
NLP之中文命名實體識別
在MUC-6中首次使用了命名實體(named entity)這一術語,由於當時關注的焦點是資訊抽取(information extraction)問題,即從報章等非結構化文字中抽取關於公司活動和國防相關活動的結構化資訊,而人名、地名、組織機構名、時間和數字表達(包括時間、日期、貨幣量和百分數等)是結構化資訊的關鍵內容。
命名實體識別(Named EntitiesRecognition,NER),就是識別這些實體指稱的邊界和類別。主要關注人名、地名和組織機構名這三類專有名詞的識別方法。
一、方法概述
和自然語言處理研究的其他任務一樣,早期的命名實體識別方法大都是基於規則的。系統的實現代價較高,而且其可移植性受到一定的限制。
自20世紀90年代後期以來,尤其是進入21世紀以後,基於大規模語料庫的統計方法逐漸成為自然語言處理的主流,一大批機器學習方法被成功地應用於自然語言處理的各個方面。根據使用的機器學習方法的不同,我們可以粗略地將基於機器學習的命名實體識別方法劃分為如下四種:有監督的學習方法、半監督的學習方法、無監督的學習方法、混合方法。下表對這些方法進行了簡要歸納。

二、命名實體識別方法
1.基於CRF的命名實體識別方法
McCallum等2003年最先將條件隨機場(CRF)模型用於命名實體識別。由於該方法簡便易行,而且可以獲得較好的效能,因此受到業界青睞,已被廣泛地應用於人名、地名和組織機構等各種型別命名實體的識別,並在具體應用中不斷得到改進,可以說是命名實體識別中最成功的方法。
基於CRF的命名實體識別與前面介紹的基於字的漢語分詞方法的原理一樣,就是把命名實體識別過程看作一個序列標註問題。其基本思路是(以漢語為例):將給定的文字首先進行分詞處理,然後對人名、簡單地名和簡單的組織機構名進行識別,最後識別複合地名和複合組織機構名。
所謂的簡單地名是指地名中不巢狀包含其他地名,如地名:北京市、大不列顛、北愛爾蘭、中關村等,而“北京市海淀區中關村東路95號”、“大不列顛及北愛爾蘭聯合王國”、“葉門民主人民共和國”則為複合地名。同樣,簡單的組織機構名中也不巢狀包括其他組織機構名,如北京大學、衛生部、聯合國等,而“歐洲中央銀行”、“中華人民共和國衛生部”、“聯合國世界糧食計劃署”均為複合組織機構名。
基於CRF的命名實體識別方法屬於有監督的學習方法,因此,需要利用已標註的大規模語料對CRF模型的引數進行訓練。北京大學計算語言學研究所標註的現代漢語多級加工語料庫被眾多研究者用於漢語命名實體識別的模型訓練。
在訓練階段,首先需要將分詞語料的標記符號轉化成用於命名實體序列標註的標記,如用PNB表示人名的起始用字,PNI表示名字的內部用字。類似地,用LOCB表示地名的起始用字,LOCI表示地名的內部用字;ORGB表示組織機構的起始用字,ORGI表示組織機構的內部用字。用OUT統一表示該字或詞不屬於某個實體。
接下來要做的事情是確定特徵模板。特徵模板一般採用當前位置的前後n(n≥1)個位置上的字(或詞、字母、數字、標點等,不妨統稱為“字串”)及其標記表示,即以當前位置的前後n個位置範圍內的字串及其標記作為觀察視窗:(…w-n/tag-n,…,w-1/tag-1w0/tag0,w1/tag1,…,wn/tagn,…)。考慮到,如果視窗開得較大時,演算法的執行效率會太低,而且模板的通用性較差,但視窗太小時,所涵蓋的資訊量又太少,不足以確定當前位置上字串的標記,因此,一般情況下將n值取為2~3,即以當前位置上前後2~3個位置上的字串及其標記作為構成特徵模型的符號。
由於不同的命名實體一般出現在不同的上下文語境中,因此,對於不同的命名實體識別一般採用不同的特徵模板。例如,在識別漢語文字中的人名時,考慮到不同國家的人名構成特點有明顯的不同,一般將人名劃分為不同的型別:中國人名、日本人名、俄羅斯人名、歐美人名等。同時,考慮到出現在人名左右兩邊的字串對於確定人名的邊界有一定的幫助作用,如某些稱謂、某些動詞和標點等,因此,某些總結出來的“指界詞”(左指界詞或右指界詞)也可以作為特徵。
