
輕量級記憶體計算引擎
記憶體計算指資料事先儲存於記憶體,各步驟中間結果不落硬碟的計算方式,適合效能要求較高,併發較大的情況。
HANA、TimesTen等記憶體資料庫可實現記憶體計算,但這類產品價格昂貴結構複雜實施困難,總體擁有成本較高。本文介紹的集算器同樣可實現記憶體計算,而且結構簡單實施方便,是一種輕量級記憶體計算引擎。
下面就來介紹一下集算器實現記憶體計算的一般過程。
一、 啟動伺服器
集算器有兩種部署方式:獨立部署、內嵌部署,區別首先在於啟動方式有所不同。
l 獨立部署
作為獨立服務部署時,集算器與應用系統分別使用不同的JVM,兩者可以部署在同一臺機器上,也可分別部署。應用系統通常使用集算器驅動(ODBC或JDBC)訪問集算服務,也可通過HTTP訪問。
n Windows下啟動獨立服務,執行“安裝目錄\esProc\bin\esprocs.exe”,然後點選“啟動”按鈕。
n Linux下應執行“安裝目錄/esProc/bin/ServerConsole.sh”。
啟動伺服器及配置引數的細節,請參考:
l 內嵌部署
作為內嵌服務部署時,集算器只能與JAVA應用系統整合,兩者共享JVM。應用系統通過JDBC訪問內嵌的集算服務,無需特意啟動。
詳情參考http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html。
二、 載入資料
載入資料是指通過集算器指令碼,將資料庫、日誌、WebService等外部資料讀入記憶體的過程。
比如Oracle中訂單表如下:
| 訂單ID(key) |
客戶ID |
訂單日期 |
運貨費 |
| 10248 |
VINET |
2012-07-04 |
32.38 |
| 10249 |
TOMSP |
2012-07-05 |
11.61 |
| 10250 |
HANAR |
2012-07-08 |
65.83 |
| 10251 |
VICTE |
2012-07-08 |
41.34 |
| 10252 |
SUPRD |
2012-07-09 |
51.3 |
| … |
… |
… |
… |
訂單明細如下:
| 訂單ID(key)(fk) |
產品ID(key) |
單價 |
數量 |
| 10248 |
17 |
14 |
12 |
| 10248 |
42 |
9 |
10 |
| 10248 |
72 |
34 |
5 |
| 10249 |
14 |
18 |
9 |
| 10249 |
51 |
42 |
40 |
| … |
… |
… |
… |
將上述兩張表載入到記憶體,可以使用下面的集算器指令碼(initData.dfx):
| A |
|
| 1 |
=connect("orcl") |
| 2 |
=A1.query("select 訂單ID,客戶ID,訂單日期,運貨費 from 訂單").keys(訂單ID) |
| 3 |
=A1.query@x("select 訂單ID,產品ID,單價,數量 from 訂單明細") .keys(訂單ID,產品ID) |
| 4 |
=env(訂單,A2) |
| 5 |
=env(訂單明細,A3) |
A1:連線Oracle資料庫。
A2-A3:執行SQL查詢,分別取出訂單表和訂單明細表。query@x表示執行SQL後關閉連線。函式keys可建立主鍵,如果資料庫已定義主鍵,則無需使用該函式。
A4-A5:將兩張表常駐記憶體,分別命名為訂單和訂單明細,以便將來在業務計算時引用。函式env的作用是設定/釋放全域性共享變數,以便在同一個JVM下被其他演算法引用,這裡將記憶體表設為全域性變數,也就是將全表資料儲存在記憶體中,供其他演算法使用,也就實現了記憶體計算。事實上,對於外存表、檔案控制代碼等資源也可以用這個辦法設為全域性變數,使變數駐留在記憶體中。
指令碼需要執行才能生效。
對於內嵌部署的集算服務,通常在應用系統啟動時執行指令碼。如果應用系統是JAVA程式,可以在程式中通過JDBC執行initData.dfx,關鍵程式碼如下:
| 1. com.esproc.jdbc.InternalConnection con=null; 2. try { 3. Class.forName("com.esproc.jdbc.InternalDriver"); 4. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://"); 5. ResultSet rs = con.executeQuery("call initData()"); 6. } catch (SQLException e){ 7. out.println(e); 8. }finally{ 9. if (con!=null) con.close(); 10. } |
