
ElasticSearch最佳入門實踐(四十四)手動建立和修改mapping以及定製string型別資料是否分詞
1、如何建立索引
如果想設定 string 為分詞
把它設定為 analyzed
not_analyzed 則是 設定為 exact value 全匹配
no 則 是不能被索引和匹配
2、修改mapping
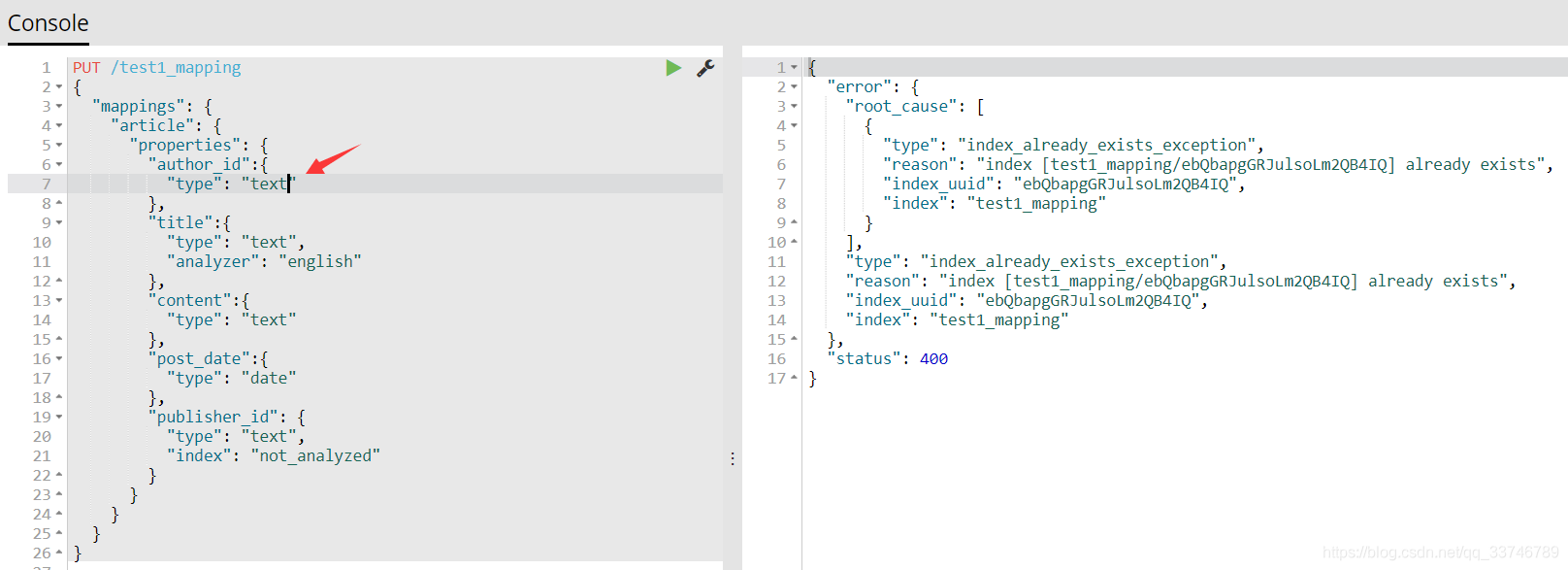
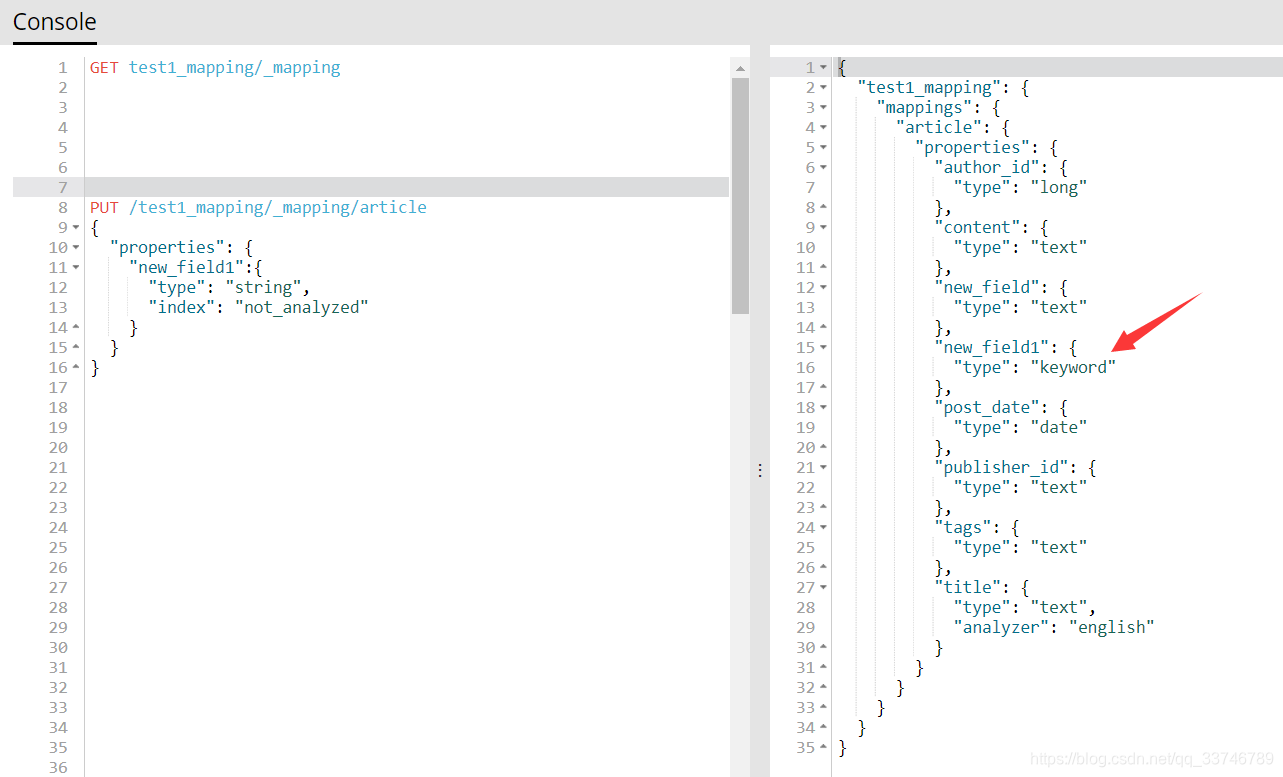
注意事項:只能建立index時手動建立mapping,或者新增field mapping,但是不能 update field mapping
建立
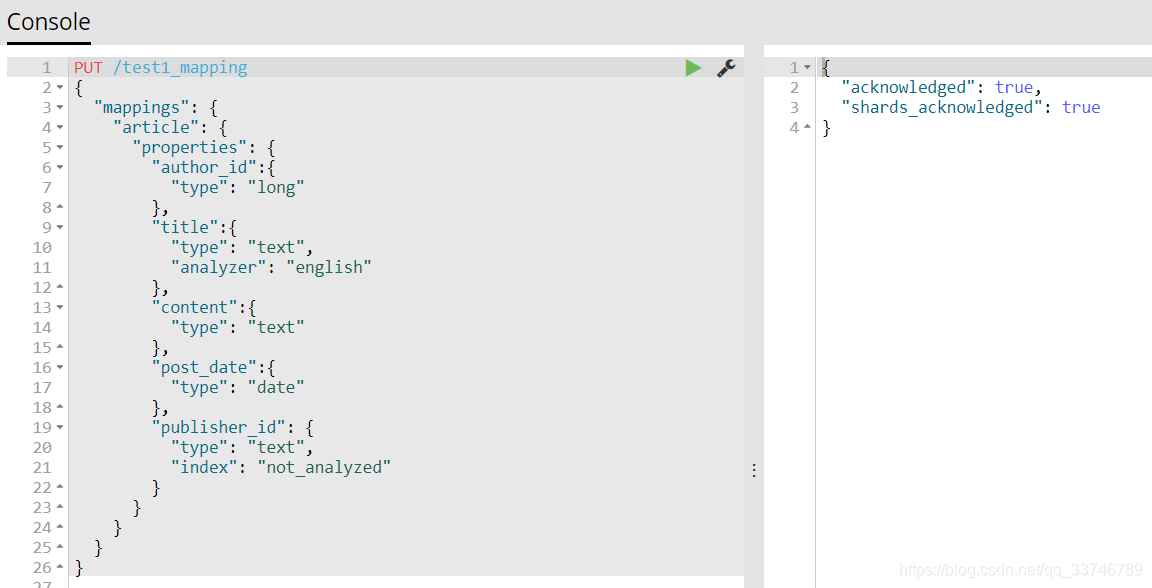
修改會報錯
新增一個field

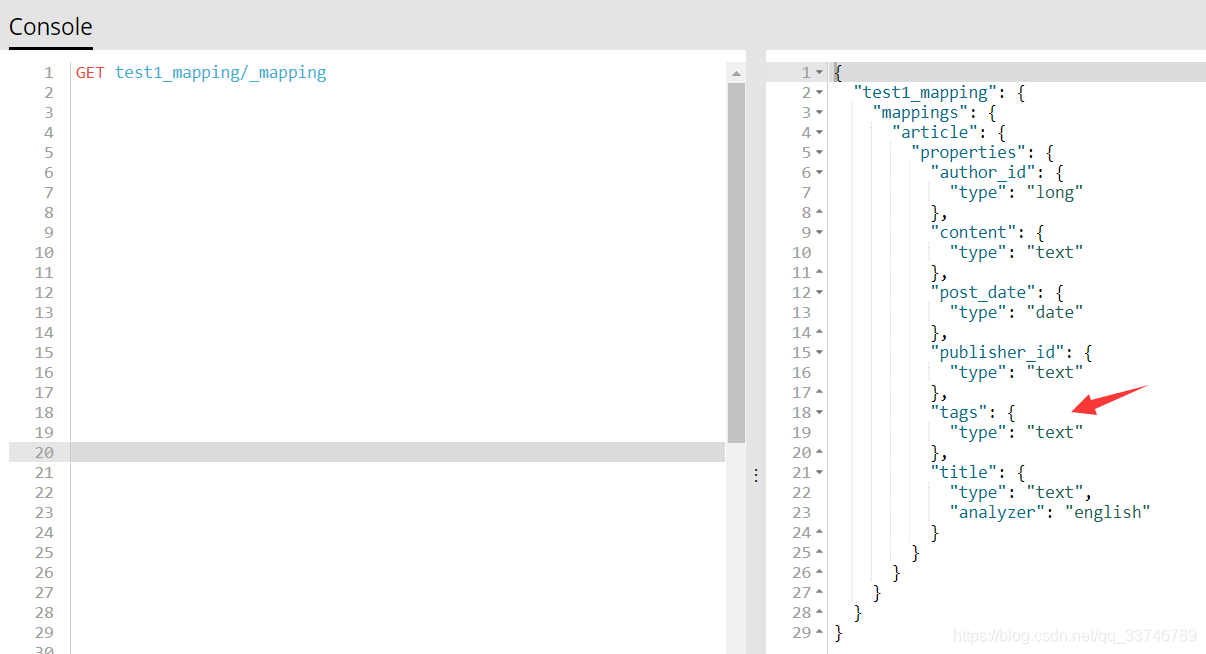
檢視
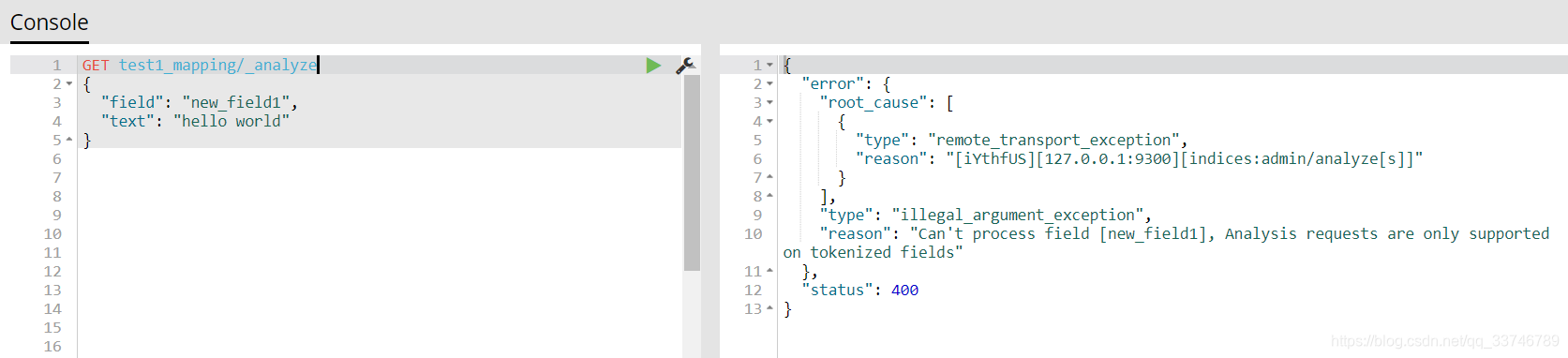
建立不會被分詞的field
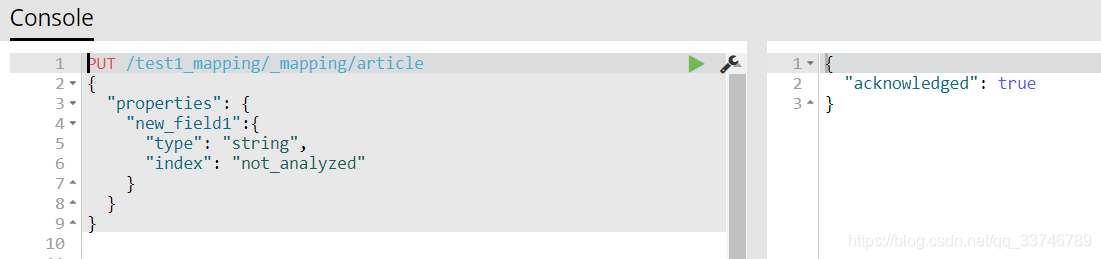
測試
相關推薦
ElasticSearch最佳入門實踐(四十四)手動建立和修改mapping以及定製string型別資料是否分詞
1、如何建立索引 如果想設定 string 為分詞 把它設定為 analyzed not_analyzed 則是 設定為 exact value 全匹配 no 則 是不能被索引和匹配 2、修改mapping 注意事項:只能建立index時手動建立mapp
ElasticSearch最佳入門實踐(三十四)multi-index & multi-type 搜尋模式解析以及搜尋原理解析
