
NGINX原理 之 CPU繫結 CPU親和性
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
- 作者:鄒祁峰
- 郵箱:[email protected]
- 部落格:http://blog.csdn.net/qifengzou
- 日期:2014.06.12 18:44
- 轉載請註明來自"祁峰"的CSDN部落格
1 引言
非統一記憶體訪問(NUMA)是一種用於多處理器的電腦記憶體設計,記憶體訪問時間取決於處理器的記憶體位置。 在NUMA下,處理器訪問它自己的本地儲存器的速度比非本地儲存器(儲存器的地方到另一個處理器之間共享的處理器或儲存器)快一些。
針對NUMA架構系統的特點,可以通過將程序/執行緒繫結指定CPU(一個或多個)的方式,提高CPU CACHE的命中率,減少程序/執行緒遷移CPU造成的記憶體訪問的時間消耗,從而提高程式的執行效率。[注:關於CPU親和性的概念,可參考《管理處理器的親和性
2 原始碼剖析
2.1 NGINX原始碼
NGINX程序繫結CPU的程式碼非常簡單,其中的核心介面為sche_setaffinity(),如下所示:
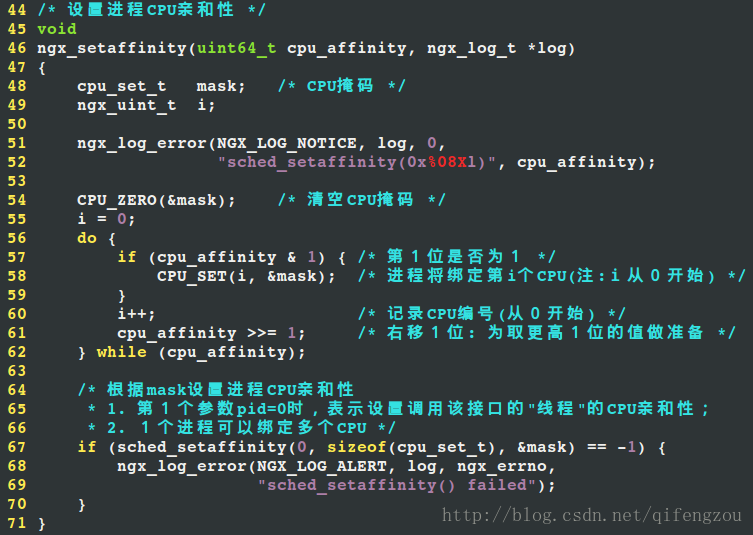
程式碼1 繫結CPU
2.2 原始碼分析
經分析可知:
1) 1程序可繫結到1個或多個CPU核
-> 如果cpu_affinity的值對應的二進位制值為以下值時,那麼程序將繫結到第7和第63個CPU。(從0開始,下同)
10000000 00000000
00000000 00000000
00000000 00000000
00000000 10000000
-> 如果cpu_affinity的值對應的二進位制值為以下值時,那麼程序將繫結到第2、第3和第7個CPU。
00000000 00000000
00000000 00000000
00000000 00000000
00000000 10001100
其他情況可以依此類推。
2) 該函式可設定CPU核範圍:第0~63個.因為引數cpu_affinity的型別為uint64_t,其佔用64位.