這篇文章詳細介紹了JAVA呼叫集算器的過程http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html
如果應用系統是JAVA WebServer,那麼需要編寫一個Servlet,在Servlet的init方法中通過JDBC執行initData.dfx,同時將該servlet設定為啟動類,並在web.xml裡進行如下配置:
| <servlet> |
對於獨立部署的集算伺服器,JAVA應用系統同樣要用JDBC介面執行集算器指令碼,用法與內嵌服務類似。區別在於指令碼存放於遠端,所以需要像下面這樣指定伺服器地址和埠:
| st = con.createStatement(); st.executeQuery("=callx(\“initData.dfx\”;[\“127.0.0.1:8281\”])"); |
如果應用系統非JAVA架構,則應當使用ODBC執行集算器指令碼,詳見http://doc.raqsoft.com.cn/esproc/tutorial/odbcbushu.html
對於獨立部署的伺服器,也可以脫離應用程式,在命令列手工執行initData.dfx。這種情況下需要再寫一個指令碼(如runOnServer.dfx):
| A |
|
| 1 |
=callx(“initData.dfx”;[“127.0.0.1:8281”]) |
然後在命令列用esprocx.exe呼叫runOnServer.dfx:
| D:\raqsoft64\esProc\bin>esprocx runOnServer.dfx |
Linux下用法類似,參考http://doc.raqsoft.com.cn/esproc/tutorial/minglinghang.html
三、 執行運算獲得結果
資料載入到記憶體之後,就可以編寫各種演算法進行訪問,執行計算並獲得結果,下面舉例說明:以客戶ID為引數,統計該客戶每年每月的訂單數量。
該演算法對應的Oracle中的SQL語句如下:
| select to_char(訂單日期,'yyyy') AS 年份,to_char(訂單日期,'MM') AS 月份, count(1) AS 訂單數量 from 訂單 where客戶ID=? group by to_char(訂單日期,'yyyy'),to_char(訂單日期,'MM') |
在集算器中,應當編寫如下業務演算法(algorithm_1.dfx)
| A |
|
| 1 |
=訂單.select@m(客戶ID==pCustID).groups(year(訂單日期):年份, month(訂單日期):月份;count(1):訂單數量) |
為方便除錯和維護,也可以分步驟編寫:
| A |
|
| 1 |
=訂單.select@m(客戶ID==pCustID) |
| 2 |
=A1.groups(year(訂單日期):年份, month(訂單日期):月份; count(1):訂單數量) |
A1:按客戶ID過濾資料。其中,“訂單”就是載入資料時定義的全域性變數,pCustID是外部引數,用於指定需要統計的客戶ID,函式select執行查詢。@m表示平行計算,可顯著提高效能。
A2:執行分組彙總,輸出計算結果。集算器預設返回有表示式的最後一個單元格,也就是A2。如果要返回指定單元的值,可以用return語句
當pCustID=”VINET”時,計算結果如下:
| 年份 |
月份 |
訂單數量 |
| 2012 |
7 |
3 |
| 2012 |
8 |
2 |
| 2012 |
9 |
1 |
| 2013 |
11 |
4 |
需要注意的是,假如多個業務計算都要對客戶ID進行查詢,那不妨在載入資料時把訂單按客戶ID排序,這樣後續業務演算法中就可以使用二分法進行快速查詢,也就是使用select@b函式。具體實現上,initData.dfx中SQL應當改成:
| =A1.query("select 訂單ID,客戶ID,訂單日期,運貨費 from 訂單 order by 客戶ID") |
相應的,algorithm_1.dfx中的查詢應當改成:
| =訂單.select@b(客戶ID==pCustID) |
執行指令碼獲得結果的方法,前面已經提過,下面重點說說報表,這類最常用的應用程式。
由於報表工具都有視覺化設計介面,所以無需用JAVA程式碼呼叫集算器,只需將資料來源配置為指向集算服務,在報表工具中以儲存過程的形式呼叫集算器指令碼。
對於內嵌部署的集算伺服器,呼叫語句如下:
| call algorithm_1(”VINET”) |
由於本例中演算法非常簡單,所以事實上可以不用編寫獨立的dfx指令碼,而是在報表中直接以SQL方式書寫表示式:
