
基於機器學習方法的POI品類推薦演算法
在美團商家資料中心(MDC),有超過100w的已校準稽核的POI資料(我們一般將商家標示為POI,POI基礎資訊包括:門店名稱、品類、電話、地址、座標等)。如何使用這些已校準的POI資料,挖掘出有價值的資訊,本文進行了一些嘗試:利用機器學習方法,自動標註缺失品類的POI資料。例如,門店名稱為“好再來牛肉拉麵館”的POI將自動標註“小吃”品類。
機器學習解決問題的一般過程:
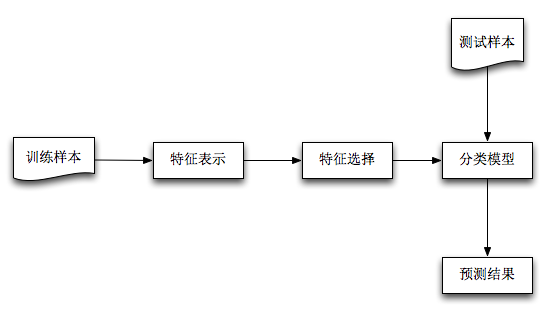
本文將按照:1)特徵表示;2)特徵選擇;3)基於Naive Bayes分類模型;4)分類預測,四個部分順序展開。
特徵表示
我們需要先將實際問題轉換成計算機可識別的形式。對於POI而言,反應出POI品類的一個重要特徵是POI門店名稱,那麼問題轉換成了根據POI門店名稱判別POI品類。POI名稱欄位屬於文字特徵,傳統的文字表示方法是基於向量空間模型(VSM模型)[1]:
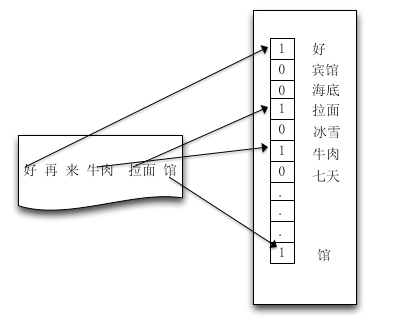
空間向量模型需要一個“字典”,這個字典可以在樣本中產生,也可以從外部匯入。上圖中的字典就是[好, 賓館, 海底, 拉麵, 冰雪, ....... ,館]。我們對已校準的POI,先利用Lucene的中文分詞工具SmartCn[2]對POI名稱做預分詞處理,提取特徵詞,作為原始粗糙字典集合。
有了字典後便可以量化地表示出某個文字。先定義一個與字典長度相同的向量,向量中的每個位置對應字典中的相應位置的單詞。然後遍歷這個文字,對應文字中的出現某個單詞,在向量中的對應位置,填入“某個值”(即特徵詞的權重,包括BOOL權重,詞頻權重,TFIDF權重)。考慮到一般的POI名稱都屬於短文字,本文采用BOOL權重。
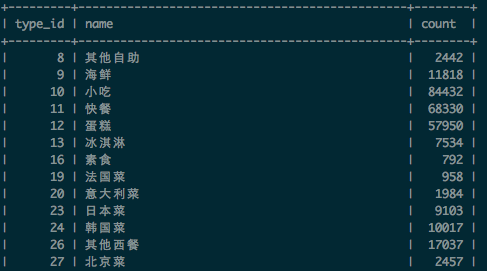
在產生粗糙字典集合時,我們還統計了校準POI中,每個品類(type_id),以及特徵詞(term)在品類(type_id)出現的次數(文件頻率)。分別寫入到表category_frequency和term_category_frequency,表的部分結果如下:
category_frequency表:
term_category_frequency表:
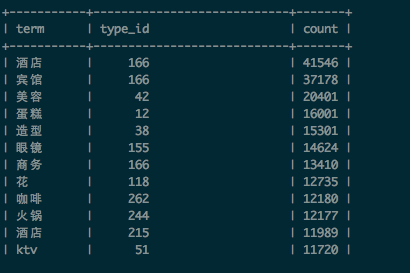
分別記:
A(i,j) = 特徵詞term(i) 在品類為type_id(j)出現的次數count
T(j) = 品類為type_id(j)在樣本集出現的次數
N = 已校準POI資料集的數量
這些統計量,將在後續的計算中發揮它們的作用。
特徵選擇
現在,我們得到了一個“預輸入字典”:包括了所有已校準POI名稱欄位的特徵詞,這些特徵詞比如:“88”、“11”, “3”、“auyi”、“中心”、“中國”、“酒店”、“自助餐”、“拉麵”等。直觀感覺,“88”、“11”, “3”、“auyi”、“中國”這些詞對判斷品類並沒有多大幫助,但“酒店”、“自助餐”、“拉麵”對判斷一個POI的品類卻可能起到非常重要作用。