特徵函式確定以後,剩下的工作就是訓練CRF模型引數λ。
大量的實驗表明,在人名、地名、組織機構名三類實體中,組織機構名識別的效能最低。一般情況下,英語和漢語人名識別的F1值都可以達到90%左右,而組織機構名識別的F1值一般都在85%左右,這也反映出組織機構名是最難識別的一種命名實體。當然,對於不同領域和不同型別的文字,測試效能會有較大的差異。
2.基於多特徵的命名實體識別方法
在命名實體識別中,無論採用哪一種方法,都是試圖充分發現和利用實體所在的上下文特徵和實體的內部特徵,只不過特徵的顆粒度有大(詞性和角色級特徵)有小(詞形特徵)的問題。考慮到大顆粒度特徵和小顆粒度特徵有互相補充的作用,應該兼顧使用的問題,提出了基於多特徵相融合的漢語命名實體識別方法,該方法是在分詞和詞性標註的基礎上進一步進行命名實體的識別,由詞形上下文模型、詞性上下文模型、詞形實體模型和詞性實體模型4個子模型組成的。其中,詞形上下文模型估計在給定詞形上下文語境中產生實體的概率;詞性上下文模型估計在給定詞性上下文語境中產生實體的概率;詞形實體模型估計在給定實體型別的情況下詞形串作為實體的概率;詞性實體模型估計在給定實體型別的情況下詞性串作為實體的概率。
1.模型描述
在基於多特徵模型的命名實體識別系統中,詞形包括以下幾種情況:字典中任何一個字或詞單獨構成一類;人名(Per)、人名簡稱(Aper)、地名(Loc)、地名簡稱(Aloc)、機構名(Org)、時間詞(Tim)和數量詞(Num)各定義為一類。也就是說,詞形語言模型中共定義了|V|+7個詞形,其中,|V|表示詞典的規模。由詞形構成的序列稱為詞形序列WC。
詞性採用北京大學計算語言學研究所開發的漢語文字詞性標註標記集,另加上人名簡稱詞性和地名簡稱詞性,共47個詞性標記。由詞性標記構成的序列稱為詞性序列TC。
命名實體識別可以看作一個序列化資料的標註問題。輸入是帶有詞性標記的詞序列。
在分詞和詞性標註的基礎上進行命名實體識別的過程就是對部分詞語進行拆分、組合(確定實體邊界)和重新分類(確定實體類別)的過程,最後輸出一個最優的“詞形/詞性”序列WC*/TC*。
計算最優“詞形/詞性”序列WC*/TC*的方法有三種:詞形特徵模型、詞性特徵模型和混合模型。
(1)詞形模型
詞形特徵模型根據詞形序列W產生候選命名實體,用Viterbi確定最優詞形序列WC*。目前的大部分系統都是從這個層面來設計命名實體識別演算法的。
(2)詞性模型
詞性特徵模型根據詞性序列T產生候選命名實體,用Viterbi確定最優詞性序列TC*。目前只有較少的系統使用。
(3)混合模型
詞形和詞性混合模型是根據詞形序列W和詞性序列T產生候選命名實體,一體化確定最優序列WC*/TC*,即本節將要介紹的基於多特徵的識別演算法。
詞形和詞性混合的漢語命名實體識別模型結合了詞形特徵模型和詞性特徵模型的優點,可以描述成下面式子的形式:
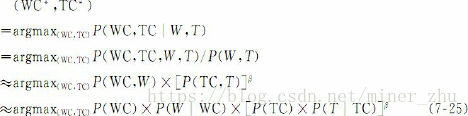
式子中的β是平衡因子,平衡詞形特徵和詞性特徵的權重,β>0。
模型(7-25)由四部分組成,分別稱之為:詞形上下文模型P(WC)、詞性上下文模型P(TC)、實體詞形模型P(W|WC)和實體詞性模型P(T|TC)。實體詞形模型和實體詞性模型統稱為實體模型。以下分別介紹這些模型。
2.詞形和詞性上下文模型
上下文模型估計在給定的上下文語境中產生實體的詞形和詞性概率。詞形上下文模型和詞性上下文模型均可採用三元語法模型近似描述:
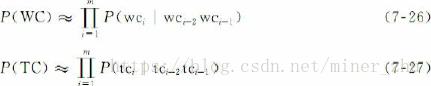
3.實體模型