1、multi-index 和 multi-type 搜尋模式 告訴你如何一次性搜尋多個 index 和多個 type 下的資料 /_search:所有索引,所有type下的所有資料都搜尋出來 /index1/_search:指定一個ind
ElasticSearch最佳入門實踐(二十四)partial update樂觀鎖併發控制原理以及相關操作
(1)partial update內建樂觀鎖併發控制 partial update內部是自動執行之前所說的樂觀鎖的併發控制方案 兩個執行緒 都拿到了document資料和_version 使用傳過來的field更新document 執行緒B也在做partial update
ElasticSearch最佳入門實踐(五十四)相關度評分 TF & IDF 演算法解密
1、演算法介紹 relevance score演算法,簡單來說,就是計算出,一個索引中的文字,與搜尋文字,他們之間的關聯匹配程度 Elasticsearch使用的是 term frequency / inverse document frequency演算法
ElasticSearch最佳入門實踐(六十四)索引管理_定製化自己的dynamic mapping
1、定製dynamic策略 true:遇到陌生欄位,就進行dynamic mapping false:遇到陌生欄位,就忽略 strict:遇到陌生欄位,就報錯 定製 PUT /my_index { "mappings": { "my_t
ElasticSearch最佳入門實踐(三十九)倒排索引核心原理揭祕
1、例子,兩段文字 doc1:I really liked my small dogs, and I think my mom also liked them doc2:He never liked any dogs, so I hope that my m
ElasticSearch最佳入門實踐(三十八)精確匹配與全文搜尋的對比分析