那麼問題來了,如何挑選出有利於模型預測的特徵呢?這就涉及到了特徵選擇。特徵選擇方法可以分成基於領域知識的規則方法和基於統計學習方法。本文使用統計機器學習方法,輔助規則方法的特徵選擇演算法,挑選有利於判斷POI品類的特徵詞。
基於統計學習的特徵選擇演算法
基於統計學習的特徵選擇演算法,大體可以分成兩種:
1.基於相關性度量(資訊理論相關)
2.特徵空間表示(典型的如PCA)
文字特徵經常採用的基於資訊增益方法(IG)特徵選擇方法[3]。某個特徵的資訊增益是指,已知該特徵條件下,整個系統的資訊量的前後變化。如果前後資訊量變化越大,那麼可以認為該特徵起到的作用也就越大。
那麼,如何定義資訊量呢?一般採用熵的概念來衡量一個系統的資訊量:
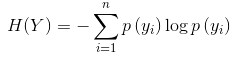
當我們已知該特徵時,從數學的角度來說就是已知了該特徵的分佈,系統的資訊量可以由條件熵來描述:
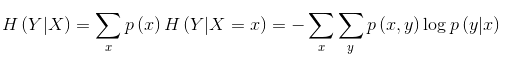
該特徵的資訊增益定義為:
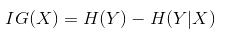
資訊增益得分衡量了該特徵的重要性。假設我們有四個樣本,樣本的特徵詞包括“火鍋”、“米粉”、“館”,我們採用資訊增益判斷不同特徵對於決策影響:
| 米粉(A) | 火鍋(B) | 館(C) | 品類 |
|---|---|---|---|
| 1 | 1 | 0 | 火鍋 |
| 0 | 1 | 1 | 火鍋 |
| 1 | 0 | 0 | 小吃 |
| 1 | 0 | 1 | 小吃 |
整個系統的最原始資訊熵為:
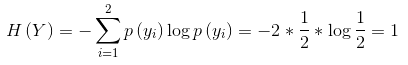
分別計算每個特徵的條件熵:
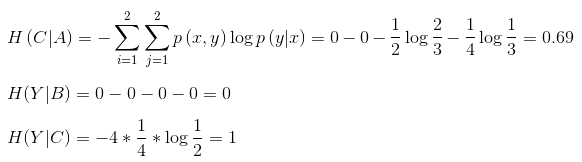
利用整個系統的資訊熵減去條件熵,得到每個特徵的資訊增益得分排名(“火鍋”(1) > “米粉”(0.31) > “館”(0)) ,按照得分由高到低挑選需要的特徵詞。
本文采用IG特徵選擇方法,選擇得分排名靠前的N個特徵詞(Top 30%)。我們抽取排名前20的特徵詞:[酒店, 賓館, 火鍋, 攝影, 眼鏡, 美容, 咖啡, ktv, 造型, 汽車, 餐廳, 蛋糕, 兒童, 美髮, 商務, 旅行社, 婚紗, 會所, 影城, 烤肉]。這些特徵詞明顯與品類屬性相關聯具有較強相關性,我們將其稱之為品類詞。
基於領域知識的特徵選擇方法
基於規則的特徵選擇演算法,利用領域知識選擇特徵。目前很少單獨使用基於規則的特徵選擇演算法,往往結合統計學習的特徵選擇演算法,輔助挑選特徵。
本文需要解決的是POI名稱欄位短文字的自動分類問題,POI名稱欄位一般符合這樣的規則,POI名稱 = 名稱核心詞 + 品類詞。名稱核心詞對於實際的品類預測作用不大,有時反而出現”過度學習“起到負面作用。例如”好利來牛肉拉麵館“, ”好利來“是它的名稱核心詞,在用學習演算法時學到的很有可能是一個”蛋糕“品類(”好利來“和”蛋糕“品類的關聯性非常強,得到錯誤的預測結論)。
