
文字檢測和識別5-LSTM簡介
導語
LSTM[1]作為RNN的經典模型,已經應用在了很多領域,如語音識別[2],OCR[3,4,16],影象描述[5],手寫字識別[6],翻譯[7],自然語言處理等等。
線上手寫字識別[11]

影象內容描述[5]

1為什麼需要LSTM
1.1時序問題
如果接到一個時序問題時,比如語音識別,我首先會想著先切割,然後每一段每一段地去識別,但是由於語音是有上下文關係的,比如中文發一個平聲的"zhong",那麼有可能是中文或者鐘錶的"zhong",因此需要上下文關係。然後我又有些瞭解普通的前饋神經網路,這樣我就會設計出下圖中的網路,把時序的輸入全部輸入到全連線前饋網路中
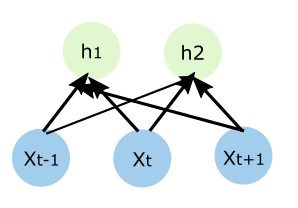
這是一個很自然的選擇。但是個人認為這裡面至少存在三個問題,第一個就是很難確定這個時序的視窗,是用
1.2
這樣理解之後呢就很自然理解普通的遞迴神經網路RNN的出現,如下圖
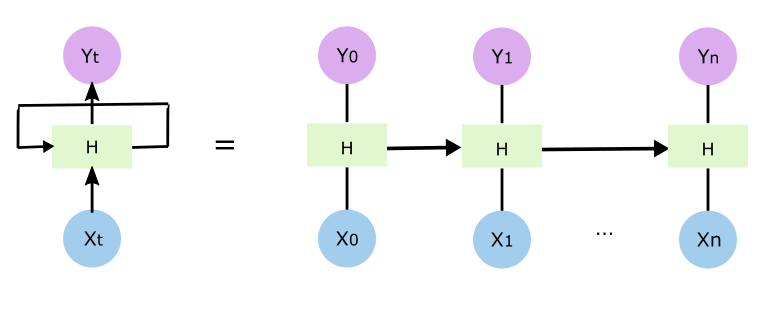
跟最開始的版本相比,輸入到隱藏層的權重、隱藏層到輸出層的權重在每個時間點上保持不變,而隱藏層比以前多了一個輸入,也就是說除了接收輸入層x外,還接收相應的上一個時刻隱藏層的輸出ht-1(跟隱藏層到輸出層yt-1的東西不一樣),靠這個解決上下文的問題
1.3 RNN難以訓練
但是在實際中,RNN比較難訓練,這個小節主要參考[9,10,11].大家都知道為了增加模型的複雜度,神經網路裡面會引入非線性的啟用函式,所以前饋的時候是非線性,但是請注意反饋的時候是線性的,如果你把誤差放大兩倍,那麼所有反饋的誤差也會放大兩倍,同理縮小也一樣。
另外反饋的誤差還跟權重有關係,這裡利用UFLDL裡面的公式[12]
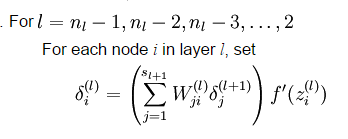
W是權重,delta是誤差,f代表啟用函式,l代表隱藏層,輸入層是最低層,可以看到底層的反饋誤差是上一層的誤差乘以權重,如果權重過小,那麼越往底層傳遞反饋的誤差就越來越小,那麼你用這個誤差去調整網路權值基本也就沒什麼用。梯度爆炸也類似。但是誤差也是權重算出來的,因此控制網路權重非常重要,例如需要很小心的初始化權值,影象中用CNN做轉移學習時,一般都用ImageNet的訓練結果作為初始化,有些也用RBMs的訓練結果初始化。
文獻[10]部分工作是從工程角度去分析啟用函式,從上面的公式上看,啟用函式的導數會影響反饋誤差
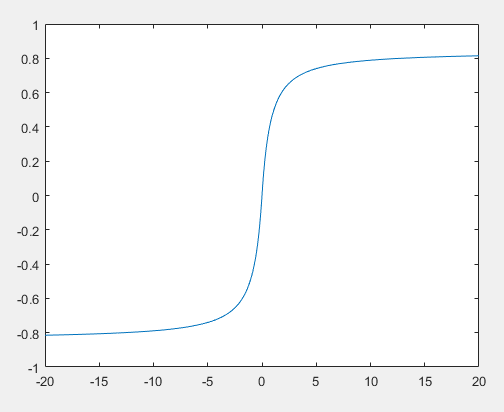
比如sigmoid啟用函式的值處在左邊和右邊的飽和區,但是因為在那些區域的導數是非常小的(曲線比較平),因此也不利於誤差傳播。
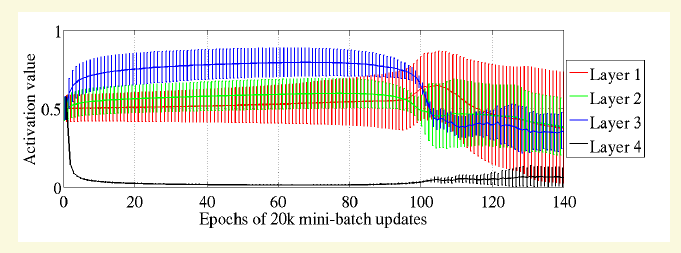
上圖是文獻[10]中前饋網路採用sigmod啟用函式後各個層節點啟用值的均值和標準差示意圖,可以看到第4層前期長期處於飽和區,雖然後面又很神奇地跳了一點出來。頂層反饋誤差很小,那底層的基本就更小了。
由於這些原因,研究者就提出了本文要講的LSTM.
2 LSTM基本概念
LSTM的發明是為了解決梯度消失的問題從而解決時序問題中上下文長依賴的問題。比如預測單詞任務中需要根據前面的單詞去預測下一個輸出的單詞。"我的家在東北,松花江上……..,我能說一口流利的(東北話)",東北和東北話是有依賴關係的,但是中間呢隔了很多其他的單詞,按照普通的RNN,這兩者間有很多的層,因此依賴關係需要經過多次鏈式法則求偏導,所以存在梯度消失的問題,導致最後很難訓練到位。
LSTM有很多變形,這裡我們參考文獻[13]裡介紹一種常用模型,其中主要概念有Input Gate控制輸入,output Gate控制輸出,cell核心記憶模組,forget gate控制cell遺忘程度,peephole等,示例圖如下(主要參考[8,14])
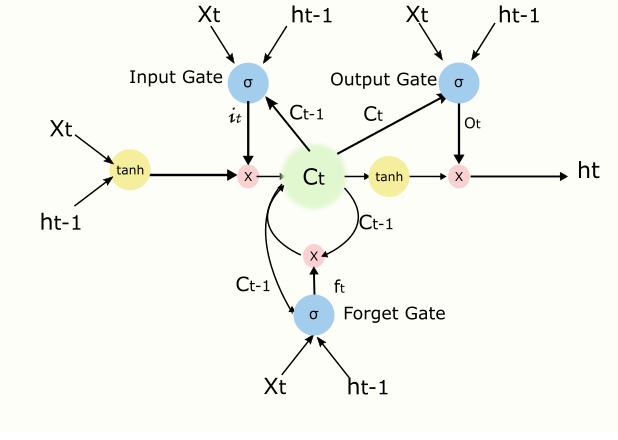
上圖初看比較複雜,不要緊我們一步一步分析,我們看圖中的基本符號
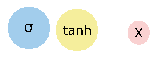
前兩個是啟用函式,分別是sigmoid和tanh,後面一個代表兩個輸入相乘,帶箭頭的連線代表有權重的連線。
2.1 Cell
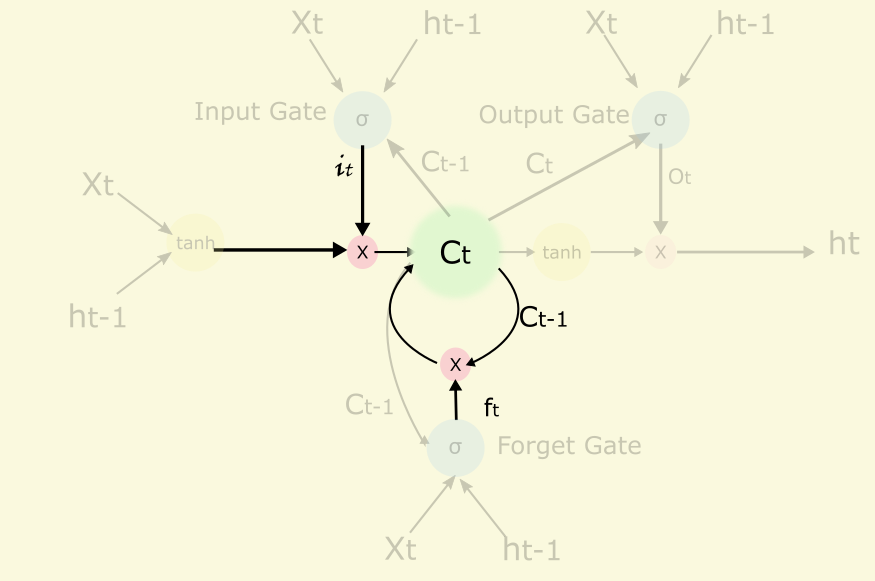
Cell是核心記憶模組,可以看出cell是一個遞迴的節點,它跟它自己的上一個狀態有關,它可以記住或者遺忘自己的上一個狀態,forget gate的輸出ft(0~1.0)來控制這個遺忘程度的,有點像梯度下降法中的衝量。另外它也能接收或者不接收當前的輸入,接收程度由input gate控制。
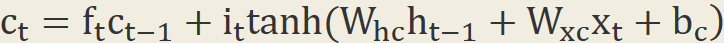
W是權重,b是bias.
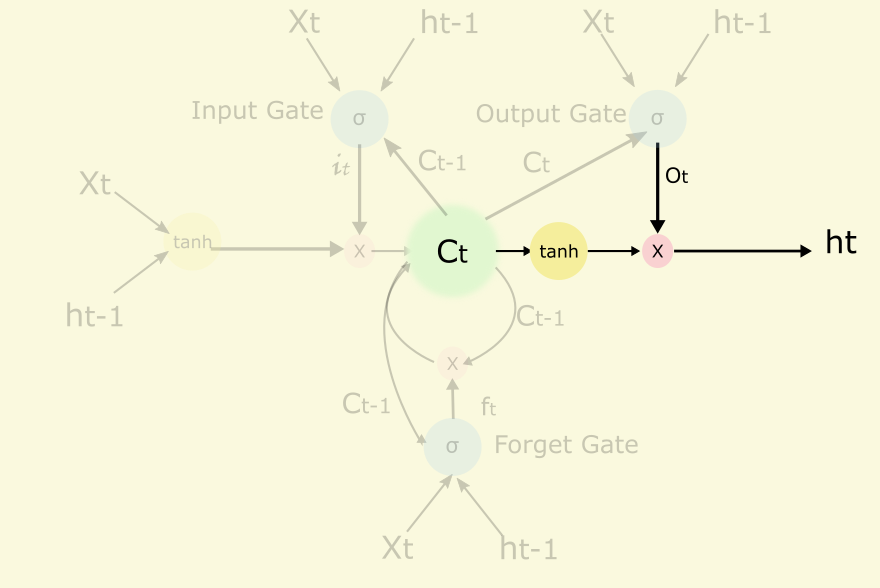
另外cell的結果會輸出到隱藏節點ht,但是輸出的程度由output gate控制
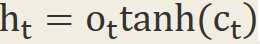
2.2 Forget Gate
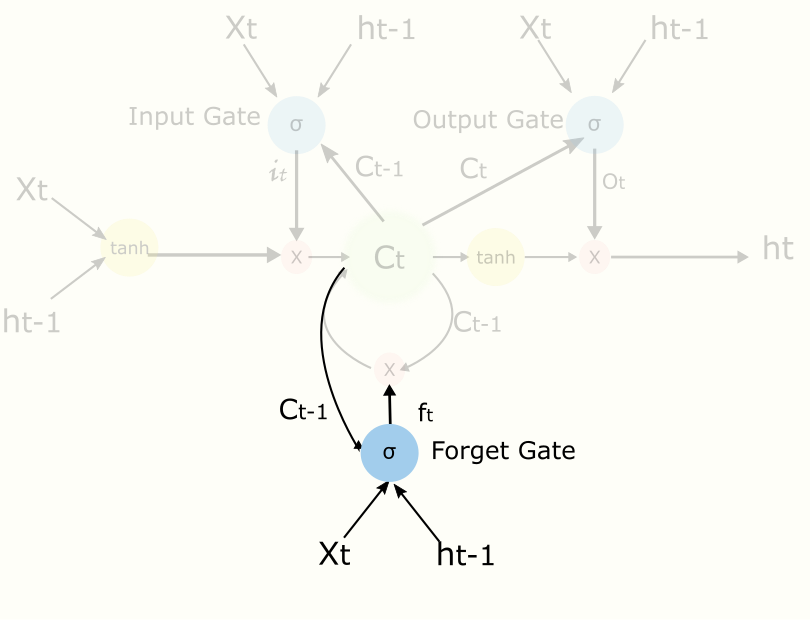
還是以預測下一個單詞為例子。如果當前的輸入是個句號,直覺上那麼句號之後跟句號之前的上下文依賴性較低,這個時候我們可以適當忘記之前的一些東西,比如說忘記8成,好讓後面更好地學習。
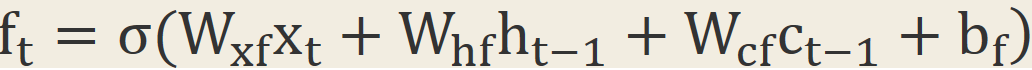
2.3 Input Gate
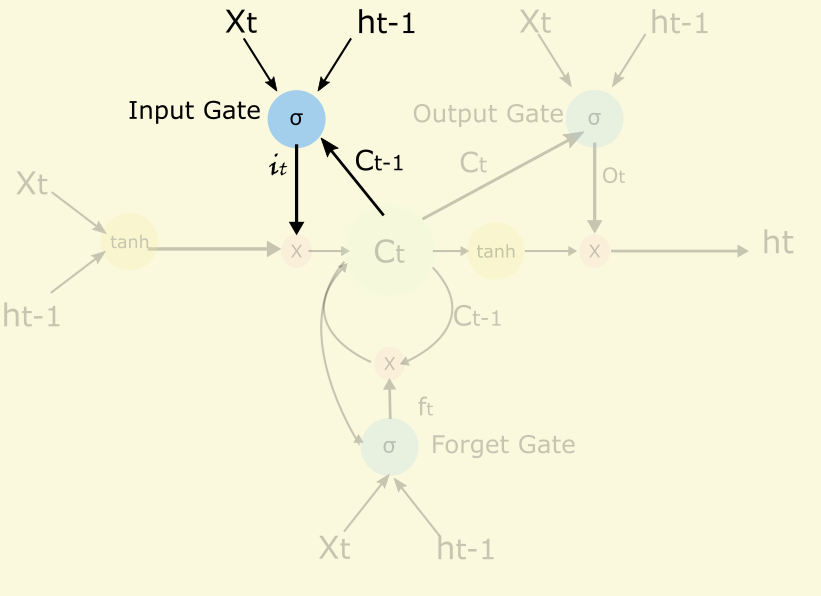
Input Gate是用來控制當前的輸入有多少能到cell.一個極端的例子能說明為什麼LSTM能對時間跨度長的依賴關係建模和input gate的作用。在預測下一個單詞的問題中那麼LSTM可以通過輸入門關閉輸入閥(it值為0),不讓那些單詞影響Cell的值,從而“東北”和“東北話”的關係用一次偏導就可以描述,而沒有什麼中間狀態,不需要偏導的偏導的偏導,從而解決梯度消失的問題。數學公式如下
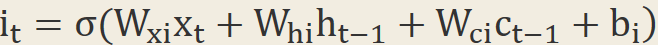
2.4 Output Gate
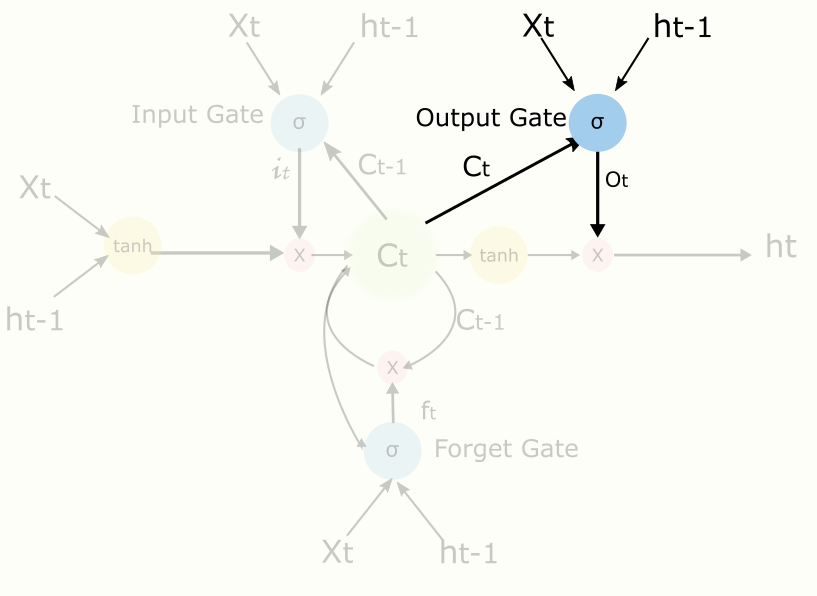
Output Gate是控制當前的cell有多少能輸出到隱藏節點
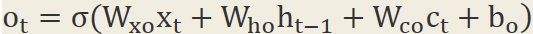
2.5全域性網路
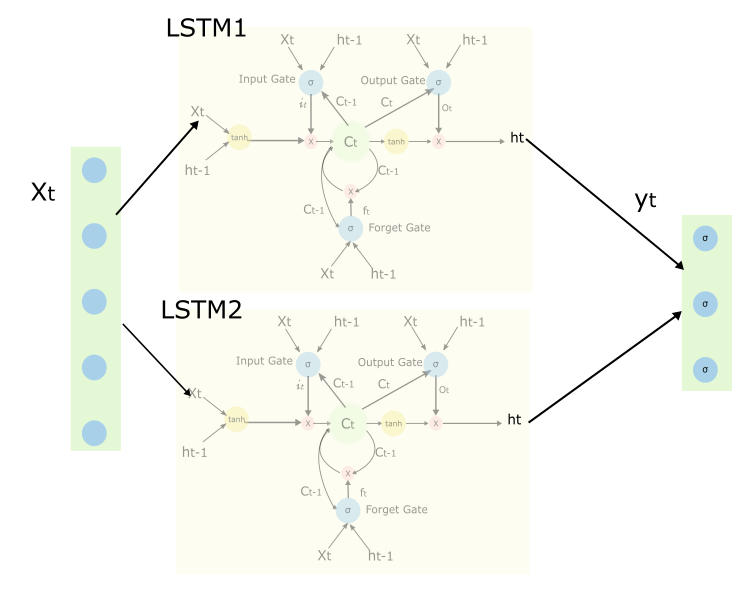
上圖中描述了帶有兩個LSTM塊的網路,請注意有些連線沒有畫出來
2.6 Peephole
Peephole[15]的東西其實已經包含在上面了,但是為了能清楚這個概念,還是再提一下
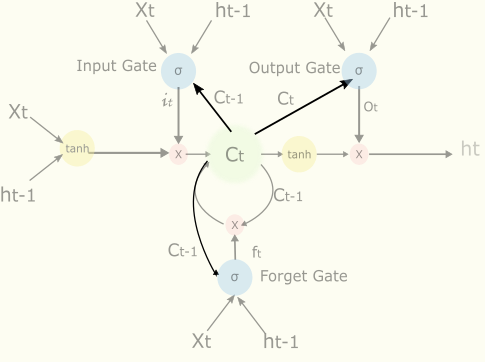
上面三根連結,就是peephole。有了這三個連結cell的狀態就可以去影響input gate,output gate和forget gate的值。
LSTM的訓練就套用BP就可以了,這裡不再繼續討論。
這個小節就講到這裡,後面會繼續討論CTC和MD-LSTM.個人水平有限,錯誤與疏漏請批評指正.
3 LSTM的入門閱讀材料
4統計學習方法第九章EM和第十章HMM
5 [Optional] Learningprecise timing with LSTM recurrent networks。Appendix A. Peephole LSTM with Forget Gates inPseudo-code
6 [Optional]paper of CTC:Connectionist temporal classification: labelling unsegmented sequence data withrecurrent neural networks
7 From Recurrent Neural Networkto Long Short Term Memory Architecture
8 Supervised Sequence Labellingwith Recurrent Neural Networks
4參考文獻
[1]Greff, Klaus, et al."LSTM: A Search Space Odyssey." arXiv preprintarXiv:1503.04069 (2015).
