
用計算路由的方法優化BI後臺效能
問題的提出
BI 系統的常見結構是:前端是 BI 應用,負責多維分析的使用者操作和結果呈現;後臺是資料庫 / 資料倉庫,負責資料計算和儲存。前端和後臺之間用 SQL 作為介面。
實際應用中,常常出現後臺資料倉庫壓力過重的問題。問題表現為前端響應時間過長,資料倉庫反應速度變慢。
常見的解決方案是在資料倉庫和應用之間再增加一個前置資料庫。但是前置資料庫和後臺資料倉庫之間很難實現資料的路由和混合計算,例如:訪問頻次很高的熱點資料放在前置資料庫,大量冷資料放在資料倉庫中,查詢時按照一定規則來決定訪問前置資料庫還是後臺資料倉庫。而如果前置資料庫和後臺資料倉庫是不同的產品,還要考慮 SQL 的翻譯問題。
解決思路與過程
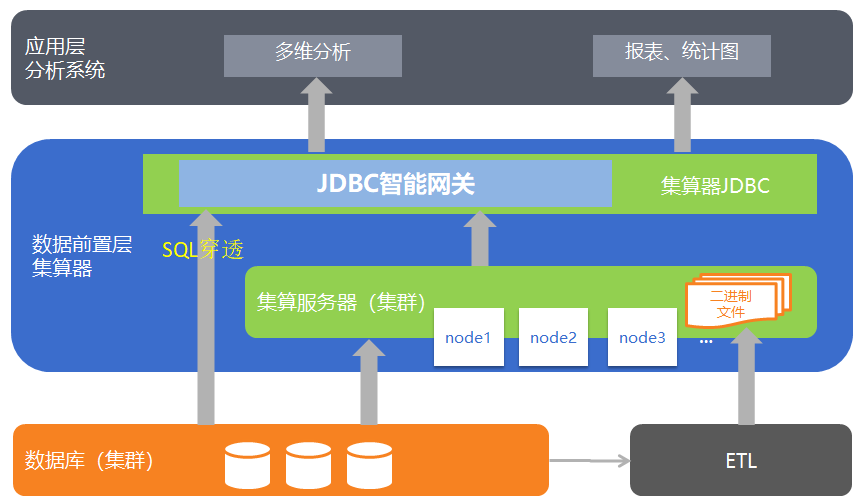
作為資料計算中介軟體(DCM),構建獨立的資料前置層是集算器的重要應用模式。資料前置層將 BI 系統重構為三層結構:資料儲存及批量資料計算層由資料庫承擔;資料前置及快取層由集算器承擔;資料分析展現層由多維分析工具或者報表工具承擔。
集算器可以脫離資料庫進行資料快取和獨立的複雜計算,同時具備可程式設計閘道器機制,可以在快取計算和 SQL 透傳之間自由切換。利用集算器完成前置層資料計算,可以與資料庫承擔的批量資料計算任務分離,並且不必再建設另外一個數據庫。
集算器可以將熱點資料、近期資料放在資料前置層,從而起到資料快取的作用,可以有效提高資料計算的速度,減少使用者等待時間。
系統架構圖如下:
案例場景說明
前臺 BI 系統,要針對訂單資料做自助查詢。查詢的必選條件是訂購日期。為了簡化起見,前臺 BI 系統用 tomcat 伺服器中的 jdbc.jsp 來模擬。
集算器 JDBC 和智慧閘道器整合在應用系統中。jdbc.jsp 模仿 BI 應用系統,產生符合集算器簡單查詢規範的 SQL,通過集算器 JDBC 提交給集算器智慧閘道器處理。
資料來自於 ORACLE 資料庫 demo 中的 ORDERS 表。ORDERS 訂單表是全量資料,集算器只儲存最近三年的資料,比如:2015 年 -2018 年。日期以訂購日期為準。
基礎資料準備與提取快取資料
用下面的 orders.sql 檔案在 ORACLE 資料庫中完成 ORDERS 表的建表和資料初始化。
在集算器中,新建一個數據源 orcl,連線 ORACLE 資料庫。用 SPL 語言指令碼 etl1.dfx 將最近三年的資料預先讀取到集算器集檔案 orders.btx 中。SPL 指令碼如下:
| A | B | |
|---|---|---|
| 1 | =year(now())-3 | |
| 2 | =connect(“orcl”) | [email protected](“select * from orders where to_char(orderdate,‘yyyy’)>=?”,A1) |
| 3 | =file(“C:/tomcat6/webapps/gateway/WEB-INF/data/orders.btx”) | |
| 4 | [email protected](B2) | >A2.close() |
從 SPL 指令碼可以看出,只要在 A4 單元格中用一句 export 就可以將資料庫中的資料匯出到檔案中。集檔案是集算器內建的二進位制檔案格式,採用了簡單壓縮機制,相同資料量比資料庫的佔用空間會更小。@z 選項表示寫出可以分段的檔案,很適合常常需要並行的多維分析類運算。
B2 單元格中資料庫遊標的 @d 選項,表示從 ORACLE 資料庫中取數的時候將 numeric 型資料轉換成 double 型,精度對於金額這樣的常見數值完全足夠了。如果沒有這個選項就會預設轉換成 big decimal 型資料,計算效能會受到較大影響。
指令碼可以用 windows 或者 linux 命令列的方式執行,結合定時任務,可以定時執行批量任務。windows 命令列的呼叫方式是:
C:\Program Files\raqsoft\esProc\bin>esprocx.exe C: \etl1.dfx
linux 命令是:
/raqsoft/esProc/bin/esprocx.sh /gateway/etl1.dfx
解決辦法一:應用伺服器整合計算
