
基於領域自適應的語義分割(DA-based SS)
文章目錄
- 1. 預備知識
- 2. 相關論文
- 2.1 CVPR 18-Learning to Adapt Structured Output Space for Semantic Segmentation
- 2.2 CVPR 18-Fully Convolutional Adaptation Networks for Semantic Segmentation
- 2.3 ECCV 18-Domain Adaptation for Semantic Segmentation via Class-Banlanced Self-Training
- 3. 總結
1. 預備知識
1.1 域適應 (Domain Adaptation, DA)
1.2 語義分割 (Semantic Segmentation, SS)
語義分割介紹
An overview of semantic image segmentation

2. 相關論文
2.1 CVPR 18-Learning to Adapt Structured Output Space for Semantic Segmentation
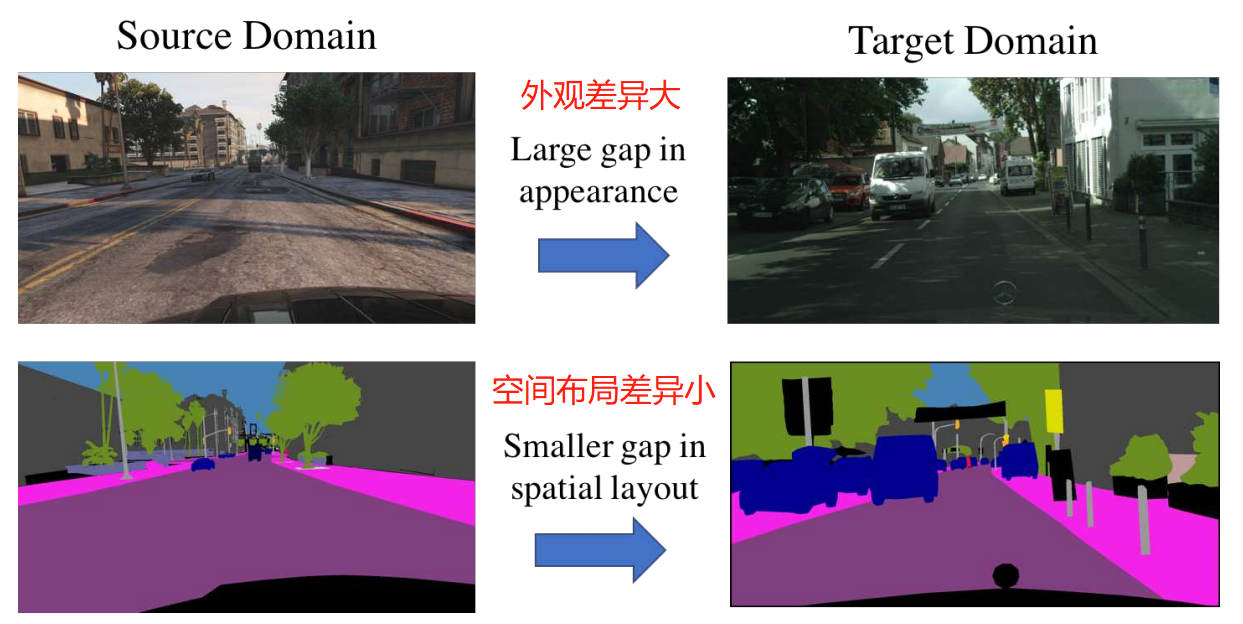 動機:來自不同域的圖片可能在外觀上有很大的不同,但是他們的分割輸出是結構化的,共享很多的相似性,比如空間佈局和區域性上下文。
動機:來自不同域的圖片可能在外觀上有很大的不同,但是他們的分割輸出是結構化的,共享很多的相似性,比如空間佈局和區域性上下文。
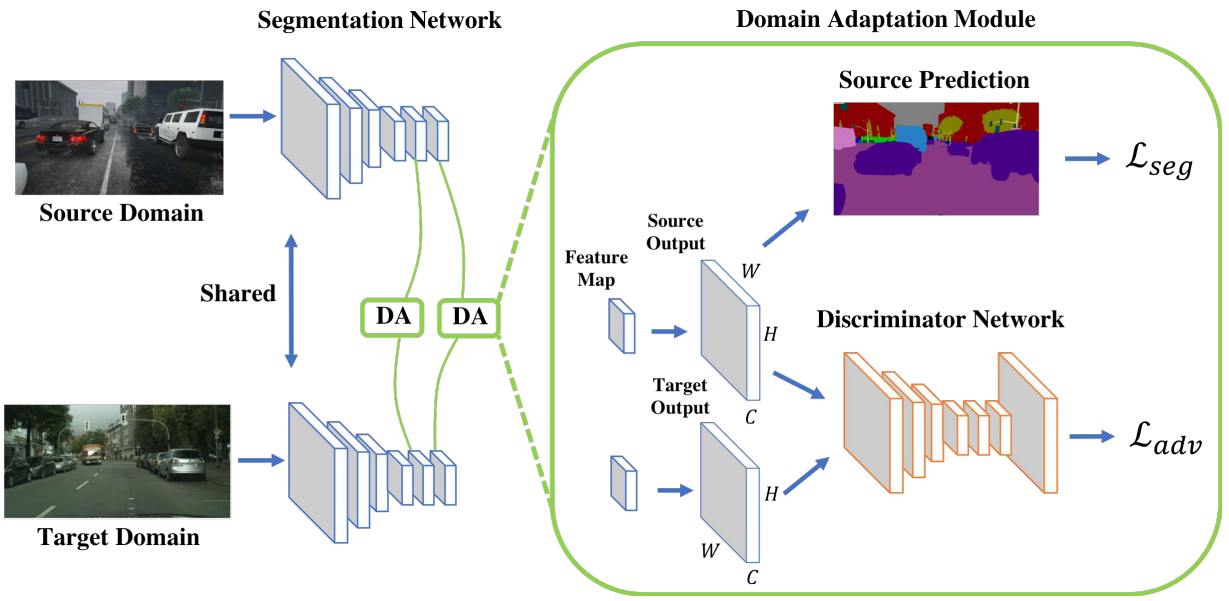
演算法概述:
1) 訓練分割網路:
源域和目標域給出大小為H×W的影象,我們將它們輸入分割網路以獲得輸出預測。 對於具有C類的源類預測,基於Ground Truth計算分割損失。
2)訓練判別網路:
為了使目標類預測更接近源類預測,我們利用判別器來區分輸入是來自源域還是目標域。
3)自適應過程:針對目標預測計算對抗損失,並將其反向傳播到分割網路。 我們將此過程稱為一個自適應模組,我們通過在兩個不同層面採用兩個自適應模組來說明我們提出的多層次對抗性學習。
