信用評分模型
信用評分卡資料建模
信用評分卡模型簡介
按業務使用階段:
- A卡貸前稽核使用申請評分卡模型(Application Score) 主要用於協助信用稽核人員將重心放在界於評分邊緣的進件上.
- B卡貸中監控使用行為評分卡(Behavior Score)屬於動態行為風險的預測,相對複雜,模型種類也多.
- C卡貸後催收評分模型(Collection Score) 多用在案件前期的催收.
以上三類信用評分卡主要應用於預測貸款人的還款概率.
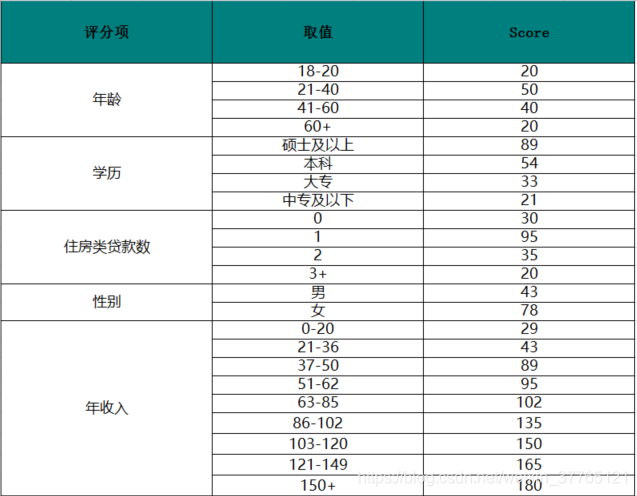
其中表(1-1)為常規的A卡(申請評分卡)樣例, 左邊欄位為評分卡的評分項,通常說的變數, 中間為評分項分佈區間, 右邊為當前評分項落在對應區間的得分.
表(1-1)
變數篩選
先從單變數評分計算過程開始.首先要計算WOE與IV,假如有歷史存量客戶資料近6個月提取10萬筆作為建模樣本,並抽取5000筆進行資料分組,以年收入為分析因子,5000筆資料儘量滿足以下條件
附歐洲持卡人於2013年9月通過信用卡進行的交易的原始資料15萬筆下載:https://download.csdn.net/download/weixin_37765121/10780612
- 分組資料佔比率不低於5%
- 好壞比例在區間 3:1-5:1
- 組間差異大,組內差異小
好(Good)壞(Bad)界線劃分業務場景而定,通常會以M3之前結清的標為Good,M3之後標為Bad.實際應用中Bad數量達不到比例範圍時,也有對應的拒絕推論處理方式來解決樣本數.樣本資料準備好後,可以選擇某個變數進行分組,並計算各組好壞佔比.實際應用是樣本資料可能存在異常值與缺失值的問題,常規分兩種處理方式 - 1:刪除含有缺失值的個案
- 2:可能值插補缺失值
為了建模的有效性,選擇可能值插補缺失值比較常見,畢竟現在這類資料處理工具比較多,如可採用Python 編寫隨機森林對缺失值預測填充函式,對於缺失值處理方式還是專門的課題.實際應用中缺失值填充方法依據情況進行多論探討,並對填充值的有效性進行不斷驗證.
附上缺失值預測填充指令碼
# 用隨機森林對缺失值預測填充函式 def set_missing(df): # 把已有的數值型特徵取出來 process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]] # 分成已知該特徵和未知該特徵兩部分 known = process_df[process_df.MonthlyIncome.notnull()].as_matrix() unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix() # X為特徵屬性值 X = known[:, 1:] # y為結果標籤值 y = known[:, 0] # fit到RandomForestRegressor之中 rfr = RandomForestRegressor(random_state=0, n_estimators=200,max_depth=3,n_jobs=-1) rfr.fit(X,y) # 用得到的模型進行未知特徵值預測 predicted = rfr.predict(unknown[:, 1:]).round(0) print(predicted) # 用得到的預測結果填補原缺失資料 df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted return df
繼續正題,如表(1-2) 5000樣本中資料中已經對年收入變數進行分組並計算出對應的WOE(證據權重)值和IV值,其中WOE 計算邏輯為正常件佔比除以違約件佔比的自然數對數.
表(1-2)
如果違約件數高於正常件時 WOE 值為負數, 絕對值也越大,代表當前分組中的Good與Bad客戶區隔程度越高,分組的合理性這個時候應看各組間WOE值差距是否拉開,並呈現由小到大的趨勢如表(1-2)基礎符合以由小到大.那就可以進行下一步驟的計算IV值.IV值的分佈情況決定變數預測能力,IV值計算邏輯是正常件佔比減違約件佔比乘以證據權重值,各組的IV彙總後得到當前變理的IV值為0.309.

WOE 和 IV計算公式如下:
N表示正常進件佔比,P為違約進件佔比,n為資料分組數.