| =訂單.select@m(客戶ID==”VINET”).groups(year(訂單日期):年份, month(訂單日期):月份;count(1):訂單數量) |
對於獨立部署的集算伺服器,遠端呼叫語句如下:
| =callx(“algorithm_1.dfx”,”VINET”;[“127.0.0.1:8281”]) |
有時,需要在記憶體進行的業務演算法較少,而web.xml不方便新增啟動類,這時可以在業務演算法中呼叫初始化指令碼,達到自動初始化的效果,同時也省去編寫servlet的過程。具體指令碼如下:
| A |
B |
|
| 1 |
if !ifv(訂單) |
=call("initData.dfx") |
| 2 |
=訂單.select@m(客戶ID==pCustID) |
|
| 3 |
=A2.groups(year(訂單日期):年份, month(訂單日期):月份; count(1):訂單數量) |
A1-B1:判斷是否存在全域性變數“訂單明細”,如果不存在,則執行初始化資料指令碼initData.dfx。
A2-A3:繼續執行原演算法。
四、 引用思維
前面例子用到了select函式,這個函式的作用與SQL的where語句類似,都可進行條件查詢,但兩者的底層原理大不相同。where語句每次都會複製一遍資料,生成新的結果集;而select函式只是引用原來的記錄指標,並不會複製資料。以按客戶查詢訂單為例,引用和複製的區別如下圖所示:
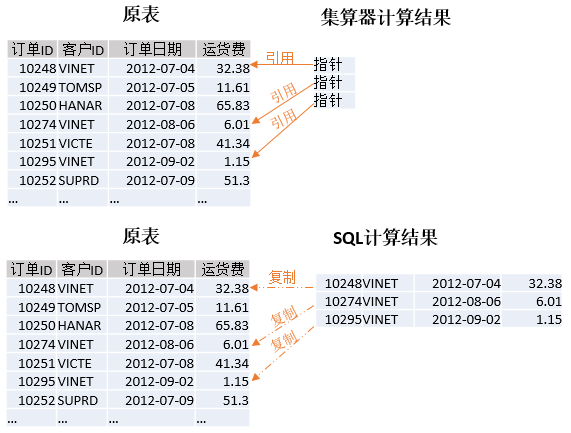
可以看到,集算器由於採用了引用機制,所以計算結果佔用空間更小,計算效能更高(分配記憶體更快)。此外,對於上述計算結果還可再次進行查詢,集算器中新結果集同樣引用最初的記錄,而SQL就要複製出很多新記錄。
除了查詢之外,還有很多集算器演算法都採用了引用思維,比如排序、集合交併補、關聯、歸併。
五、 常用計算
回顧前面案例,可以看到集算器語句和SQL語句存在如下的對應關係:
| 計算 |
SQL |
集算器 |
| 查詢 |
select |
select |
| 條件 |
Where….訂單.客戶ID=? |
訂單ID.客戶ID==pCustID |
| 分組彙總 |
group by |
groups
|
| 日期函式 |
to_char(訂單日期,'yyyy') |
year(訂單日期) |
| 別名 |
AS 年份 |
:年份 |
事實上,集算器支援完善的結構化資料演算法,比如:
l GROUP BY…HAVING
| A |
||
| 1 |
=訂單.groups(year(訂單日期):年份;count(1):訂單數量).select(訂單數量>300) |
| A |
||
| 1 |
=訂單.sort(客戶ID,-訂單日期) |
/排序只是變換了記錄指標的次序,並沒有複製記錄 |
| A |
||
| 1 |
=訂單.id(year(訂單日期)) |
/取唯一值 |
| 2 |
=A1.(客戶ID) |
/所有出現值 |
| 3 |
=訂單.([ year(訂單日期),客戶ID]) |
/組合的所有出現值 |
l UNION/UNION ALL/INTERSECT/MINUS
| A |
||
| 1 |
=訂單.select(運貨費>100) |
|
| 2 |
=訂單.select([2011,2012].pos(year(訂單日期)) |
|
| 3 |
=A2|A3 |
/UNION ALL |
| 4 |
=A2&A3 |
/UNION |
| 5 |
=A2^A3 |
/INTERSECTION |
| 6 |
=A2\A3 |
/DIFFERENCE |
與SQL的交併補不同,集算器只是組合記錄指標,並不會複製記錄。
l SELECT … FROM (SELECT …)
| A |
||
| 1 |
=訂單.select(訂單日期>date("2010-01-01")) |
/執行查詢 |
| 2 |
=A1.count() |
/對結果集再統計 |
| A |
||
| 1 |
=訂單.new(訂單ID,客戶.select(客戶ID==訂單.客戶ID).客戶名) |
/客戶表和訂單表都是全域性變數 |
遊標有兩種用法,其一是外部JAVA程式呼叫集算器,集算器返回遊標,比如下面指令碼:
| A |
||
| 1 |
=訂單.select(訂單日期>=date("2010-01-01")).cursor() |
JAVA獲得遊標後可繼續處理,與JDBC訪問遊標的方法相同。
其二,在集算器內部使用遊標,遍歷並完成計算。比如下面指令碼:
| A |
B |
|||
| 1 |
=訂單.cursor() |
|||
| 2 |
for A1,100 |