1、ES中的兩種搜尋模式 1、exact value 2、full text 2、exact value 2017-01-01,exact value,搜尋的時候,必須輸入2017-01-01,才能搜尋出來。如果你輸入一個01,是搜尋不
ElasticSearch最佳入門實踐(三十七)用一個例子告訴你 mapping 到底是什麼
1、插入幾條資料 PUT /website/article/1 { "post_date": "2017-01-01", "title": "my first article", "content": "this is my first article in this w
ElasticSearch最佳入門實踐(三十六)query string search 語法以及 _all metadata 原理揭祕
1、query string基礎語法 GET /test_index/test_type/_search?q=test_field:test GET /test_index/test_type/_search?q=+test_field:test
ElasticSearch最佳入門實踐(三十五)分頁搜尋以及deep paging效能問題深度揭祕
1、如何使用es進行分頁搜尋的語法 size,from GET /_search?size=10 GET /_search?size=10&from=0 GET /_search?size=10&from=20 假設將這6條資料分成3頁,每一頁是2
ElasticSearch最佳入門實踐(三十二)bulk api的奇特json格式與底層效能優化關係揭祕
1、bulk api奇特的json格式 {"action": {"meta"}}\n {"data"}\n {"action": {"meta"}}\n {"data"}\n 2、bulk中的每個操作都可能要轉發到不同的node的shard去執行 3、如果採用比較良好的js