集算器 JDBC 智慧閘道器接收到 SQL 後,轉給 gateway1.dfx 程式處理。gateway1.dfx 判斷是否三年內的查詢,如果是,就把表名換成檔名,查本地檔案 orders.btx 返回結果。如果不是,把 SQL 轉換成 ORACLE 格式,提交資料庫處理。
1、下面的 gateway 目錄複製到 tomcat 的應用目錄。
目錄結構如下圖:
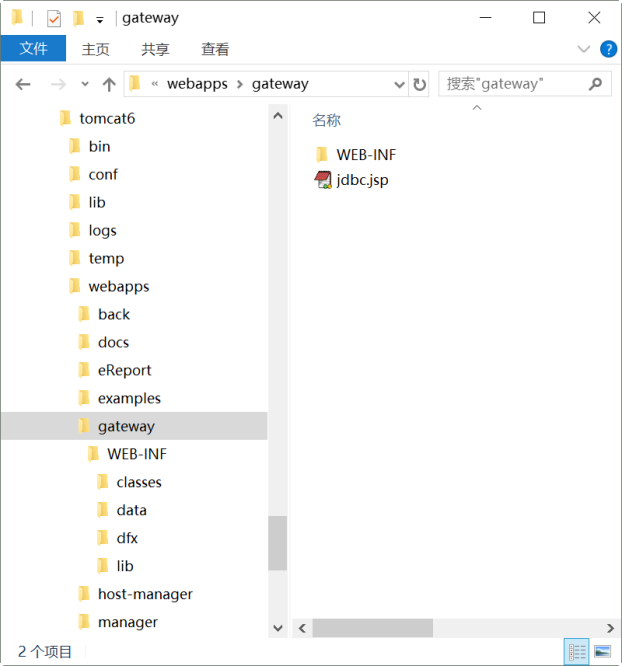
注意:配置檔案在 classes 中,在官網上獲取的授權檔案也要放在 classes 目錄中。集算器的 Jar 包要放在 lib 目錄中(需要哪些 jar 請參照集算器教程)。另外,還需要檢查和修改 raqsoftConfig.xml 中的如下配置:
<mainPath>C:\\\tomcat6\\\webapps\\\gateway\\\WEB-INF\\\dfx\\</mainPath> <JDBC> <load>Runtime,Server\\</load> <gateway>gateway1.dfx\\</gateway> </JDBC> <mainPath>C:\\tomcat6\\webapps\\gateway\\WEB-INF\\dfx\</mainPath> <JDBC> <load>Runtime,Server\</load> <gateway>gateway1.dfx\</gateway> </JDBC><mainPath>C:\\\tomcat6\\\webapps\\\gateway\\\WEB-INF\\\dfx\\</mainPath><JDBC><load>Runtime,Server\\</load><gateway>gateway1.dfx\\</gateway> </JDBC> <mainPath>C:\\tomcat6\\webapps\\gateway\\WEB-INF\\dfx\</mainPath><JDBC><load>Runtime,Server\</load><gateway>gateway1.dfx\</gateway></JDBC>
這裡標籤的內容就是閘道器 dfx 檔案。在 BI 系統中呼叫集算器 JDBC 時,所執行的 SQL 都將交由閘道器檔案處理。如果不配置這個標籤,JDBC 提交的語句都被集算器當作指令碼直接解析運算,而無法實現希望的路由規則。
2、編輯 gateway 目錄中的 jdbc.jsp,模擬前臺介面提交 sql 展現結果。
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\\://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";
out.println("Data gateway test page v1 <br><br><br><pre>");
out.println("訂單ID"+"\\\t"+"客戶ID"+"\\\t"+"僱員ID"+"\\\t"+"訂購日期"+"\\\t"+"訂單金額"+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\\\t"+f2+"\\\t"+f3+"\\\t"+f4+"\\\t"+f5+"\\\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";
out.println("Data gateway test page v1 <br><br><br><pre>");
out.println("訂單ID"+"\\t"+"客戶ID"+"\\t"+"僱員ID"+"\\t"+"訂購日期"+"\\t"+"訂單金額"+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\\t"+f2+"\\t"+f3+"\\t"+f4+"\\t"+f5+"\\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body><%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\\://";try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";out.print