=A2.select(訂單日期>=date("2010-01-01")) |
/每次取100條運算 |
|
| 3 |
… |
集算器適合解決複雜業務邏輯的計算,但考慮到簡單算法佔大多數,而很多程式設計師習慣使用SQL語句,所以集算器也支援所謂“簡單SQL”的語法。比如algorithm_1.dfx也可寫作:
| A |
|
| 1 |
$() select year(訂單日期) AS 年份,month(訂單日期) AS 月份,count(1) AS 訂單數量 From {訂單} where訂單.客戶ID='VINET' group by year(訂單日期),month(訂單日期) |
上述指令碼通用於任意SQL,$()表示執行預設資料來源(集算器)的SQL語句,如果指定資料來源名稱比如$(orcl),則可以執行相應資料庫(資料來源名稱是orcl的Oracle資料庫)的SQL語句。
from {}語句可從任意集算器表示式取數,比如:from {訂單.groups(year(訂單日期):年份;count(1):訂單數量)}
from 也可從檔案或excel取數,比如:from d:/emp.xlsx
簡單SQL同樣支援join…on…語句,但由於SQL語句(指任意RDB)在關聯演算法上效能較差,因此不建議輕易使用。對於關聯運算,集算器有專門的高效能實現方法,後續章節會有介紹。
簡單SQL的詳情可以參考:http://doc.raqsoft.com.cn/esproc/func/dbquerysql.html#db_sql_
六、 有序引用
SQL基於無序集合做運算,不能直接用序號取數,只能臨時生成序號,效率低且用法繁瑣。集算器與SQL體系不同,能夠基於有序集合運算,可以直接用序號取數。例如:
| A |
||
| 1 |
=訂單.sort(訂單日期) |
/如果載入時已排序,這步可省略 |
| 2 |
=A1.m(1).訂單ID |
/第一條 |
| 3 |
=A1.m(-1).訂單ID |
/最後一條 |
| 4 |
=A1.m(to(3,5)) |
/第3-5條 |
函式m()可按指定序號獲取成員,引數為負表示倒序。引數也可以是集合,比如m([3,4,5])。而利用函式to()可按起止序號生成集合,to(3,5)=[3,4,5]。
前面例子提到過二分法查詢select@b,其實已經利用了集算器有序訪問的特點。
有時候我們想取前 N名,常規的思路就是先排序,再按位置取前N個成員,集算器指令碼如下:
| =訂單.sort(訂單日期).m(to(100)) |
對應SQL寫法如下:
| select top(100) * from 訂單 order by 訂單日期 --MSSQL select * from (select * from 訂單 order by 訂單日期) where rownum<=100 --Oracle |
但上述常規思路要對資料集大排序,運算效率很低。除了常規思路,集算器還有更高效的實現方法:使用函式top。
| =訂單.top(100;訂單日期) |
函式top只排序出訂單日期最早的N條記錄,然後中斷排序立刻返回,而不是常規思路那樣進行全量排序。由於底層模型的限制,SQL不支援這種高效能演算法。
函式top還可應用於計算列,比如擬對訂單採取新的運貨費規則,求新規則下運貨費最大的前100條訂單,而新規則是:如果原運貨費大於等於1000,則運貨費打八折。
集算器指令碼為:
| =訂單.top(-100;if(運貨費>=1000,運貨費*0.8,運貨費)) |
七、 關聯計算
關聯計算是關係型資料庫的核心演算法,在記憶體計算中應用廣泛,比如:統計每年每月的訂單數量和訂單金額。
該演算法對應Oracle的SQL語句為:
| select to_char(訂單.訂單日期,'yyyy') AS 年份,to_char(訂單.訂單日期,'MM') AS 月份,sum(訂單明細.單價*訂單明細.數量) AS 銷售金額,count(1) AS 訂單數量 from 訂單明細 left join 訂單 on 訂單明細.訂單ID=訂單.訂單ID group by to_char(訂單.訂單日期,'yyyy'),to_char(訂單.訂單日期,'MM') |
用集算器實現上述演算法時,載入資料的指令碼不變,業務演算法如下(algorithm_2.dfx)
| A |
|
| 1 |
=join(訂單明細:子表,訂單ID;訂單:主表,訂單ID) |
| 2 |
=A1.groups(year(主表.訂單日期):年份, month(主表.訂單日期):月份; sum(子表.單價*子表.數量):銷售金額, count(1):訂單數量) |
A1:將訂單明細與訂單關聯起來,子表主表為別名,點選單元格可見結果如下
