別只是每一行的資料型別不同
DataFrame 也可以叫 Dataset[Row],每一行的型別是 Row,不解析,每一行究竟有哪些欄位,各個欄位又是什麼型別都無從得知,只能用 getAS 方法或者共性中的模式匹配拿出特定欄位。而 Dataset 中,每一行是什麼型別是不一定的,在自定義了 case class 之後可以很自由的獲得每一行的資訊,結合上圖總結出,DataFrame 列資訊明確,行資訊不明確。
由於 DataFrame 帶有 schema 資訊,因此,查詢優化器可以進行有針對性的優化,以提高查詢效率。
DataFrame 在序列化與反序列化時,只需對資料進行序列化,不需要對資料結構進行序列化。
Row:代表關係型操作符的輸出行;類似 Mysql 的行。

由於本身 SparkSQL 就是對接 SQL 指令的下發執行的,所以我們在看DataSet 和 DataFrame 的時候可以按照 SQL 的表格型別來看資料。DataSet 可以對應到 Row 上去理解。而行資料本身只有內容,不包含資料結構,如果需要讓行包含資料結構,就需要我們自己通過 class 的類定義來實現。DataFrame 是站在列結構的角度上來對資料進行劃分的,這個時候 DataFrame 是自身包含列的結構資訊的,所以對於 DataFrame 來說,自身是攜帶資料和屬性的,DataSet自身只有資料,屬性資訊可以通過配置攜帶。
RDD:優點:型別安全,面向物件。缺點:RDD 無論是叢集間的通訊, 還是 IO 操作都需要對物件的結構和資料進行序列化和反序列化。序列化和反序列化的效能開銷大;GC 的效能開銷,頻繁的建立和銷燬物件, 勢必會增加 GC。
DataFrame:優點:自帶 scheme(設計)資訊,降低序列化反序列化開銷。
DataFrame 另一個優點,off-heap : 意味著 JVM 堆以外的記憶體, 這些記憶體直接受作業系統管理(而不是 JVM)。Spark 能夠以二進位制的形式序列化資料(不包括結構)到 off-heap 中, 當要操作資料時, 就直接操作 off-heap 記憶體. 由於 Spark 理解 schema, 所以知道該如何操作。缺點:不是面向物件的;編譯期不安全。
Dataset 的特點:快:大多數場景下,效能優於 RDD;Encoders 優於 Kryo
或者 Java 序列化;避免不必要的格式轉化。型別安全:類似於 RDD,函式儘可能編譯時安全。和 DataFrame,RDD 互相轉化。Dataset 具有 RDD 和 DataFrame的優點,又避免它們的缺點。
五、Spark Structured Streaming 技術原理
1.Spark Structured Streaming 概念
Structured Streaming 是構建在 Spark SQL 引擎上的流式資料處理引擎。可以像使用靜態 RDD 資料那樣編寫流式計算過程。當流資料連續不斷的產生
時,Spark SQL 將會增量的、持續不斷的處理這些資料,並將結果更新到結果集中。
從此處開始,後邊會有很多的元件涉及到流式資料處理。那麼目前在大資料的元件中,有很大的一部分都涉及到了流式資料處理。那麼根據時間的程序,首先出現的是批處理,之後出現了流處理。批處理主要是針對於大量的小檔案進行處理的一種方式。而流處理主要是針對於大型檔案的處理。我們可以做一個想象,比如今天家裡停水了,開啟水龍頭的時候,水斷斷續續的流出,這種可以理解成為是批處理的資料情況,而沒有停水的時候,開啟水龍頭,水流持續流出,這個時候就可以理解為流式資料。而流式資料本身也具有順序性和不可篡改的特性。其也是由很多的小水滴構成的,所以流式資料還是可以被切分成資料塊的。
批處理資料一般來說是針對於大量小檔案的,對資料處理完成之後,比如一個批次的資料處理好,那麼任務就結束了。而對於流處理資料來說,主要有兩種組成方式,一種是少量的大檔案,持續不斷地輸入構成流資料。另一種是業務持續存在,資料持續不斷地從各個來源匯聚輸入到引擎中構成資料流。目前在業務中,分析業務主要場景是流式資料的第一種。而網際網路廠商,比如阿里、騰訊等企業更多的是使用後者。兩種流式資料使用哪一種的本質區別就在於資料的來源,分析業務主要是使用者自身擁有大量的資料。網際網路廠商由於本身資料量產生較小,所以更多的是依託於後者,也就是底層使用者產生資料,網際網路廠商彙總進行分析構成流式資料。
Structured Streaming 的核心是將流式的資料看成一張資料不斷增加的資料庫表,這種流式的資料處理模型類似於資料塊處理模型,可以把靜態資料庫表的一些查詢操作應用在流式計算中,Spark 執行標準的 SQL 查詢,從無邊界表中獲取資料。
無邊界表:新資料不斷到來,舊資料不斷丟棄,實際上是一個連續不斷的結構化資料流。