ln("Data gateway test page v1 <br><br><br><pre>");out.println("訂單ID"+"\\\t"+"客戶ID"+"\\\t"+"僱員ID"+"\\\t"+"訂購日期"+"\\\t"+"訂單金額"+"<
br>");
ResultSet rs = statement.executeQuery(sql);int f1,f6;
String f2,f3,f4;float f5;while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");out.println(f1+"\\\t"+f2+"\\\t"+f3+"\\\t"+f4+"\\\t"+f5+"\\\t"+"<br>");
}out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\://";try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100"
;out.print
ln("Data gateway test page v1 <br><br><br><pre>");out.println("訂單ID"+"\\t"+"客戶ID"+"\\t"+"僱員ID"+"\\t"+"訂購日期"+"\\t"+"訂單金額"+"<br>");
ResultSet rs = statement.executeQuery(sql);int f1,f6;
String f2,f3,f4;float f5;while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");out.println(f1+"\\t"+f2+"\\t"+f3+"\\t"+f4+"\\t"+f5+"\\t"+"<br>");
}out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
可以看到,jsp 中先連線集算器的 JDBC,然後提交執行 SQL。步驟和一般的資料庫完全一樣,具有很高的相容性和通用性。對於 BI 工具來說,雖然是介面操作來連線 JDBC 和提交 SQL,但是基本原理和 jsp 完全一樣。
3、開啟 dfx 目錄中的 gateway1.dfx,觀察理解 SPL 程式碼。
首先,可以看到 gateway1.dfx 傳入引數是 sql 和 args,例如傳入 SQL:
select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(‘2015-07-18’) and AMOUNT>100。
接下來,可以看到 SPL 指令碼如下:
| A | B | C | |
|---|---|---|---|
| 1 | =filename=“C:/tomcat6/webapps/gateway/WEB-INF/data/orders.btx” | ||
| 2 | [email protected]().split(" ") | [email protected](like(~,“ORDERDATE=date(‘????-??-??’)”)) | |
| 3 | =mid(right(B2,14),3,10) | =year(now())-year(date(A3)) | |
| 4 | if B3<=3 | =connect() | =sql=replace(sql,“from ORDERS”,"from "+filename) |
| 5 | [email protected](sql) | return B5 | |
| 6 | else | =connect(“orcl”) | =sql=sql.sqltranslate(“ORACLE”) |
| 7 | [email protected](sql) | return B7 |
說明:
A1:定義集算器集檔案的絕對路徑。
A2:解析 SQL,獲取 where 子句,並用空格來拆分成序列。
B2、A3:在 A2 序列找到必選條件訂購日期,獲取日期值。
B3:計算訂購日期的年份和當前日期年份相差幾年。
A4:判斷相差的年份是否超過 3 年。
B4-C5:如果不超過 3 年,就連線檔案系統。將 SQL 中的 from 訂單,替換成 from 檔名。執行 SQL 得到遊標並返回。