考慮到每一類命名實體都具有不同的內部特徵,因此,不能用一個統一的模型刻畫人名、地名和機構名等實體模型。例如,人名識別可採用基於字的三元模型,地名和機構名識別可能更適合於採用基於詞的三元模型等。此外,為提高外國人名的識別效能,吳友政又把外國人名進一步劃分為日本人名、歐美人名和俄羅斯人名三個子類。因為這三類人名的內部特徵(主要是人名用字集)存在較大的差別,日本人名用字相對較廣,具有相對明顯的姓氏特徵,但姓氏集合卻很大,而且日本人名姓氏很多和地名重疊。俄羅斯人名常用斯、基、娃等漢字,而歐美人名常用朗、魯、倫、曼等漢字。為計算需要,按照字或詞在命名實體內部的位置,吳友政把這些字或詞劃分成19個子類。
有了上述分類之後,人名、普通地名和機構名、單字地名和簡稱機構名分別建立相應的實體模型。
(1)人名實體模型
基於字的中國人名和外國人名的實體詞形模型用下式描述:
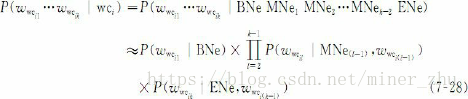
其中,wwcil(1≤l≤k)表示組成人名實體wci的單字。BNe,MNei(1≤i≤k-2)和ENe分別表示實體的首字、中間字和尾字,在具體計算人名時,分別將其替換成Sur、Dgb、Dge、EBfn、EMfn和EEfn等。
由於人名的詞性實體模型的訓練語料很難得到,因此,為了簡化起見,使用詞形實體模型替代詞性實體模型,但乘以一個加權因子,如下式所示:
其中,γ為小於1的加權因子,在吳友政的實驗系統中取經驗值0.5。
(2)地名和機構名實體模型
對於地名和機構名,其實體模型要複雜得多,這是因為地名中除了普通詞彙以外,還常巢狀人名和其他地名,如“茅盾故居紀念館”,“北京市經濟技術開發區”等;組織機構名中常巢狀人名、地名和其他機構名,如“富士通(中國)有限公司”,“宋慶齡基金會”等。
基於詞的巢狀地名和機構名詞形實體模型可以用下面的式子描述:
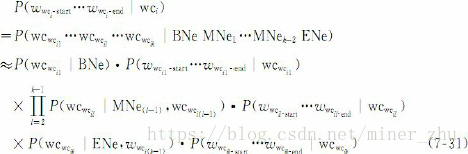
其中,wwci-start和wwci-end分別是實體wci被分詞程式切分出的首詞和尾詞;wwcil- 和wwc 分別是wcwcil的首詞和尾詞,它們都是按照分詞模start il-end塊的詞形定義切分出來的最基本的詞形。wcwcil(1≤l≤k)是由原分詞序列組合的可能的詞,假設組合後含有k個詞或子實體名,即長度為k,子實體可能是人名或地名。如果子實體是人名時,將被符號PER替換,如果子實體是地名時,將用標記Loc替換。BNe為實體wci被正確切分時的首詞,根據表7-8記作Boo;MNe1…MNek-2為實體wci被正確切分時中間
部分的k-2個詞,根據表7-8記作Moo;ENe為實體wci被正確切分時的末尾詞,根據表7-8記作Eoo。
(3)單字地名實體模型
單字地名詞形實體模型和詞性實體模型均可採用最大似然估計方法計算,分別運用如下算式估計:

其中,C(wi,Aloc)和C(ti,Aloc)分別是語料中wi作為單字地名和其詞性ti出現的次數。C(Aloc)為訓練語料中單字地名出現的次數。
(4)簡稱機構名實體模型
簡稱機構名是對機構名全稱的縮略叫法。機構名簡稱的出現形式大致可分為連續簡寫、不連續簡寫和混合簡寫三種方式。
包括機構名關鍵詞的機構名簡稱(如福特公司,綠得公司,新唐公司)的識別同機構名全稱的識別過程是一樣的,但對於那些省略了機構名關鍵詞的簡稱機構名的識別則是非常困難的問題。
經過分析我們發現,簡稱機構名在文字中的出現基本上有以下三種形式:
① 某些簡稱可以作為常用詞收錄進詞典中,如中共、北約、歐盟等
② 有些簡稱機構名無法被收錄進詞典,但該簡稱的全稱形式在文字中出現過,如華虹NEC(全稱為“上海華虹NEC電子有限公司”,且在文中已經出現過)
③ 文字中直接出現省略了機構名關鍵詞的簡稱機構名,如“百度”(省略了關鍵詞“公司”)等。
對於上述形式③沒有標誌性關鍵詞的情況,識別非常困難,我們暫不探討。以下主要介紹形式①和②的處理方法。
形式①簡稱機構名的實體模型:簡稱機構名的詞形和詞性實體模型用最大似然估計方法計算
