
BiLSTM介紹及中文命名實體識別應用
What-什麼是LSTM和BiLSTM?
LSTM:全稱Long Short-Term Memory,是RNN(Recurrent Neural Network)的一種。LSTM由於其設計的特點,非常適合用於對時序資料的建模,如文字資料。
BiLSTM:Bi-directional Long Short-Term Memory的縮寫,是由前向LSTM與後向LSTM組合而成。
可以看出其很適合做上下有關係的序列標註任務,因此在NLP中常被用來建模上下文資訊。
我們可以簡單理解為雙向LSTM是LSTM的改進版,LSTM是RNN的改進版。
(這裡簡單說一下RNN,熟悉的可以直接跳過。RNN的意思是,為了預測最後的結果,我先用第一個詞預測,當然,只用第一個預測的預測結果肯定不精確,我把這個結果作為特徵,跟第二詞一起,來預測結果;接著,我用這個新的預測結果結合第三詞,來作新的預測;然後重複這個過程;直到最後一個詞。這樣,如果輸入有n個詞,那麼我們事實上對結果作了n次預測,給出了n個預測序列。整個過程中,模型共享一組引數。因此,RNN降低了模型的引數數目,防止了過擬合,同時,它生來就是為處理序列問題而設計的,因此,特別適合處理序列問題。