可以看到,集算器join函式與SQL join語句雖然作用一樣,但結構原理大不相同。函式join關聯形成的結果,其欄位值不是原子資料型別,而是記錄,後續可用“.”號表達關係引用,多層關聯非常方便。
A2:分組彙總。
計算結果如下:
| 年份 |
月份 |
銷售金額 |
訂單數量 |
| 2012 |
7 |
28988 |
57 |
| 2012 |
8 |
26799 |
71 |
| 2012 |
9 |
27201 |
57 |
| 2012 |
10 |
37793.7 |
69 |
| 2012 |
11 |
49704 |
66 |
| … |
… |
… |
… |
關聯關係分很多類,上述訂單和訂單明細屬於其中一類:主子關聯。針對主子關聯,只需在載入資料時各自按關聯欄位排序,業務演算法中就可用歸併演算法來提高效能。例如:
| =join@m(訂單明細:子表,訂單ID;訂單:主表,訂單ID) |
函式join@m表示歸併關聯,只對同序的兩個或多個表有效。
集算器的關聯計算與RDB不同,RDR對所有型別的關聯關係都採用相同的演算法,無法進行有針對性的優化,而集算器採取分而治之的理念,對不同型別的關聯關係提供了不同的演算法,可進行有針對性的透明優化。
除了主子關聯,最常用的就是外來鍵關聯,常用的外來鍵表(或字典表)有分類、地區、城市、員工、客戶等。對於外來鍵關聯,集算器也有相應的優化方法,即在資料載入階段事先建立關聯,如此一來業務演算法就不必臨時關聯,效能因此提高,併發時效果尤為明顯。另外,集算器用指標建立外來鍵關聯,訪問速度更快。
比如這個案例:訂單表的客戶ID欄位是外來鍵,對應客戶表(客戶ID、客戶名稱、地區、城市),需要統計出每個地區每個城市的訂單數量。
資料載入指令碼(initData_3.dfx)如下:
| A |
|
| 1 |
=connect("orcl") |
| 2 |
=A1.query("select 訂單ID,客戶ID,訂單日期,運貨費 from 訂單").keys(訂單ID) |
| 3 |
=A1.query@x(“select 客戶ID,地區,城市 from 客戶”).keys(客戶ID) |
| 4 |
=A2.switch(客戶ID,A3:客戶ID) |
| 5 |
=env(訂單,A2) |
| 6 |
=env(客戶,A3) |
A4:用函式switch建立外來鍵關聯,將訂單表的客戶ID欄位,替換為客戶表相應記錄的指標。
業務演算法指令碼如下(algorithm_3.dfx)如下
| A |
|
| 1 |
=訂單.groups(客戶ID.地區:地區 ,客戶ID.城市:城市;count(1):訂單數量) |
載入資料時已經建立了外來鍵指標關聯,所以A1中的“客戶ID”表示:訂單表的客戶ID欄位所指向的客戶表記錄,“客戶ID.地區”即客戶表的地區欄位。
指令碼中多處使用“.”號表達關聯引用,語法比SQL直觀易懂,遇到多表多層關聯時尤為便捷。而在SQL中,關聯一多如同天書。
上述計算結果如下:
| 地區 |
城市 |
訂單數量 |
| 東北 |
大連 |
40 |
| 華東 |
南京 |
89 |
| 華東 |
南昌 |
15 |
| 華東 |
常州 |
35 |
| 華東 |
溫州 |
18 |
| … |
… |
… |
八、 內外混合計算
記憶體計算雖然快,但是記憶體有限,因此通常只駐留最常用、併發訪問最多的資料,而記憶體放不下或訪問頻率低的資料,還是要留在硬碟,用到的時候再臨時載入,並與記憶體資料共同參與計算。這就是所謂的內外混合計算。
下面舉例說明集算器中的內外混合計算。
案例描述:某零售行業系統中,訂單明細訪問頻率較低,資料量較大,沒必要也沒辦法常駐記憶體。現在要將訂單明細與記憶體裡的訂單關聯起來,統計出每年每種產品的銷售數量。
資料載入指令碼(initData_4.dfx)如下:
| A |
|
| 1 |
=connect("orcl") |
| 2 |
=A1.query@x("select 訂單ID,客戶ID,訂單日期,運貨費 from 訂單 order by 訂單ID").keys(訂單ID) |
| 4 |
=env(訂單,A2) |
業務演算法指令碼(algorithm_4.dfx)如下:
| A |
|
| 1 |
=connect("orcl") |
| 2 |
=A1.cursor@x("select 訂單ID,產品ID,數量 from 訂單明細order by 訂單ID") |
| 3 |
=訂單.cursor() |
| 4 |
=joinx(A2:子表,訂單ID; A3:主表,訂單ID) |
| 5 |
=A4.groups(year(主表.訂單日期):年份,子表.產品ID:產品 ;sum(子表.數量):銷售數量) |
A2:執行SQL,以遊標方式取訂單明細,以便計算遠超記憶體的大量資料。