B6-C7:如果超過 3 年,就連線資料庫。將 SQL 翻譯成符合 ORACLE 資料庫規範的 SQL, 執行 SQL 得到遊標並返回。
4、啟動 tomcat,在瀏覽器中訪問 http://localhost:8080/gateway/jdbc.jsp,檢視結果。

還可以繼續測試如下情況:
(1) 超出三年的查詢
sql =“select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(‘2014-07-18’) and AMOUNT>100”;
由於日期 2014 年已經超出三年的限制,所以在 C6 中 SQL 會被翻譯成 ORACLE 規範如下:
SELECT * FROM (select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=TO_DATE(‘2014-07-18’,‘YYYY-MM-DD’) and AMOUNT>100)t WHERE ROWNUM<=10
(2) 分組彙總
sql =“select CUSTOMERID,EMPLOYEEID,sum(AMOUNT) 訂單總額,count(1) 訂單數量 from ORDERS where ORDERDATE=date(‘2015-07-18’) group by CUSTOMERID,EMPLOYEEID”;
(3) 並行查詢
sql="select /*+ parallel (4) */
top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(‘2015-07-18’) and AMOUNT>100"
和 ORACLE 類似,集算器簡單 SQL 也支援 /*+ parallel (4) */ 這樣的並行查詢。
解決辦法二:獨立節點伺服器計算
第一種解決辦法是利用應用伺服器的資源。在併發量很大,或者資料量很大的情況下,應用伺服器會出現較大壓力。這種情況下,推薦用獨立的節點伺服器進行資料計算。節點伺服器可以進行橫向擴充套件,應對大併發或大資料量計算的壓力。
集算器 JDBC 智慧閘道器接受到 SQL 後,轉給 gateway2.dfx 程式處理。gateway2.dfx 呼叫節點伺服器上的 gatewayServer2.dfx 進行計算。gatewayServer2.dfx 判斷是否三年內的查詢,如果是,就把表名換成檔名,查本地檔案 orders.btx 返回結果。如果不是三年內的查詢,把 sql 轉換成 ORACLE 格式,提交資料庫處理。
1、下面的 gatewayServer 目錄複製到需要的目錄。集算器的節點伺服器具備跨平臺的特性,可以執行在任何支援 Java 的作業系統上,部署方法參見集算器教程。這裡假設放到 windows 作業系統的 C 盤根目錄。
2、修改前面的 dfx,將 A3 改為 =file(“C:/gatewayServer/data/orders.btx”),另存為 etl2.dfx。修改好的 etl2.dfx 在 c:\gatewayServer 目錄。
3、開啟應用伺服器中的 C:\tomcat6\webapps\gateway\WEB-INF\dfx\gateway2.dfx,觀察理解 SPL 程式碼。引數不變,還是傳入的 sql 和 args。
| A | B | |
|---|---|---|
| 1 | =callx(“gatewayServer2.dfx”,[sql];[“127.0.0.1:8281”]) | |
| 2 | return A1.ifn() |
A1:呼叫節點機上的 gatewayServer2.dfx。引數是 [sql],中括號表示序列,此時是隻有一個成員的序列。[“127.0.0.1:8281”] 是節點機的序列,採用 IP: 埠號的方式。節點機是叢集的時候,可以有多個 IP 地址,例如:["IP1:PORT1″,"IP2:PORT2″,“IP3:PORT3”]。
A2:返回 A1 呼叫的結果。因為呼叫結果可以是序列,所以要用 ifn 函式找到序列中第一個不為空的成員,就是 SQL 對應的返回結果。
修改 C:\tomcat6\webapps\gateway\WEB-INF\classes\raqsoftConfig.xml 中的如下配置 gateway1.dfx 改為 gateway2.dfx。