本文使用該規則在挑選特徵時做了一個trick:利用特徵選擇得到的特徵詞(絕大部分是品類詞),對POI名稱欄位分詞,丟棄前面部分(主要是名稱核心詞),保留剩餘部分。這種trick從目前的評測結果看有5%左右準確率提升,缺點是會降低了演算法覆蓋度。
#分類模型
##建模
完成了特徵表示、特徵選擇後,下一步就是訓練分類模型了。機器學習分類模型可以分成兩種:1)生成式模型;2)判別式模型。可以簡單認為,兩者區別生成式模型直接對樣本的聯合概率分佈進行建模:
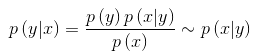
生成式模型的難點在於如何去估計類概率密度分佈p(x|y)。本文采用的樸素貝葉斯模型,其"Naive"在對類概率密度函式簡化上,它假設了條件獨立:
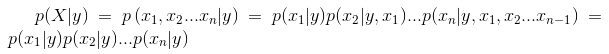
根據對p(x|y)不同建模形式,Naive Bayes模型主要分成:Muti-variate Bernoulli Model (多項伯努利模型)和Multinomial event model(多項事件模型)[4]。一次伯努利事件相當於一次投硬幣事件(0,1兩種可能),一次多項事件則相當於投色子(1到6多種可能)。我們結合傳統的文字分類解釋這兩類模型:
多項伯努利模型
已知類別的條件下,多項伯努利對應樣本生X成過程:遍歷字典中的每個單詞(t1,t2...t|V|),判斷這個詞是否在樣本中出現。每次遍歷都是一次伯努利實驗,|V|次遍歷:
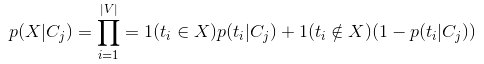
其中1(condition)為條件函式,該函式表示當條件成立是等於1,不成立時等於0;|V|則表示字典的長度。
多項事件模型
已知類別的條件下,多項事件模型假設樣本的產生過程:對文字中第k個位置的單詞,從字典中選擇一個單詞,每個位置k產生單詞對應於一次多項事件。樣本X=(w1,w2...ws)的類概率密度:
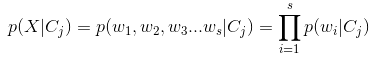
採用向量空間模型表示樣本時,上式轉成:
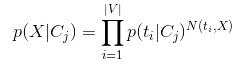
其中N(ti,X) 表示特徵詞i在樣本X出現的次數。
##引數估計
好啦,一大堆無聊公式的折磨後,我們終於要見到勝利的曙光:模型引數預估。一般的方法有最大似然估計、最大後驗概率估計等。本文使用的是多項伯努利模型,我們直接給出多項伯努利模型引數估計結論:
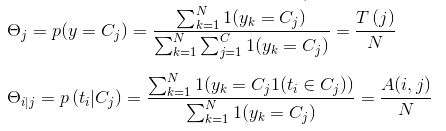
還記得特徵表示一節中統計的term_category_frequency和category_frequency兩張表嗎?此時,就要發揮它的作用了!我們,只需要查詢這兩張表,就可以完成引數的估計了,是不是很happy? 過程雖然有點曲折,但是結果是美好的~ 具體引數意義可以參見特徵表示一節。