LSTM對RNN做了改進,使得其能夠捕捉更長距離的資訊。但是不管是LSTM還是RNN,都有一個問題,它是從左往右推進的,因此後面的詞會比前面的詞更重要。因此出現了雙向LSTM,它從左到右做一次LSTM,然後從右到左做一次LSTM,然後把兩次結果組合起來。)
Why-為什麼使用LSTM與BiLSTM?
如果我們想要句子的表示,可以在詞的表示基礎上組合成句子的表示,那麼我們可以採用相加的方法,即將所有詞的表示進行加和,或者取平均等方法。但是這些方法很大的問題是沒有考慮到詞語在句子中前後順序。而使用LSTM模型可以更好的捕捉到較長距離的依賴關係。因為LSTM通過訓練過程可以學到記憶哪些資訊和遺忘哪些資訊。但是利用LSTM對句子進行建模也存在一個問題:無法編碼從後到前的資訊。而通過BiLSTM可以更好的捕捉雙向的語義依賴。
How-BiLSTM原理

詳細原理可看:https://www.jiqizhixin.com/articles/2018-10-24-13
Do-BiLSTM與NER任務
BiLSTM-CRF模型簡單介紹
所有 RNN 都具有一種重複神經網路單元的鏈式形式。在標準的RNN中,這個重複的單元只有一個非常簡單的結構,例如一個tanh層。