ElasticSearch最佳入門實踐(三十一)document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node 對於讀請求,不一定所有的請求都發送的primary shard 上去,也可以轉發到replied shard 上去,因為replied shard 也是可以服務所有讀請求的 2、coordin
ElasticSearch最佳入門實踐(二十九)document增刪改內部原理揭祕
步驟 (1)客戶端選擇一個node傳送請求過去,這個node就是coordinating node(協調節點) (2)coordinating node,對document進行路由,將請求轉發給對應的node(有primary shard) (3)實際的node上的prima
ElasticSearch最佳入門實踐(二十八)剖析document資料路由原理
1、document路由到shard上是什麼意思? 我們這段,一個index的資料會被分為多片,每個片都在一個shard中,所以說,一個document存在於一個shard中 當客戶端建立的時候,es此時就需要決定說,這個document存在於那個shard上。 這個過程就稱
ElasticSearch最佳入門實踐(二十五)mget批量查詢api
1、批量查詢的好處 就是一條一條的查詢,比如說要查詢100條資料,那麼就要傳送100次網路請求,這個開銷還是很大的 如果進行批量查詢的話,查詢100條資料,就只要傳送1次網路請求,網路請求的效能開銷縮減100倍 2、mget的語法 可以說mget是很重要
ElasticSearch最佳入門實踐(二十七)總結以及什麼是distributed document store