<JDBC> <load>Runtime,Server\\</load> <gateway>gateway2.dfx\\</gateway> </JDBC> <JDBC> <load>Runtime,Server\</load> <gateway>gateway2.dfx\</gateway> </JDBC><JDBC><load>Runtime,Server\\</load><gateway>gateway2.dfx\\</gateway></JDBC> <JDBC><load>Runtime,Server\</load><gateway>gateway2.dfx\</gate way></JDBC>
4、啟動節點伺服器。
執行 esprocs.exe, 如下圖:
點選配置按鈕,配置相關引數:
點選確定後,返回主介面,點選啟動按鈕。
5、開啟 C:\gatewayServer\dfx\gatewayServer2.dfx,觀察理解 SPL 程式碼。
| A | B | C | |
|---|---|---|---|
| 1 | =filename=“C:/gatewayServer/data/orders.btx” | ||
| 2 | [email protected]().split(" ") | [email protected](like(~,“ORDERDATE=date(‘????-??-??’)”)) | |
| 3 | =mid(right(B2,14),3,10) | =year(now())-year(date(A3)) | |
| 4 | if B3<=3 | =connect() | =sql=replace(sql,“from ORDERS”,"from "+filename) |
| 5 | [email protected](sql) | return B5 | |
| 6 | else | =connect(“orcl”) | =sql=sql.sqltranslate(“ORACLE”) |
| 7 | [email protected](sql) | return B7 |
程式碼基本和前面的 gateway1.dfx 一致。區別是這個 dfx 是在節點伺服器 unitServer 上執行的,資料是存在節點伺服器上。
5、重啟 tomcat,在瀏覽器中訪問 http://localhost:8080/gateway/jdbc.jsp,檢視結果。
解決辦法三:集算器組表計算
當資料量很大同時又需要秒級的查詢速度時,我們建議採用集算器組表來儲存資料。組表適用的場合包括:資料表字段有幾十個甚至更多;資料量幾千萬行,存成集檔案在 1G 以上;查詢要求秒級響應。
對於簡單 SQL 來說,組表文件的用法和集檔案沒有什麼不同, 只是檔名不一樣。gatewayServer2.dfx 中只需要把 A1 改為 =filename=“C:/gatewayServer/data/orders.ctx”,另存為 gatewayServer3.dfx。相應的 gateway2.dfx 中的 A1 改為 =callx(“gatewayServer3.dfx”,[sql];[“127.0.0.1:8281”]),另存為 gateway3.dfx。
修改 C:\tomcat6\webapps\gateway\WEB-INF\classes\raqsoftConfig.xml 中的如下配置 gateway2.dfx 改為 gateway3.dfx。
<JDBC> <load>Runtime,Server\\</load> <gateway>gateway3.dfx\\</gateway> </JDBC> <JDBC> <load>Runtime,Server\</load> <gateway>gateway3.dfx\</gateway> </JDBC><JDBC><load>Runtime,Server\\</load><gateway>gateway3.dfx\\</gateway></JDBC> <JDBC><load>Runtime,Server\</load><gateway>gateway3.dfx\</gate way></JDBC>
我們重點理解如何改寫 etl 過程,修改前面的 etl2.dfx,另存為 etl3.dfx。
| A | |
|---|---|