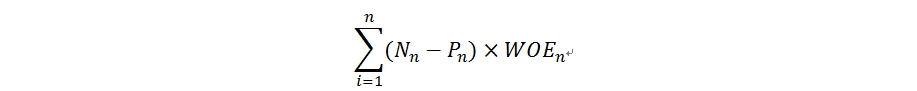
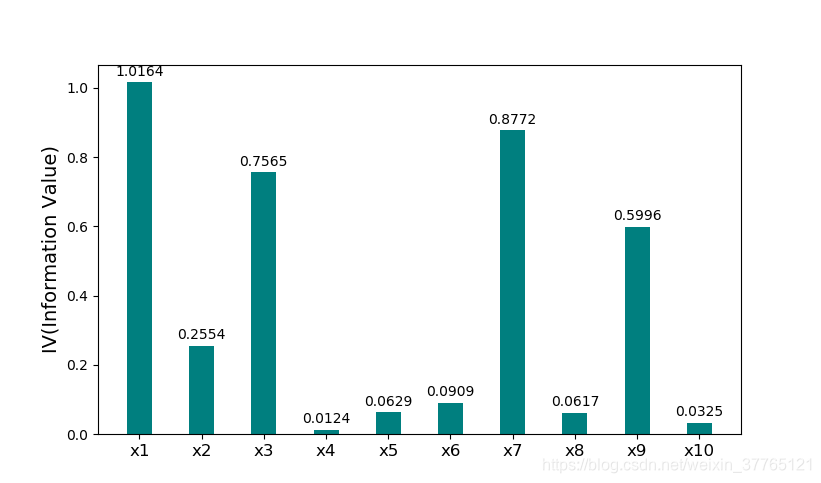
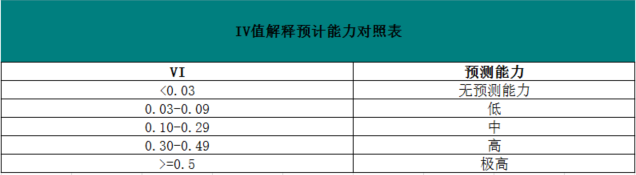
以本例來看IV 值在0.30與0.49區間,說明年收入的預測能力相對強.通常為了提高IV值還需要對分組進行合併,對WOE值相近的組進行合併,重新計算IV值,也可使用順向進入法,反向排除法和逐步迴歸法等等,目的是為了能選擇出最佳的組別.組別在這步驟確定後,對最終的評分卡對應的變數的評分割槽間劃分就在資料箱確定好了.實際應用類似職業類別,性別,學歷已經是天然的組了,不需要作複雜的組別劃分計算.
實際應用中如果用Excel計算IV過程比較費力,一般都需要藉助工具,比如Python 指令碼簡單實現所選變數IV計算如圖(2-1).
#自定義分箱函式
def self_bin(Y,X,cat):
good=Y.sum()
bad=Y.count()-good
d1=pd.DataFrame({'X':X,'Y':Y,'Bucket':pd.cut(X,cat)})
d2=d1.groupby('Bucket', as_index = True)
d3 = pd.DataFrame(d2.X.min(), columns=['min'])
d3['min'] = d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe'] = np.log((d3['rate'] / (1 - d3['rate'])) / (good / bad))
d3['goodattribute'] = d3['sum'] / good
d3['badattribute'] = (d3['total'] - d3['sum']) / bad
iv = ((d3['goodattribute'] - d3['badattribute']) * d3['woe']).sum()
#d4 = (d3.sort_index(by='min'))
d4 = (d3.sort_values(by='min'))
print("=" * 60)
print(d4)
woe = list(d4['woe'].round(3))
return d4, iv,woe
可能參考表(1-3)IV值解釋能力表對照表,
表(1-3)
計算單項評分值
從統計學角度看理論上最佳的信用評分卡是可以完全區分好壞客戶,但實際應用壞客戶佔比通常偏底,難以凸顯風險因子的特徵.在抽取樣本時會刻意拉高到壞客戶佔比,好壞比率約為3:1-5:1.開發樣本與測試樣本一般三七開,70%用於模型建立,30%用於模型形成後驗證. 接下來通過邏輯迴歸計算各變數的迴歸係數並轉換為最終的評分值.
公式為: Score = ln(Odds)xScale+Location
(其中Odds 為好壞比)
- (1) 設定Odds = 1:1 時的分數為600分
- (2) 設定Odds 每增加1倍時相對增加20分
- (3) 最終轉換分數公式為 Score = ln(Odds)x(20/ln(2))+600
當然實際應用不會這麼簡單會複雜很多,先不提需專業統計學技術,就拿獲取資料這項來聊,尤其近幾年的興起的p2p 小貸公司,產品迭代快,資料少,還缺失.又如刷資料,打混了資料生命週期,被混在資料樣本中難以識別.
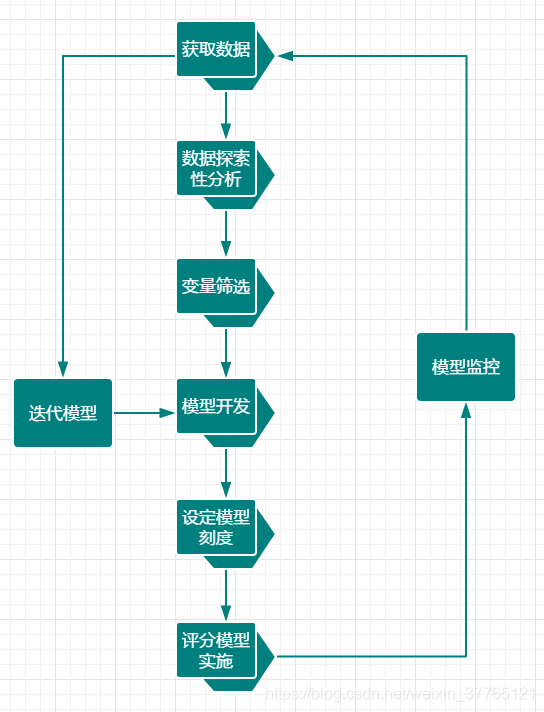
總體來講商業資料信用建模是會立為一個專案來開展評分模型的建立,其階段複雜,干係部門比較多,需各部門提供支援,基本會如圖(2-2)的過程.
圖(2-2)