1、總結 快速入門了一下,最基本的原理,最基本的操作 在入門之後,對ES的分散式的基本原理,進行了相對深入一些的剖析 圍繞著document這個東西,進行操作,進行講解和分析 2、什麼是distributed document s
ElasticSearch最佳入門實踐(二十六)bulk批量增刪改
1、bulk語法 POST /_bulk { “delete”: { “_index”: “test_index”, “_type”: “test_type”, “_id”: “3” }} { “create”: { “_index”: “test_index”, “_typ
ElasticSearch最佳入門實踐(六十九)優化寫入流程實現durability可靠儲存(translog,flush)
(1)資料寫入buffer緩衝和translog日誌檔案 (2)每隔一秒鐘,buffer中的資料被寫入新的segment file,並進入os cache,此時segment被開啟並供search使用 (3)buffer被清空 (4)重複1~3,新的segment不斷新增,buf
ElasticSearch最佳入門實踐(六十八)優化寫入流程實現NRT近實時(filesystem cache,refresh)
現有流程的問題,每次都必須等待fsync將segment刷入磁碟,才能將segment開啟供search使用,這樣的話,從一個document寫入,到它可以被搜尋,可能會超過1分鐘!!!這就不是近實時的搜尋了!!!主要瓶頸在於fsync實際發生磁碟IO寫資料進磁碟,是很耗時的。
ElasticSearch最佳入門實踐(七十二)Java 實戰 - 對員工資訊進行復雜的搜尋操作
需求: (1)搜尋職位中包含technique的員工 (2)同時要求age在30到40歲之間 (3)分頁查詢,查詢第一頁 1、構建員工資訊 public class EmployeeSearchApp { public static void main