接下來的coding的可能需要關注的兩個點:
引數平滑
在計算類概率密度p(X | Cj)時,如果在類Cj下沒有出現特徵ti ,p(ti | Cj)=0,類概率密度連乘也將會等於0,額,對於一個樣本如果在某條件下某個特徵沒有出現,便認為她產生的可能等於零,這樣的結論實在是過武斷,解決方法是加1平滑:
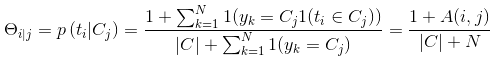
其中,|C|表示樣本的類別資料。
小數溢位
在計算類概率密度時多個條件概率(小數)連乘,會存在著超過計算機能夠表示的最小數可能,為避免小數溢位問題,一般將類概率密度計算轉成成對數累和的形式。
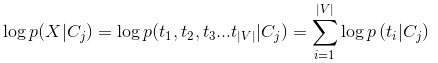
另外,如果在計算p(ti | Cj)時過小,取對數後將會得到一個負無窮的值,需要對p(ti | Cj)截斷處理:小於某個閾值(如1E-6)時,採用該閾值替代。
演算法預測
本節將結合前面三節內容,給出演算法具體的計算預測過程。為簡化問題,我們假設字典為:[拉麵,七天,牛肉,館],並且只有火鍋和快餐兩個品類,兩類樣本的數量均為8個。以“好 利 來 牛肉 拉麵 館為例”:
對測試樣本做中文分詞,判斷”牛肉“屬於品類詞,丟棄品類詞”牛肉“前面的部分,並提取樣本的特徵詞集合得到:[牛肉 拉麵 館]
根據字典,建立向量空間模型:x = [1, 0, 1, 1]
利用Naive Bayes模型分類預測,我們給出火鍋和快餐兩類樣本的term_category_frequency統計:
| 特徵詞\品類 | 火鍋(C1) | 快餐(C2) |
|---|---|---|
| 拉麵 | 0 | 5 |
| 七天 | 2 | 0 |
| 牛肉 | 4 | 2 |
| 館 | 2 | 1 |
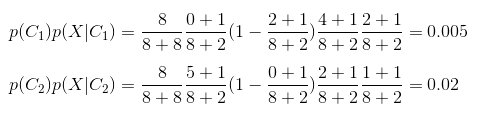
樣本屬於快餐的概率高於屬於火鍋概率4倍,預測樣本屬於快餐置信度明顯高於火鍋概率。
演算法隨機抽取2000條未校準的POI資料進行評測,演算法的評測指標有兩個:覆蓋度和準確率。覆蓋度是指演算法可預測的樣本數量在整個測試樣本集中的比例。由於採用特徵選擇後,一些POI名稱因不包含特徵詞集合而無法預測,演算法的評測的覆蓋度為84%。演算法的準確率是指,可預測正確樣本在整個測試樣本集中的比例,演算法評測的正確率為91%。
#總結
機器學習解決問題最關鍵的一步是找準問題:這種問題能否用機器學習演算法解決?是否存在其他更簡單的方法?簡單的如字串匹配,利用正則就可以簡單解決,才機器學習方法反而很麻煩,得不償失。
如果能機器學習演算法,如何去表示這個機器學習問題,如何抽取特徵?又可能歸類哪類機器模式(分類、聚類、迴歸?)
找準問題後,可以先嚐試一些開源的機器學習工具,驗證演算法的有效性。如果有必要,自己實現一些機器演算法,也可以借鑑一些開源機器學習演算法實現。