在這種流程中,已經計算完成的資料被不斷地丟棄,新的資料持續的被加入到資料集的末尾。對於這個資料集來說,是一個無頭無尾的資料集。但是這樣也體現了流式資料的持續性。

Structured Streaming 的計算是按照時間順序為方式來進行計算的。每一條查詢的操作都會產生一個結果集 Result Table。每一個觸發間隔,當新的資料新增到表中,都會最終更新 Result Table。無論何時結果集發生了更新,都能將變化的結果寫入一個外部的儲存系統。
Structured Streaming 在 OutPut 階段可以定義不同的資料寫入方式,有如下 3 種:
(1) Complete Mode:整個更新的結果集都會寫入外部儲存。整張表的寫入操作將由外部儲存系統的聯結器完成。
(2) Append Mode:當時間間隔觸發時,只有在 Result Table 中新增加的資料行會被寫入外部儲存。這種方式只適用於結果集中已經存在的內容不希望發生改變的情況下,如果已經存在的資料會被更新,不適合適用此種方式。
(3) Update Mode:當時間間隔觸發時,只有在 Result Table 中被更新的資料才會被寫入外部儲存系統。注意,和 Complete Mode 方式的不同之處是不更新的結果集不會寫入外部儲存。
三種模式的具體操作如下圖所示,每種操作模式分別對應每一個時間的輸入和輸出操作:

六、Spark Streaming 技術原理
Spark Streaming 計算基於 DStream,將流式計算分解成一系列短小的批處理作業。

Spark Streaming 本質仍是基於 RDD 計算,當 RDD 的某些 partition 丟失,可以通過 RDD 的血統機制重新恢復丟失的 RDD。

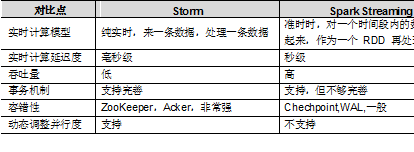
事實上,Spark Streaming 絕對談不上比 Storm 優秀。這兩個框架在實時計算領域中,都很優秀,只是擅長的細分場景並不相同。Spark Streaming 僅僅在吞吐量上比 Storm 要優秀。對於 Storm 來說:
1、建議在那種需要純實時,不能忍受 1 秒以上延遲的場景下使用,比如實時金融系統,要求純實時進行金融交易和分析。2、如果對於實時計算的功能中,要求可靠的事務機制和可靠性機制,即資料的處理完全精準,一條也不能多,一條也不能少,也可以考慮使用 Storm。3、如果還需要針對高峰低峰時間段,動態調整實時計算程式的並行度,以最大限度利用叢集資源(通常是在小型公司,叢集資源緊張的情況),也可以考慮用Storm。
4、如果一個大資料應用系統,它就是純粹的實時計算,不需要在中間執行 SQL 互動式查詢、複雜的 transformation 運算元等,那麼用 Storm 是比較好的選擇。對於 Spark Streaming 來說:
1、如果對上述適用於 Storm 的三點,一條都不滿足的實時場景,即,不要求純實時,不要求強大可靠的事務機制,不要求動態調整並行度,那麼可以考慮使用Spark Streaming。
2、位於 Spark 生態技術棧中,因此 Spark Streaming 可以和 Spark Core、Spark SQL 無縫整合,也就意味著,我們可以對實時處理出來的中間資料,立即在程式中無縫進行延遲批處理、互動式查詢等操作。這個特點大大增強了 Spark Streaming 的優勢和功能。