LSTM 同樣是這樣的結構,但是重複的單元擁有一個不同的結構。不同於普通RNN單元,這裡是有四個,以一種非常特殊的方式進行互動。
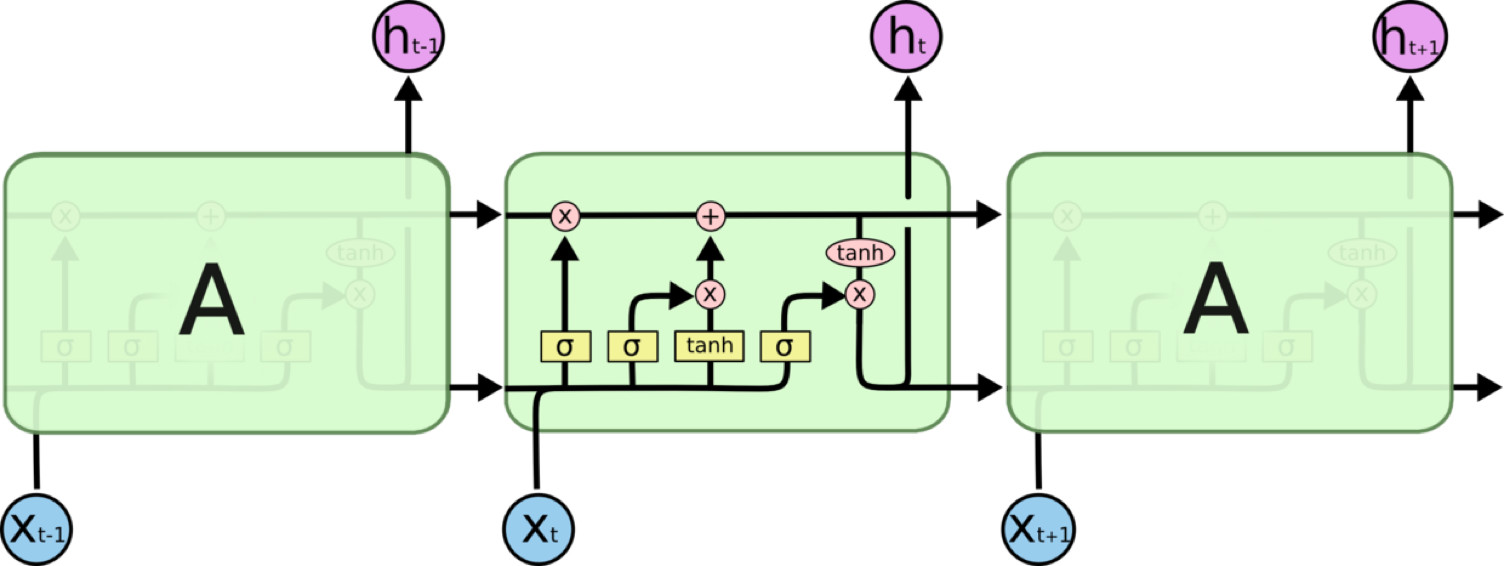
圖4:LSTM結構
LSTM通過三個門結構(輸入門,遺忘門,輸出門),選擇性地遺忘部分歷史資訊,加入部分當前輸入資訊,最終整合到當前狀態併產生輸出狀態。
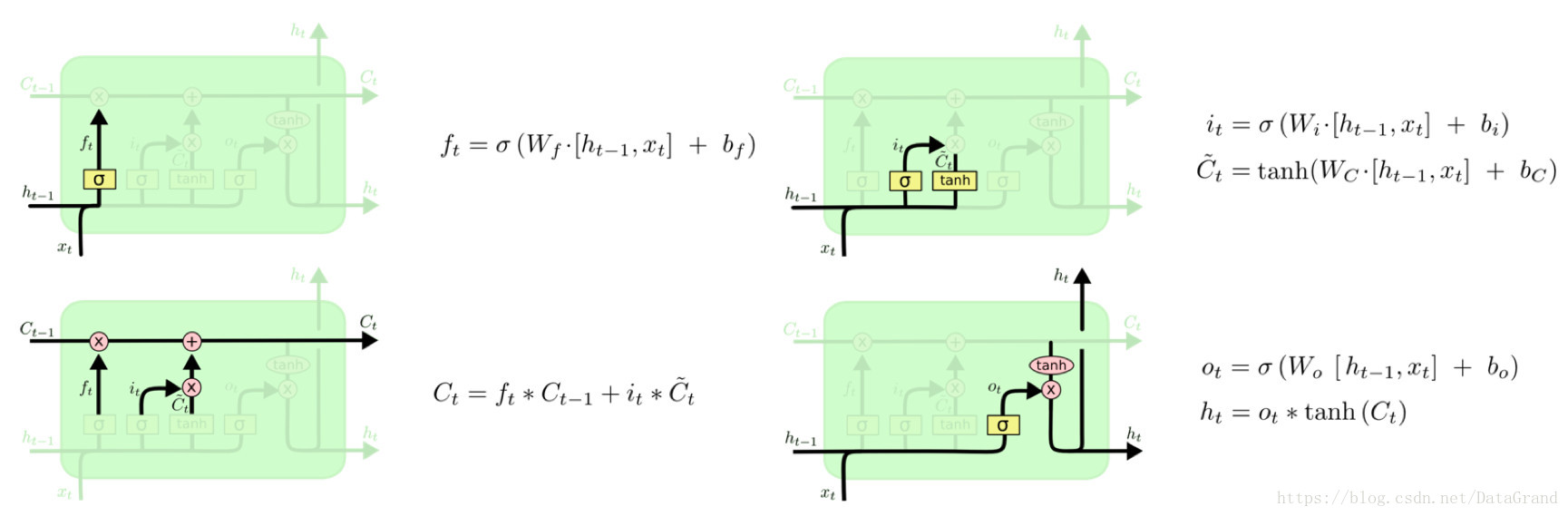
圖5:LSTM各個門控結構
應用於NER中的biLSTM-CRF模型主要由Embedding層(主要有詞向量,字向量以及一些額外特徵),雙向LSTM層,以及最後的CRF層構成。實驗結果表明biLSTM-CRF已經達到或者超過了基於豐富特徵的CRF模型,成為目前基於深度學習的NER方法中的最主流模型。
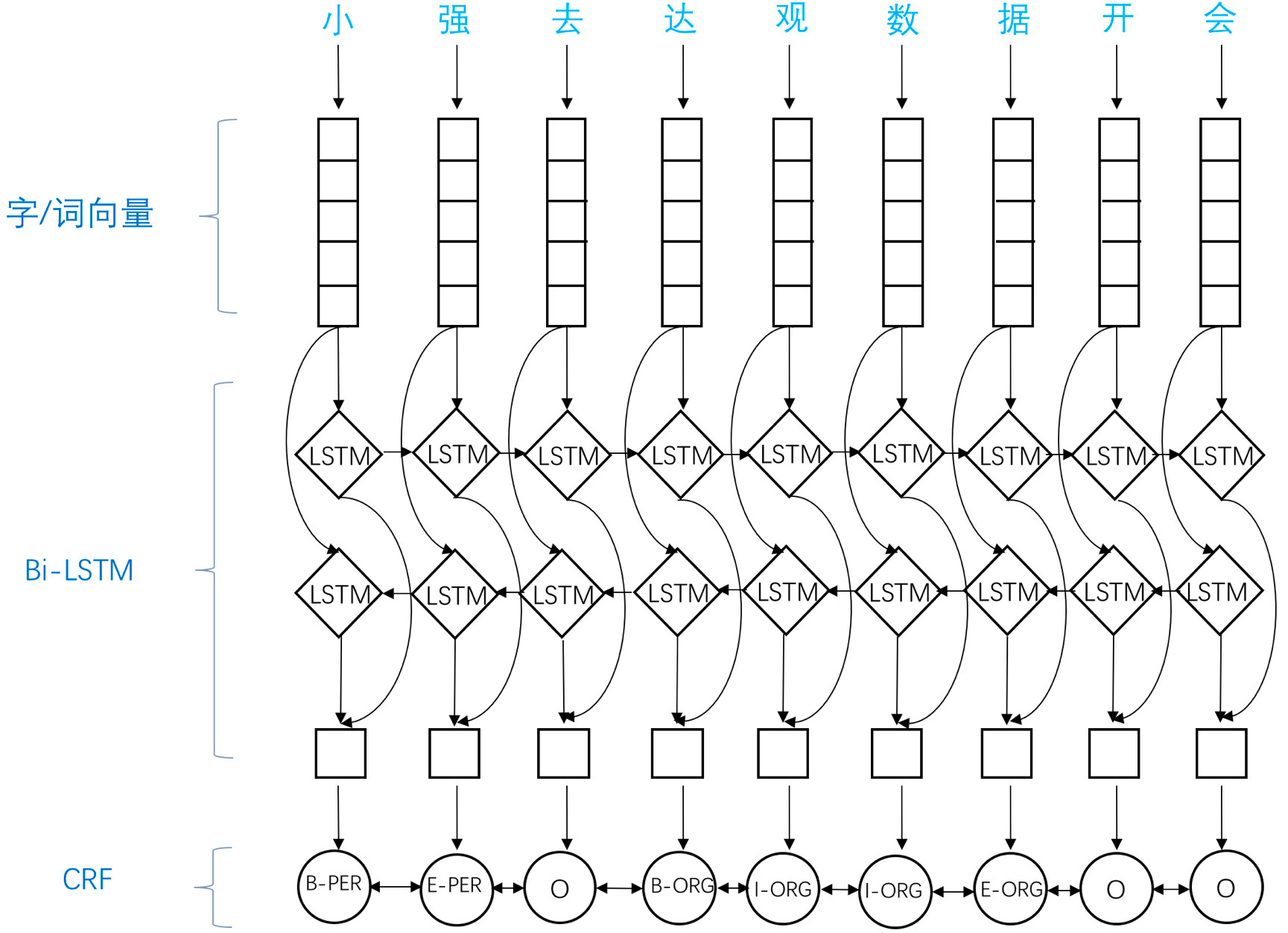
參考文章
https://my.oschina.net/datagrand/blog/2251431
https://www.jiqizhixin.com/articles/2018-10-24-13