新手學習使用TensorFlow訓練MNIST資料集
阿新 • • 發佈:2018-11-15
前提是對TensorFlow有了基本的瞭解,還有神經網路相關知識最基礎的瞭解,下面直接用程式碼實現
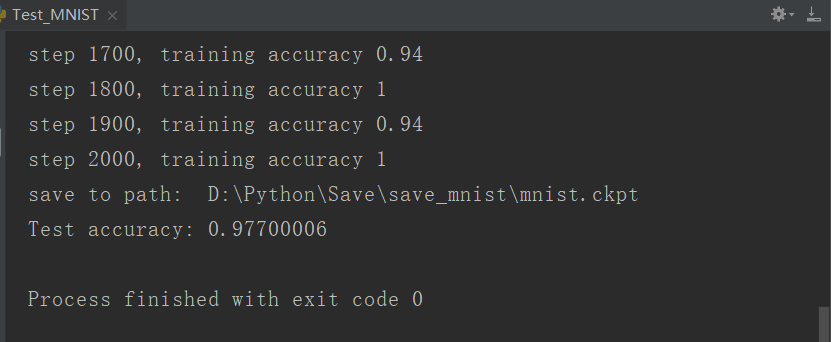
import tensorflow as tf import numpy from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets("D:\Python\MNIST_data", one_hot=True) #新增x作為佔位符 x=tf.placeholder("float", [None, 784])#28*28 #正確結果佔位符 y_=tf.placeholder("float", [None,10]) #生成權重函式 def weight_variable(shape): #tf.truncated_normal(shape, mean, stddev) :shape表示生成張量的維度,mean是均值,stddev是標準差。這個函式產生正態分佈,均值和標準差自己設定 #權重在初始化時應該加入少量的噪聲來打破對稱性以及避免0梯度 initial=tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial,dtype=tf.float32) #生成偏置函式 #由於我們使用的是ReLU神經元,因此比較好的做法是用一個較小的正數來初始化偏置項,以避免神經元節點輸出恆為0的問題(dead neurons) def bias_variable(shape): initial=tf.constant(0.1, shape=shape) return tf.Variable(initial,dtype=tf.float32) #卷積函式 #卷積使用1步長,0邊距的模板,池化用2x2的模板 def conv2d(x, W): #x:待卷積的矩陣具有[batch, in_height, in_width, in_channels]這樣的shape #w:卷積核具有[filter_height, filter_width, in_channels, out_channels]這樣的shape #strides:卷積時在影象每一維的步長,這是一個一維的向量,長度4 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') #池化函式 #和卷積基本相同 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME') #卷積在每個5x5的patch中算出32個特徵。 #卷積的權重張量形狀是[5, 5, 1, 32],前兩個維度是patch的大小, #接著是輸出幾個單位,和輸出的幾個維度 W_conv1=weight_variable([5, 5, 1, 32]) b_conv1=bias_variable([32]) #shape:[batch, in_height, in_width, in_channels] x_image=tf.reshape(x, [-1,28,28,1]) #卷積+偏置,然後給relu啟用函式,最後啟用函式返回值池化 h_conv1=tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #output size 28*28*32 h_pool1=max_pool_2x2(h_conv1) #output size 14*14*32 #第二層卷積,池化 W_conv2=weight_variable([5, 5, 32, 64]) b_conv2=bias_variable([64]) h_conv2=tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #output size 14*14*64 h_pool2=max_pool_2x2(h_conv2) #output size 7*7*64 #全連線層1 W_fc1=weight_variable([7*7*64,1024]) b_fc1=bias_variable([1024]) h_pool2_flat=tf.reshape(h_pool2, [-1,7*7*64]) h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1) #dropout方法減輕過擬合問題 keep_prob=tf.placeholder("float") h_fc1_drop=tf.nn.dropout(h_fc1, keep_prob) #全連線層2 W_fc2=weight_variable([1024, 10]) b_fc2=bias_variable([10]) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #訓練和評估、儲存模型 cross_entropy=-tf.reduce_sum(y_*tf.log(y_conv)) tf.summary.scalar('cross_entropy',cross_entropy) train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_prediction=tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) accuracy=tf.reduce_mean(tf.cast(correct_prediction, "float")) tf.summary.scalar('accuacy',accuracy) sess = tf.InteractiveSession() sess.run(tf.initialize_all_variables()) saver=tf.train.Saver() merged=tf.summary.merge_all() writer=tf.summary.FileWriter('D:\Python\Save\logs',sess.graph) sess.run(tf.global_variables_initializer()) for i in range(2001): batch = mnist.train.next_batch(50) if i% 100 == 0: train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g"%(i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) summary_str = sess.run(merged,feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) writer.add_summary(summary_str,i) save_path = saver.save(sess,'D:\Python\Save\save_mnist\mnist.ckpt') print('save to path: ',save_path) accuracyResult = list(range(10)) for i in range(10): batch = mnist.test.next_batch(1000) accuracyResult[i] = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}) print("Test accuracy:", numpy.mean(accuracyResult))
執行的實驗結果: