
信用評分模型診斷指數
原文連結:http://blog.csdn.net/lihui6636/article/details/46738557
1. 一般統計量
均值、方差、最小值、最大值、1%分位數、5%分位數、 10%分位數、25%分位數、 50%分位數、75%分位數、90%分位數、 95%分位數、 99%分位數。
一般要將資料排序後才能求得分位數。
1.1 對每個Model(SEG_A、SEG_B、SEG_C、ALL),計算score向量的統計量
1.2 對SEG_A、SEG_B、SEG_C、ALL,計算每signal向量的統計量2. Pearson相關係數
其公式為:
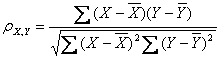
其中:
0.8-1.0 極強相關
0.6-0.8 強相關
0.4-0.6
0.2-0.4 弱相關
0.0-0.2 極弱相關或無相關
3.PSI
PSI(Population Stability Index)是衡量模型的預測值與實際值偏差大小的指標。PSI 小於 0.25 意味偏差在可以接受的範圍裡。

3.1 對每個Model(SEG_A、SEG_B、SEG_C),計算score向量的PSI(1). 將基準score劃分為10個區間,將預測score按照相同的邊界值劃分為10個區間(2). 分別統計各個分割槽基準score的個數C1、預測score的個數C2

(2).對於離散型變數離散變數本身就是分類的,只需要按照時間維度分組,然後計算PSI。
4.VIF
方差膨脹因子(Variance Inflation Factor,VIF):容忍度的倒數,VIF越大,顯示共線性越嚴重。經驗判斷方法表明:當0<VIF<10,不存在多重共線性;當10≤VIF<100,存在較強的多重共線性;當VIF≥100,存在嚴重多重共線性。
計算方法: 對自變數作中心標準化,則X'X 為自變數的相關陣,定義
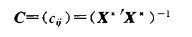
則矩陣C的主對角線元素 VIF(i) 為自變數X(i) 的方差擴大因子VIF。 若X(i) 與其餘自變數的複決定係數為R(i)^2,VIF 與 複決定係數關係為:
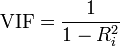
4.1 對每個Model的SEG_A、SEG_B、SEG_C、ALL,計算每個signal的VIF:
(1). Signal的全矩陣為X
(2). 從X取得一列signal y,從X中刪除y得X'
(3). 對X',y作線性迴歸建模,得到模型LR
(4). 使用LR,輸入X,得到y的預測值y_pred
(5). 求得y的VIF= sum((y- y_mean)^2)/sum((y- y_pred)^2)
(6).從第二步開始重複,計算每個signal的VIF
5. ROC曲線
受試者工作特徵曲線 (receiver operating characteristic curve,簡稱ROC曲線): 是反映敏感性和特異性連續變數的綜合指標,是用構圖法揭示敏感性和特異性的相互關係,它通過將連續變數設定出多個不同的臨界值,從而計算出一系列敏感性和特異性,再以敏感性為縱座標、(1-特異性)為橫座標繪製成曲線,曲線下面積越大,診斷準確性越高。在ROC曲線上,最靠近座標圖左上方的點為敏感性和特異性均較高的臨界值。
5.1. 對每個Model(只有SEG_A),計算score與tag的ROC曲線:
(1). 將score 降序排列
(2). score劃分為10等份(每份個數相同)
(3). 計算每一份tag的總和即命中個數,score的最大、最小值
(4). 計算每一份的未命中個數 = 個數- 命中個數
(5). 轉化為累加矩陣,計算累加命中率、累加未命中率
(6). 計算 KS = max ( abs (累加命中率[i] - 累加未命中率[i]) )
(7). 計算 AUROC = sum ( (累加命中率[i] + 累加命中率[i-1])*( 累加未命中率[i] - 累加未命中率[i-1]) )/2 , 即求積分
(8). 計算累加前每層實際命中率、累加前每層預測命中率、每層累加率
(9). ROC 曲線:X軸為累加未命中率[i]),y軸為累加命中率[i]。
6. AUC
Area Under the ROC Curve,ROC 曲線下的面積,AUC 值在0.5 到1 之間。
6.1 對每個Model(只有SEG_A),計算score與tag的AUROC 見5.1:AUROC = sum ( (累加命中率[i] + 累加命中率[i-1])*( 累加未命中率[i] - 累加未命中率[i-1]) )/2 ,求積分7.KS
6.1 對每個Model(只有SEG_A),計算score與tag的AUC見6.1:KS = max ( abs (累加命中率 - 累加未命中率) )8. CI
Condition Index 條件指數:用於診斷多重共線性。
CI > 100 | 強 多重共線性 |
CI > 30 | 中等多重共線性 |
CI > 10 | 弱多重共線性 |
Condition Index 條件指數 計算方法:計算矩陣X‘X 的特徵值,則條件數K和條件指數CI分別為:

8.1. 對每個Model(SEG_A、SEG_B、SEG_C),計算signal的CI:
(1). 求出迴歸矩陣S‘S
(2).求出矩陣S‘S的特徵值lam1、lam2........lamN
(3). 求最大特徵值/最小特徵值 的平方根
9. Logit Plot
9.1. 對每個Model(只有SEG_A),計算signal與tag的logit關係:
(1). 若signal 是標籤型別,則計算其值分別為0、1時候,對應的tag的數量、均值
(2). 若signal 是數值型別,則將signal劃分為最多10個區間,計算各個區間對應的tag的數量、均值
10. CRC
10.1 對每個Model(只有SEG_A),計算score與tag 之間的線性關係:
(1). 按照score降序排列
(2). 劃分為10個等份,求出每一份的score和tag的均值
(3). 使用score均值和tag均值進行線性迴歸建立模型LR
(4). 按照模型LR,使用score均值作為變數,帶入模型LR中,計算出預測的tag均值
11. WOE
WOE 計算公式如下:
其中Bi為每組壞樣本數,BT為總的壞樣本數。Gi為每組好樣本資料,GT為總壞樣本數。
IV的計算公式如下:
其中Bi為每組壞樣本數,BT為總的壞樣本數。Gi為每組好樣本資料,GT為總壞樣本數。