A3:將訂單錶轉為遊標模式,下一步會用到。
A4:關聯訂單明細表和訂單表。函式joinx與join@m作用類似,都可對有序資料進行歸併關聯,區別在於前者對遊標有效,後者對序表有效。
A5:執行分組彙總。
九、 資料更新
資料庫中的物理表總會變化,這種變化應當及時反映到共享的記憶體表中,才能保證記憶體計算結果的正確,這種情況下就需要更新記憶體。如果物理表較小,那麼解決起來很容易,只要定時執行初始化資料指令碼(initData.dfx)就可以了。但如果物理表太大,就不能這樣做了,因為初始化指令碼會進行全量載入,本身就會消耗大量時間,而且載入時無法進行記憶體計算。例如:某零售巨頭訂單資料量較大,從資料庫全量載入到記憶體通常超過5分鐘,但為保證一定的實時性,記憶體資料又需要5分鐘更新一次,顯然,兩者存在明顯的矛盾。
解決思路其實很自然,物理表太大的時候,應該進行增量更新,5分鐘的增量業務資料通常很小,增量不會影響更新記憶體的效率。
要實現增量更新,就需要知道哪些是增量資料,不外乎以下三種方法:
方法A:在原表加標記欄位以識別。缺點是會改動原表。
方法B:在原庫建立一張“變更表”,將變更的資料記錄在內。好處是不動原表,缺點是仍然要動資料庫。
方法C:將變更表記錄在另一個數據庫,或文字檔案Excel中。好處是對原資料庫不做任何改動,缺點是增加了維護工作量。
集算器支援多資料來源計算,所以方法B、C沒本質區別,下面就以B為例更新訂單表。
第一步,在資料庫中建立“訂單變更表”,繼承原表字段,新加一個“變更標記”欄位,當用戶修改原始表時,需要在變更表同步記錄。如下所示的訂單變更表,表示新增1條修改2條刪除1條。
| 訂單ID(key) |
客戶ID |
訂單日期 |
運貨費 |
變更標記 |
| 10247 |
VICTE |
2012-07-08 |
101 |
新增 |
| 10248 |
VINET |
2012-07-04 |
102 |
修改 |
| 10249 |
TOMSP |
2012-07-05 |
103 |
修改 |
| 10250 |
HANAR |
2012-07-08 |
104 |
刪除 |
第二步,編寫集算器指令碼updatemem_4.dfx,進行資料更新。
| A |
B |
|
| 1 |
=connect("orcl") |
|
| 2 |
=訂單cp=訂單.derive() |
|
| 3 |
=A1.query("select 訂單ID,客戶ID,訂購日期 訂單日期,運貨費,變更標記 from 訂單變更") |
|
| 4 |
=訂單刪除=A3.select(變更標記=="刪除") |
=訂單cp.select(訂單刪除.(訂單ID).contain(訂單ID)) |
| 5 |
=訂單cp.delete(B4) |
|
| 6 |
=訂單新增=A3.select(變更標記=="新增") |
=訂單cp.insert@f(0:訂單新增) |
| 7 |
=訂單修改=A3.select(變更標記=="修改") |
=訂單cp.select(訂單修改.(訂單ID).pos(訂單ID)) |
| 8 |
=訂單cp.delete(B7) |
|
| 9 |
=訂單cp.insert@f(0:訂單修改) |
|
| 10 |
=env(訂單,訂單cp) |
|
| 11 |
=A1.execute("delete from 訂單變更") |
|
| 12 |
=A1.close() |
A1:建立資料庫連線。
A2:將記憶體中的訂單複製一份,命名為訂單cp。下面過程只針對訂單cp進行修改,修改完畢再替代記憶體中的訂單,期間訂單仍可正常進行業務計算。
A3:取資料庫訂單變更表。
A4-B5:取出訂單變更表中需刪除的記錄,在訂單cp中找到這些記錄,並刪除。
A6-B6:取出訂單變更表中需新增的記錄,在訂單cp中追加。
A7-B9:這一步是修改訂單cp,相當於先刪除再追加。也可用modify函式實現修改。
A10:將修改後的訂單cp常駐記憶體,命名為訂單。
A11-A12:清空“變更表”,以便下次取新的變更記錄。
上述指令碼實現了完整的資料更新,而實際上很多情況下只需要追加資料,這樣指令碼還會簡單很多。
指令碼編寫完成後,還需第三步:定時5分鐘執行該指令碼。
定時執行的方法有很多。如果集算器部署為獨立服務,與Web應用沒有共用JVM,那麼可以使用作業系統自帶的定時工具(計劃任務或crontab),使其定時執行集算器命令(esprocx.exe或esprocx.sh)。
有些web應用有自己的定時任務管理工具,可定時執行某個JAVA類,這時可以編寫JAVA類,用JDBC呼叫集算器指令碼。
如果web應用沒有定時任務管理工具,那就需要手工實現定時任務,即編寫JAVA類,繼承java內建的定時類TimerTask,在其中呼叫集算器指令碼,再在啟動類中呼叫定時任務類。