形式②簡稱機構名的詞形實體模型:在真實文字中,簡稱可能出現在文字的前面,也可能出現在後面,為了完成這類簡稱機構名的識別,一般需要把命名實體識別分成兩個階段。第一階段識別1類簡稱機構名和全稱形式的機構名,並將其放入快取器(cache)中,第二階段利用第一階段的識別結果進行簡稱識別。這樣做一方面可以避免簡稱機構名的遺漏,並限制不必要的簡稱機構名的產生,另一方面可以方便、合理地計算簡稱機構名的產生概率,即簡稱的實體模型。
4.專家知識
在基於統計模型的命名實體識別中,最大的問題是資料稀疏嚴重,搜尋空間太大,從而影響系統的效能和效率。因此,吳友政通過引入專家知識來限制候選實體的產生,從而達到了提高系統性能和效率的目的。這些專家知識主要包括如下幾類:
1)人名識別的專家知識
這類專家知識包括:476箇中國人名姓氏列表和9189個日本人名姓氏列表,用於限制中國人名和日本人名的候選詞數;俄羅斯人名和歐美人名用字列表,用來限制俄羅斯人名和歐美人名的候選詞數;另外,中國人名的長度最大為8個字元,外國人名則不受長度限制。
2)地名識別的專家知識
這裡專家知識包括一個含607個地名關鍵詞的列表、一個含407個單字地名的列表和一個介詞、動詞列表。如果當前詞屬於地名關鍵詞,如“省、開發區、沙灘、瀑布”等,則觸發地名識別。單字地名的候選由單字地名列表觸發產生。如果前一個詞包含在介詞、動詞列表中,如“去、到、在”等則觸發地名識別。另外,地名最多包含12個漢語字元。
(3)機構名識別的專家知識
機構名識別專家知識包括一個含有3129個機構名關鍵詞的列表,用於觸發產生機構名候選,即如果當前詞屬於該列表,則機構名識別觸發。另外,還包括一組機構名模板,用於識別統計模型遺漏的巢狀命名實體。
5.模型訓練
根據前面的介紹,基於多特徵的漢語命名實體識別模型式(7-25)由4個引數組成,在吳友政(2006)實現的系統中,這些引數使用最大似然估計從不同的訓練語料中學習,其中,詞性上下文模型P(TC)和詞形上下文模型P(WC)是從1998年2月至1998年6月的《人民日報》標註語料中學習的;中國人名、外國人名、地名、機構名的實體詞性模型和實體詞形模型分別從156萬、1.4萬、4.4萬和32萬條的實體列表中訓練得到的。
儘管使用了這樣大規模的訓練語料,資料稀疏問題還是非常嚴重。為此,吳友政採用了Back-off資料平滑方法,並引入逃逸概率計算權值,如下式所示:
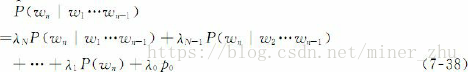
6.測試結果
系統性能表現主要通過準確率(precision,簡記為P)、召回率(recall,簡記為R)和F-測度值(F-measure,簡記為F)3個指標來衡量,計算公式分別如式(7-40)、式(7-41)和式(7-42)所示:

根據模型計算式(7-25),平衡因子β是用於平衡詞形特徵和詞性特徵所發揮作用的權值,β值越大,詞性特徵的作用越強;否則,詞形特徵的作用就越強。根據吳友政(2006)的實驗,β值從0到9.6變化時,系統對人名、地名和機構名稱識別的準確率、召回率和F-測度值均有不同程度的上升和下降,當β值大於9.6時,人名、地名和機構名稱識別的正確率、召回率和F-測度值均呈急劇下降趨勢。經綜合考察後,β=2.8時系統對人名、地名和機構名稱識別的總體效能可達到最佳狀態。
混合模型的人名、地名、機構名識別效能(F-測度值)比單獨使用詞形特徵模型時的效能分別提高了約5.4%,1.4%,2.2%,比單獨使用詞性特徵模型時分別提高了約0.4%,2.7%,11.1%。也就是說,結合詞形和詞性特徵的命名實體識別模型優於使用單一特徵的命名實體識別模型。
另外,實驗還表明,結合了專家知識的統計模型對人名、地名和機構名的識別能力(F-測度值)與純統計模型相比,分別提高了約14.8%,9.8%,13.8%,而且,系統的識別速度也有所提高。
上述結果表明,基於多特徵模型的命名實體識別方法綜合運用了詞形特徵和詞性特徵的作用,針對不同實體的結構特點,分別建立實體識別模型,並利用專家知識限制明顯不合理的實體候選的產生,從而提高了識別效能和系統效率。