
DeepLabv3+:語義分割領域的新高峰
DeepLabv1
DeepLab 是結合了深度卷積神經網路(DCNNs)和概率圖模型(DenseCRFs)的方法。
在實驗中發現 DCNNs 做語義分割時精準度不夠的問題,根本原因是 DCNNs 的高階特徵的平移不變性,即高層次特徵對映,根源於重複的池化和下采樣。
針對訊號下采樣或池化降低解析度,DeepLab 是採用的 atrous(帶孔)演算法擴充套件感受野,獲取更多的上下文資訊。
分類器獲取以物件中心的決策是需要空間變換的不變性,這天然地限制了 DCNN 的定位精度,DeepLab 採用完全連線的條件隨機場(CRF)提高模型捕獲細節的能力。
除空洞卷積和 CRFs 之外,論文使用的 tricks 還有 Multi-Scale features。其實就是 U-Net 和 FPN 的思想,在輸入影象和前四個最大池化層的輸出上附加了兩層的 MLP,第一層是 128 個 3×3 卷積,第二層是 128 個 1×1 卷積。最終輸出的特徵與主幹網的最後一層特徵圖融合,特徵圖增加 5×128=640 個通道。
實驗表示多尺度有助於提升預測結果,但是效果不如 CRF 明顯。
論文模型基於 VGG16,在 Titan GPU 上執行速度達到了 8FPS,全連線 CRF 平均推斷需要 0.5s ,在 PASCAL VOC-2012 達到 71.6% IOU accuracy。
DeepLabv2
DeepLabv2 是相對於 DeepLabv1 基礎上的優化。DeepLabv1 在三個方向努力解決,但是問題依然存在:特徵解析度的降低、物體存在多尺度,DCNN 的平移不變性。
因 DCNN 連續池化和下采樣造成解析度降低,DeepLabv2 在最後幾個最大池化層中去除下采樣,取而代之的是使用空洞卷積,以更高的取樣密度計算特徵對映。
物體存在多尺度的問題,DeepLabv1 中是用多個 MLP 結合多尺度特徵解決,雖然可以提供系統的效能,但是增加特徵計算量和儲存空間。
論文受到 Spatial Pyramid Pooling (SPP) 的啟發,提出了一個類似的結構,在給定的輸入上以不同取樣率的空洞卷積並行取樣,相當於以多個比例捕捉影象的上下文,稱為 ASPP (atrous spatial pyramid pooling) 模組。
DCNN 的分類不變形影響空間精度。DeepLabv2 是取樣全連線的 CRF 在增強模型捕捉細節的能力。
論文模型基於 ResNet,在 NVidia Titan X GPU 上執行速度達到了 8FPS,全連線 CRF 平均推斷需要 0.5s ,在耗時方面和 DeepLabv1 無差異,但在 PASCAL VOC-2012 達到 79.7 mIOU。
DeepLabv3
好的論文不止說明怎麼做,還告訴為什麼。DeepLab 延續到 DeepLabv3 系列,依然是在空洞卷積做文章,但是探討不同結構的方向。
DeepLabv3 論文比較了多種捕獲多尺度資訊的方式:
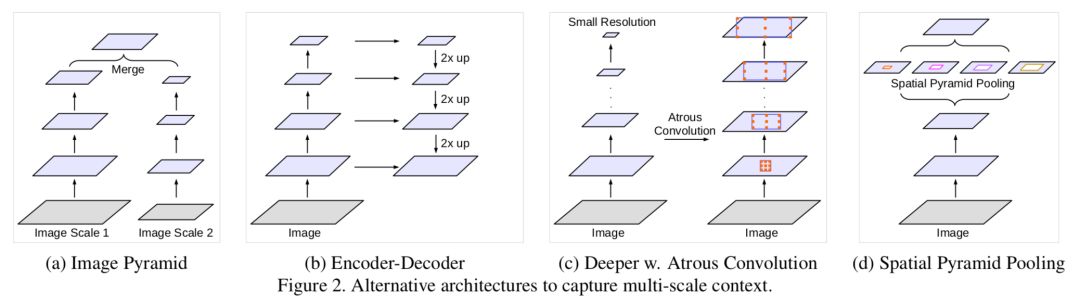
1. Image Pyramid:將輸入圖片放縮成不同比例,分別應用在 DCNN 上,將預測結果融合得到最終輸出。
2. Encoder-Decoder:利用 Encoder 階段的多尺度特徵,運用到 Decoder 階段上恢復空間解析度,代表工作有 FCN、SegNet、PSPNet 等工。
3. Deeper w. Atrous Convolution:在原始模型的頂端增加額外的模組,例如 DenseCRF,捕捉畫素間長距離資訊。
4. Spatial Pyramid Pooling:空間金字塔池化具有不同取樣率和多種視野的卷積核,能夠以多尺度捕捉物件。
DeepLabv1-v2 都是使用帶孔卷積提取密集特徵來進行語義分割。但是為了解決分割物件的多尺度問題,DeepLabv3 設計採用多比例的帶孔卷積級聯或並行來捕獲多尺度背景。
此外,DeepLabv3 將修改之前提出的帶孔空間金字塔池化模組,該模組用於探索多尺度卷積特徵,將全域性背景基於影象層次進行編碼獲得特徵,取得 state-of-art 效能,在 PASCAL VOC-2012 達到 86.9 mIOU。
DeepLabv3+
DeepLabv3+ 架構
DeepLabv3+ 繼續在模型的架構上作文章,為了融合多尺度資訊,引入語義分割常用的 encoder-decoder。在 encoder-decoder 架構中,引入可任意控制編碼器提取特徵的解析度,通過空洞卷積平衡精度和耗時。
在語義分割任務中採用 Xception 模型,在 ASPP 和解碼模組使用 depthwise separable convolution,提高編碼器-解碼器網路的執行速率和健壯性,在 PASCAL VOC 2012 資料集上取得新的 state-of-art 表現,89.0 mIOU。