其中啟動類myServle4為:
1. import java.io.IOException;
2. import java.util.Timer;
3. import javax.servlet.RequestDispatcher;
4. import javax.servlet.ServletContext;
5. import javax.servlet.ServletException;
6. import javax.servlet.http.HttpServlet;
7. import javax.servlet.http.HttpServletRequest;
8. import javax.servlet.http.HttpServletResponse;
9. import org.apache.commons.lang.StringUtils;
10. public class myServlet4 extends HttpServlet {
11. private static final long serialVersionUID = 1L;
12. private Timer timer1 = null;
13. private Task task1;
14. public ConvergeDataServlet() {
15. super();
16. }
17. public void destroy() {
18. super.destroy();
19. if(timer1!=null){
20. timer1.cancel();
21. }
22. }
23. public void doGet(HttpServletRequest request, HttpServletResponse response)
24. throws ServletException, IOException {
25. }
26. public void doPost(HttpServletRequest request, HttpServletResponse response)
27. throws ServletException, IOException {
28. doGet(request, response);
29. }
30. public void init() throws ServletException {
31. ServletContext context = getServletContext();
32. // 定時重新整理時間(5分鐘)
33. Long delay = new Long(5);
34. // 啟動定時器
35. timer1 = new Timer(true);
36. task1 = new Task(context);
37. timer1.schedule(task1, delay * 60 * 1000, delay * 60 * 1000);
38. }
39. }
定時任務類Task為:
11. import java.util.TimerTask;
12. import javax.servlet.ServletContext;
13. import java.sql.*;
14. import com.esproc.jdbc.*;
15. public class Task extends TimerTask{
16. private ServletContext context;
17. private static boolean isRunning = true;
18. public Task(ServletContext context){
19. this.context = context;
20. }
21. @Override
22. public void run() {
23. if(!isRunning){
24. com.esproc.jdbc.InternalConnection con=null;
25. try {
26. Class.forName("com.esproc.jdbc.InternalDriver");
27. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://");
28. ResultSet rs = con.executeQuery("call updatemem_4()");
29. }
30. catch (SQLException e){
31. out.println(e);
32. }finally{
33. //關閉資料集