體會:
如何理解分割任務上的域適應問題?
域適應的問題背景是兩個同類的資料集,由於光照、角度等不同,存在域差異(分佈不同)。今天,我們面對的是兩個分割的資料集D1和D2。在D1上訓練得到的模型,能不能直接用在D2上?顯然這是可以的,但是因為存在域差異(分佈差異),會導致域漂移。也就是D2的資料會更多的被判斷成D1場景下的資料,會導致一些分割錯誤。那怎麼來解決這個域漂移的問題呢?怎麼讓模型對D2的資料更具有判別力呢?怎麼減少源域和目標域的差異呢?
為什麼可以用GAN來實現DA?
本文的思想就是用對抗學習來縮小源域和目標域的域差異(分佈差異)。減小分佈之間的差異,是GAN擅長的事情。而在分割任務中,輸出空間的分割輸出結果,不同的資料集對應的分割輸出結果,存在分佈差異。我們猜測,作者就是通過實驗來證明了,在分割結果上用GAN進行學習,可以縮小源域和目標域之間的差異。而直接在分割結果上進行對抗學習,是在比較高層的結果上減小域差異;而多層的DA其實就是融合了低層和高層的特徵進行學習的一個過程。
本文和傳統域適應的區別
從任務上看,傳統DA在分類任務上提升分類任務的準確率。作用在特徵上。
而本文是在分割任務上使用DA的策略來提升分割的效果。作用在分割輸出結果上。
模型中判別器反傳的是什麼?
是目標域的分割結果和源域的分割結果之間的差異,反傳到分割網路進行調參,目的就是讓分割網路預測的目標域的分割結果更像源域。判別器的目的是獲得源域和目標域,在輸出空間也就是分割結果上的,分佈差異,通過判別器將這個差異反傳給分割網路,讓分割網路將目標域的圖片分割的剛好,也就是更像源域的分割結果。從而,實現減小域差異的目的。
關於任務關係的思考
在相同資料上,任務A(分類)的能不能遷移到任務B(分割)上?如何遷移?任務A和任務C的遷移效果怎麼比較和度量?
關於在分割上繼續做域適應的思考
本文是在分割的輸出空間做對抗學習,來縮小源域和目標域的分佈差異,提升分割的效果。分割任務的整個架構中,除了輸入空間、輸入空間,還有什麼地方存在域適應的場景?或者還有什麼資訊可以使用?比如弱監督的分割能不能用遷移學習的思想?