[2]A. Graves and N. Jaitly.Towards end-to-end speech recognition with recurrent neural networks. In ICML,2014. 2,
[3]Messina R, Louradour J.Segmentation-free handwritten Chinese text recognition withLSTM-RNN[C]//Document Analysis and Recognition (ICDAR), 2015 13th InternationalConference on. IEEE, 2015: 171-175.
[4]Ul-Hasan, Adnan, and ThomasM. Breuel. "Can we build language-independent OCR using LSTMnetworks?." Proceedings of the 4th International Workshop onMultilingual OCR. ACM, 2013.
[5]Donahue J, Hendricks L A,Guadarrama S, et al. Long-term recurrent convolutional networks for visualrecognition and description[J]. arXiv preprint arXiv:1411.4389, 2014.
[6]Doetsch, Patrick, MichalKozielski, and Hermann Ney. "Fast and robust training of recurrent neuralnetworks for offline handwriting recognition."Frontiers in HandwritingRecognition (ICFHR), 2014 14th International Conference on. IEEE, 2014.
[7]Luong, Minh-Thang, et al."Addressing the rare word problem in neural machinetranslation." Proceedings of ACL. 2015.
[9]Pascanu, Razvan, TomasMikolov, and Yoshua Bengio. "On the difficulty of training recurrentneural networks." arXiv preprint arXiv:1211.5063 (2012).
[10]Glorot, Xavier, and YoshuaBengio. "Understanding the difficulty of training deep feed forward neuralnetworks." International conference on artificial intelligence andstatistics. 2010.
[12]http://ufldl.stanford.edu/wiki/index.php/Backpropagation_Algorithm
[13]]Graves A. Supervisedsequence labelling with recurrent neural networks[M]. Heidelberg: Springer,2012.
[15]Gers, Felix A., and JürgenSchmidhuber. "Recurrent nets that time and count." Neural Networks,2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International JointConference on. Vol. 3. IEEE, 2000.
[16]He, Pan, et al. "Reading scene text in deep convolutional sequences."arXiv preprint arXiv:1506.04395 (2015).