34. if (con!=null) con.close();
35. }
36. }
37. }
38. }
十、 綜合示例
下面,通過一個綜合示例來看一下在資料來源多樣、演算法複雜的情況下,集算器如何很好地實現記憶體計算:
案例描述:某B2C網站需要試算訂單的郵寄總費用,以便在一定成本下挑選合適的郵費規則。大部分情況下,郵費由包裹的總重量決定,但當訂單的價格超過指定值時(比如300美元),則提供免費付運。結果需輸出各訂單郵寄費用以及總費用。
其中訂單表已載入到記憶體,如下:
| Id |
cost |
weight |
| Josh1 |
150 |
6 |
| Drake |
100 |
3 |
| Megan |
100 |
1 |
| Josh2 |
200 |
3 |
| Josh3 |
500 |
1 |
郵費規則每次試算時都不同,因此由引數“pRule”臨時傳入,格式為json字串,某次規則如下:
| [{"field":"cost","minVal":300,"maxVal":1000000,"Charge":0}, {"field":"weight","minVal":0,"maxVal":1,"Charge":10}, {"field":"weight","minVal":1,"maxVal":5,"Charge":20}, {"field":"weight","minVal":5,"maxVal":10,"Charge":25}, {"field":"weight","minVal":10,"maxVal":1000000,"Charge":40}] |
上述json串表示各欄位在各種取值範圍內時的郵費。第一條記錄表示,cost欄位取值在300與1000000之間的時候,郵費為0(免費付運);第二條記錄表示,weight欄位取值在0到1(kg)之間時,郵費為10(美元)。
思路:將json串轉為二維表,分別找出filed欄位為cost和weight的記錄,再對整個訂單表進行迴圈。迴圈中先判斷訂單記錄中的cost值是否滿足免費標準,不滿足則根據重量判斷郵費檔次,之後計算郵費。算完各訂單郵費後再計算總郵費,並將彙總結果附加為訂單表的最後一條記錄。
資料載入過程很簡單,這裡不再贅述,即:讀資料庫表,並命名為“訂單表”。
業務演算法相對複雜,具體如下:
| A |
B |
C |
D |
|
| 1 |
= pRule.export@j() |
/解析json,轉二維表 |
||
| 2 |
=免費=A1.select(field=="cost") |
/取免費標準,單條 |
||
| 3 |
=收費=A1.select(field=="weight").sort(-minVal) |
/取收費階梯,多條 |
||
| 4 |
=訂單表.derive(postage) |
/複製並新增欄位 |
||
| 5 |
for A4 |
if 免費.minVal < A5.cost |
>A5. postage= 免費.Charge |
|
| 6 |
next |
|||
| 7 |
for 收費 |
if A5.weight > B7.minVal |
>A5.postage=B7.Charge |
|
| 8 |
next A5 |
|||
| 9 |
=A4.record(["sum",,,A4.sum(postage)]) |
A1:解析json,將其轉為二維表。集算器支援多資料來源,不僅支援RDB,也支援NOSQL、檔案、webService。
A2-A3:查詢郵費規則,分為免費和收費兩種。
A4:新增空欄位postage。
A5-D8:按兩種規則迴圈訂單表,計算相應的郵費,並填入postage欄位。這裡多處用到流程控制,集算器用縮排表示,其中A5、B7為迴圈語句,C6、D8跳入下一輪迴圈,B5、C7為判斷語句
A9:在訂單表追加新紀錄,填入彙總值。
計算結果如下:
| Id |
cost |
weight |
postage |
| Josh1 |
150 |
6 |
25 |
| Drake |
100 |
3 |
20 |
| Megan |
100 |
1 |
10 |
| Josh2 |
200 |
3 |
20 |
| Josh3 |
500 |
1 |
0 |
| sum |
75 |
至此,本文詳細介紹了集算器用作記憶體計算引擎的完整過程,同時包括了常用計算方法和高階運算技巧。可以看到,集算器具有以下顯著優點:
l 結構簡單實施方便,可快速實現記憶體計算;
l 支援多種呼叫介面,應用整合沒有障礙;
l 支援透明優化,可顯著提升計算效能;
l 支援多種資料來源,便於實現混合計算;
l 語法敏捷精妙,可輕鬆實現複雜業務邏輯。
關於記憶體計算,還有個多機分散式計算的話題,將在後續文