兩個點
1. 使用結構資訊:如將街景分割成上下兩部分,更細節的對抗學習
2. 使用不同的loss函式,傳統的GAN的loss知判斷真假。如perception loss讓GAN關注與內容的對抗學習
2.2 CVPR 18-Fully Convolutional Adaptation Networks for Semantic Segmentation
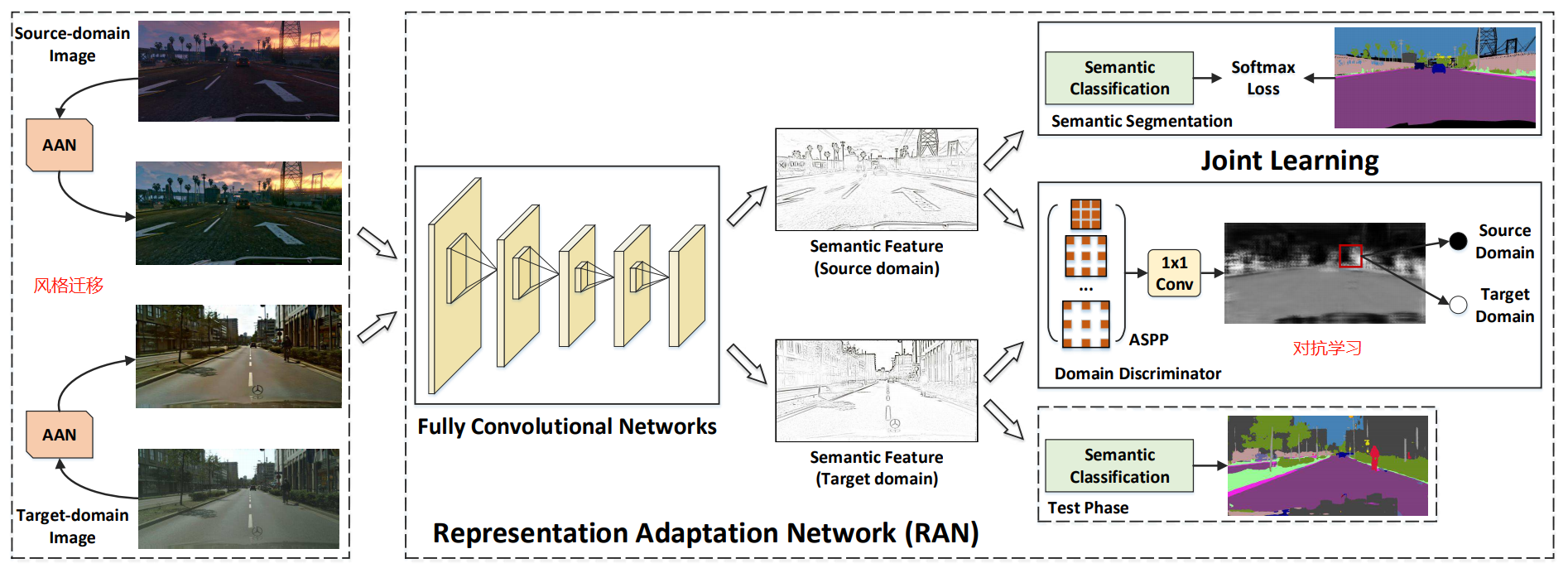
架構概述:
1) AAN:進行一個風格遷移,使得兩個域的圖片從外觀上具有域不變的性質。
2) RAN:進行對抗學習,使得判別器無法區分學到的表示來自源域還是目標域。
2.3 ECCV 18-Domain Adaptation for Semantic Segmentation via Class-Banlanced Self-Training

左圖:自訓練流程(類似於語義分割中的種子生成的方法),一次迭代過程,包括在源域上訓練模型,對目標域預測得到偽標籤,修改k值,繼續迭代。
塊座標下降演算法:
- a) 固定網路引數 ,最小化公式(3)的Loss,優化
- b) 固定網路引數 ,最小化公式(3)的Loss,優化
右圖:Cityscapes資料集的語義分割結果,域適應前vs域適應後
- 域適應中的分佈不同是什麼意思?
答:可以用流形解釋。源域和目標域,在低維子流形空間中很近,但存在差異。- (遷移學習中)什麼場景適合使用自訓練的方法?
答:目標域資料量大,源域和目標域差異小。- 論文中是如何控制自訓練的方向的?(種子是如何生長的)
答: 使用課程學習的策略,由易到難。- 懲罰項裡的k,在實驗中的變化?
答:k是根據經驗值p計算得來的。實驗中,一共進行了7次迭代,p的值從20%到50%。每一輪得到k之後,對新的預測結果進行偽標籤標記。
3. 總結
- 自適應語義分割的域:域適應的域指的是一個領域,類似於聚類中的簇。通常,域適應的文章中的實驗是針對分類任務的,某個類別就可以看作是一個領域。但是在分割任務中,一個域指的是一種分割場景,比如街道場景、遊戲街道場景。這裡的場景中包含多種類別的物體,但是就分割任務而言,一個領域指的是一個場景。
- 自適應語義分割的訓練策略:對抗訓練(Adversarial-Training)和自訓練(Self-Training)。
- 自適應語義分割的基礎架構修改策略:輸入空間、輸出空間的域適應。