| 1 | =year(now())-3 |
| 2 | =connect(“orcl”) |
| 3 | [email protected](“select CUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERID,AMOUNT from ORDERS where to_char(ORDERDATE,‘yyyy’)>=? order by CUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERID",A1) |
| 4 | =file(“C:/gatewayServer/data/orders.ctx”) |
| 5 | =A4.create(#CUSTOMERID,#EMPLOYEEID,#ORDERDATE,#ORDERID,AMOUNT) |
| 6 | =A5.append(A3) |
| 7 | >A2.close() |
組表與集檔案不同,預設是採用列式儲存的,支援任意分段的平行計算,可以有效提升查詢速度。同時,生成組表的時候,要注意資料預先排序和合理定義維欄位。本例中,按照經常過濾、分組的欄位,將維欄位確定為:CUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERID。
A3 取得資料的時候,要按照維欄位排序。因為 CUSTOMERID,EMPLOYEEID,ORDERDATE 對應的重複資料多,所以放在前面排序;ORDERID 對應的重複資料少,所以放在後面排序。
A4 中定義組表的時候用 #來表示維欄位。
需要說明的是,組表也支援並行查詢 /*+ parallel (n) */。
多工效能調優技巧小結
BI 應用的特點是:
1、響應時間要求高,一般不超過 5-10 秒。
2、查詢對應資料量在幾百兆到幾 G 範圍,欄位有幾十個甚至上百個。
3、併發量較大,幾十到幾百個併發。
效能優化的方法是:
1、採用組表,提高單任務查詢的響應速度。
◇ 根據需求,合理定義維欄位。
組表定義的時候,要按照業務的需要確定維欄位。要選擇經常作為過濾條件或者用來分組的欄位作為維欄位,維欄位前用 #標識。
◇ 按照維欄位,預先排序。
要按照維欄位做好資料的排序,重複記錄數多的欄位在前面,例如:按照 order by 省,市,縣的欄位順序來排序,而不是反過來。
◇ 根據併發量,選擇是否用並行查詢。
併發量比較大的時候,單個 SQL 查詢就不建議用並行查詢了 /*+ parallel (n) */。並行查詢會消耗更多的執行緒數,反而會影響大的併發效能。
2、合理配置節點伺服器的引數,發揮每個節點的效能。
每臺伺服器(實體機或者虛擬機器)要啟動一個節點伺服器,每個節點伺服器啟動分機的配置介面如下:
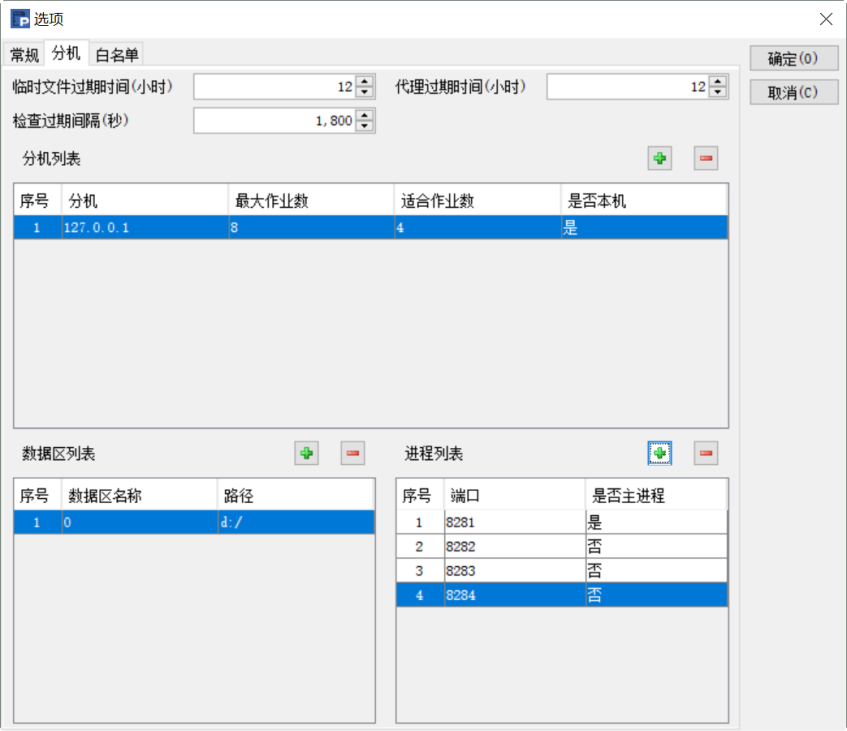
◇ 根據硬體資源,配置程序數
程序列表中的程序數(也就是適合作業數)建議是不要超過 CPU 總核數 *2/3。例如:伺服器有 8 個 CPU 每個兩核,總核數是 8*2=16,那麼程序數量就不要超過 16*2/3=10 個。最大作業數推薦是適合作業數 *2,也就是 10*2=20 個。
◇ 儘量多分配記憶體,但要避免超量
節點伺服器每個程序的最大記憶體要儘量多分配,但是總數加起來要比實際的實體記憶體小,避免作業系統用硬碟來補充記憶體的不足。例如,總記憶體是 32G,程序數量是 8 個,那麼每個程序的最大記憶體就不要大於 4G。配置程序的最大最小記憶體是在 C:\Program Files\raqsoft\esProc\bin\config.txt 中,例如:
jvm_args=-Xms128m -Xmx4845m 最小記憶體是 128M,最大是 4G。
3、橫向擴充套件節點伺服器,多機應對大併發訪問。
◇ 橫向擴充套件,應對大併發。
隨著併發量的增大,當效能不能滿足要求的時候,要增加節點伺服器的數量,通過橫向擴充套件來滿足需求。
◇ 增加伺服器列表配置項。
這時候要修改 gateway3.dfx 中的 callx 函式的伺服器序列引數。可以將伺服器序列引數寫到配置檔案中,這樣就可以不必每次都修改 dfx 檔案了。
4、使用本機硬碟資料進行計算,避免跨網路訪問。
硬碟的 IO 速度是比較有保證的。
節點伺服器通過網路去取其他伺服器上的資料,或者通過訪問共享儲存上的資料,經常會出現網路阻塞的情況,降低查詢響應速度。因此,儘可能每臺節點伺服器僅僅執行本機上的資料,不要跨網路訪問。
集算器優勢總結
可程式設計資料路由
可程式設計資料路由是資料計算中介軟體(DCM)的重要應用場景。
在前述的例子中,資料路由的策略是:最近三年的資料作為熱資料放路由到集算器中計算,其他資料作為冷資料,路由到資料庫中計算。
類似的路由規則還有:最近三天和最近十二個月的最後一天的資料作為熱資料,路由到集算器中計算,其他資料路由到資料庫彙總計算。
對於冷熱資料計算路由規則,本篇只介紹了一次查詢只涉及冷或熱資料的情況,如果在一次查詢中可能同時涉及冷熱兩種資料,我們將在後續文章中進行介紹。
實際應用中,資料路由的規則可能會很複雜和多變,通過配置來實現會非常困難,用程式設計的方式實現是最佳方案。採用集算器的程式語言 SPL 來實現複雜的資料路由規則是最簡單和最高效的。集算器支援多樣性異構資料來源的混合計算,可以程式設計實現涉及到各種異構資料來源的複雜資料路由規則。
SQL 解析與翻譯
用作多維分析後臺時,資料計算中介軟體(DCM)要提供必要的 SQL 解析與翻譯功能。
資料路由的實現離不開集算器對 SQL 語句的解析和翻譯。首先要用集算器的 SQL 解析能力,找到 where 條件中的日期欄位,然後根據規則來決定路由到檔案還是資料庫。如果是路由到資料庫,那麼要把集算器的標準 SQL 翻譯成資料庫的 SQL,就要用到集算器的 SQL 翻譯能力。
集算器的 SQL 解析用 sqlparse()函式實現,SQL 翻譯用 sqltranslate() 函式實現。
SQL 效能優化
SQL 效能優化也是資料計算中介軟體(DCM)必不可少的能力。
BI 應用允許使用者拖拽生成 SQL,就會出現很多效能不高的 SQL。比如直接在明細查詢的 SQL 外面加上一層 count 來統計結果總條數:select count(1) from (select f1,f2,f3,f4…f30 from table1 where f1=1 and 1=1)。此時子查詢中的 f1 到 f30 如果全部取出,就會降低查詢的效能。1=1 這樣的過濾條件也會造成沒有意義的時間消耗。
集算器簡單 SQL 引擎,可以完成自動查詢優化。去掉 1=1 這樣不必要的條件,也不會取出所有欄位來完成 count。從而實現 SQL 解析和優化,有效的提高查詢效能。
類似的,還有 select top 10 f1,f2 from table1 order by f1。集算器會採用小結果集比較的方式實現。可以做到無須大排序,只遍歷一邊資料即可得到需要的結果,有效提升查詢速度。
組表列存 / 有序壓縮儲存
先進的資料儲存方式,是資料計算中介軟體(DCM)成功實施的重要保障。
集算器組表採用列存方式儲存資料,對於欄位特別多的寬表查詢,效能提升特別明顯。組表採用的列存機制和常規列存是不同的。常規列存(比如 parquet 格式),只能分塊之後,再在塊內列存,在做平行計算的時候是受限的。組表的可並行壓縮列存機制,採用倍增分段技術,允許任意分段的平行計算,可以利用多 CPU 核的計算能力把硬碟的 IO 發揮到極致。
組表生成的時候,要指定維欄位,資料本身是按照維欄位有序存放的,常用的條件過濾計算不依賴索引也能保證高效能。檔案採用壓縮儲存,減小在硬碟上佔用的空間,讀取更快。由於採用了合適的壓縮比,解壓縮佔用的 CPU 時間可以忽略不計。
組表也可以採取行存和全記憶體儲存資料,支援記憶體資料庫方式執行。
叢集功能
敏捷的叢集能力可以保證資料計算中介軟體(DCM)的高效能和高可用性。
集算器節點伺服器是獨立程序,可以接受集算器閘道器程式的計算請求並返回結果。對於併發訪問的情況,可以發給多個伺服器同時計算,提高併發容量。對於單個大計算任務的情況,可以分成多個小任務,發給多個伺服器同時計算,起到大資料平行計算的作用。
集算器叢集計算方案,具備敏捷的橫向擴充套件能力,併發量或者資料量大時可以通過快速增加節點來解決。集算器叢集也具備容錯能力,即有個別節點失效時還能確保整個叢集能工作,計算任務能繼續執行完畢,起到多機熱備和保證高可用性的作用。
應用推廣
作為資料計算中介軟體(DCM),集算器實現的資料計算閘道器和路由,可以解決資料倉庫無法滿足效能要求,冷熱資料分開又要混合計算的場景,不僅僅限於前端是 BI 的情況。例如:大屏展示、管理駕駛艙、實時報表、大資料量清單報表、報表批量訂閱等等。