Xception 改進
Entry flow 保持不變,但是添加了更多的 Middle flow。所有的 max pooling 被 depthwise separable convolutions 替代。在每個 3x3 depthwise convolution 之外,增加了 batch normalization 和 ReLU。
實驗
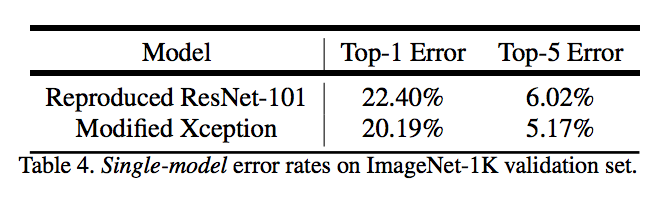
論文提出的模型在主幹網路 ResNet-101 和 Xception均進行驗證。兩種方式均在 ImageNet 預訓練。其中 Xception 預訓練過程中,使用 50 個 GPU,每個 GPU batch size=32,解析度 299x299。Xception 相比 ResNet-101,在 Top-1 和 Top-5 分別提高 0.75% 和 0.29%。
在實驗過程中,分別考慮 train OS: The output stride used during training、eval OS: The output stride used during evaluation、Decoder: Employing the proposed decoder structure、MS: Multi-scale inputs during evaluation、 Flip: Adding left-right flipped inputs 等各種情況。

另外使用 depthwise separable convolution,使用 Pretraining on COCO 和 Pretraining on JFT,在這些 tricks 輔助下,PASCAL VOC 2012 test set 達到驚人的 89.0%,取得新的 state-of-the-art 水平。

結論
從 DeepLabv1-v4 系列看,空洞卷積必不可少。從 DeepLabv3 開始去掉 CRFs。
Github 目前還未有公佈的 DeepLabv3,但是有網友的復現版本。DeepLabv3+ 更是沒有原始碼,復現起來估計有些難度。
DeepLabv3 復現:
https://github.com/NanqingD/DeepLabV3-Tensorflow
DeepLabv1-v4 沒有用很多 tricks,都是從網路架構中調整,主要是如何結合多尺度資訊和空洞卷積。從FCN,ASPP,Encoder-Decoder with Atrous Conv,每一個想法看上去在別的都實現過,但是論文綜合起來就是有效。
Deeplabv1,v2 耗時為 8fps,從 Deeplabv3 開始,論文已經不說執行時間的問題,是否模型越來越慢了。
MobileNetV2 已經實現 Deeplabv3,並努力在 MobileNetV2 中復現 DeepLabv3+ 版本。
參考文獻
[1] Semantic image segmentation with deep convolutional nets and fully connected CRFs
[2] DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
[3] Rethinking Atrous Convolution for Semantic Image Segmentation
[4] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
PaperDaily
關於作者:陳泰紅,小米高階演算法工程師,研究方向為人臉檢測識別,手勢識別與跟蹤。
■ 論文 | Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
■ 連結 | https://www.paperweekly.site/papers/1676