2.3 測試例項
根據NGINX原始碼的實現,可以編寫如下測試程式碼:
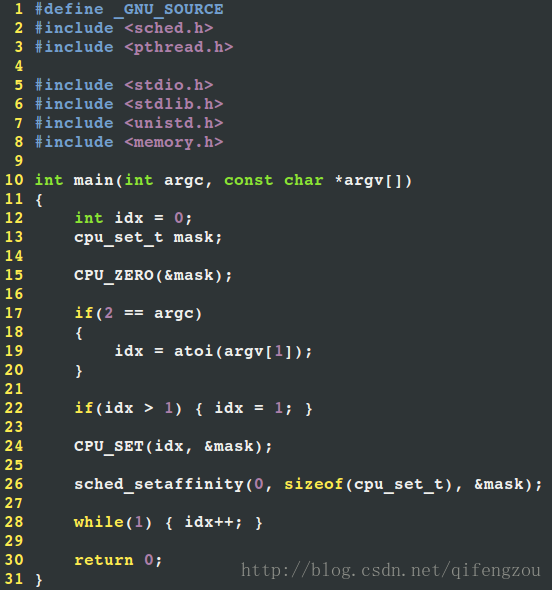
圖1 測試程式碼
1) 測試之前:CPU0和CPU1的消耗都很低

圖2 測試之前
2) 繫結CPU0:CPU0的使用接近100%,而CPU1基本不變

圖3 繫結CPU0
2) 繫結CPU1:CPU1的使用接近100%,而CPU0基本不變
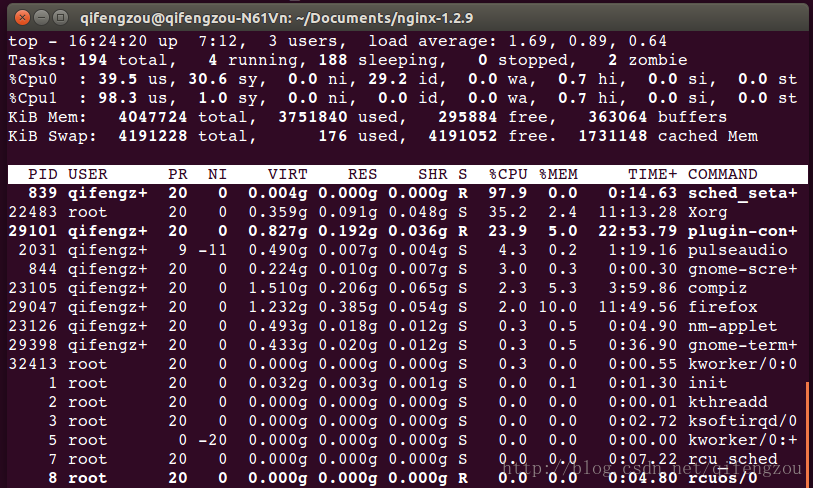
圖4 繫結CPU1
2.4 其他介面
除了sched_setaffinity() 可以設定“程序/執行緒”的CPU親和性外,還可以使用pthread_setaffinity_np()設定“執行緒”的CPU親和性。參考程式碼如下: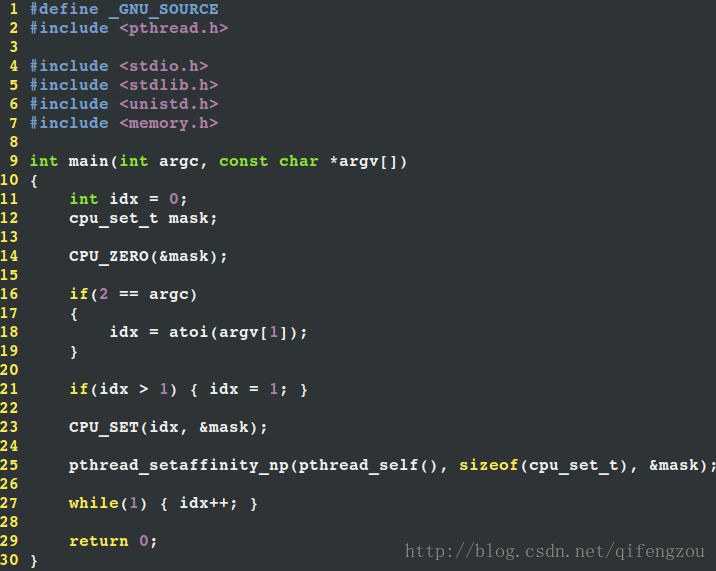
圖5 執行緒繫結CPU
以上程式碼對應的Makefile如下:
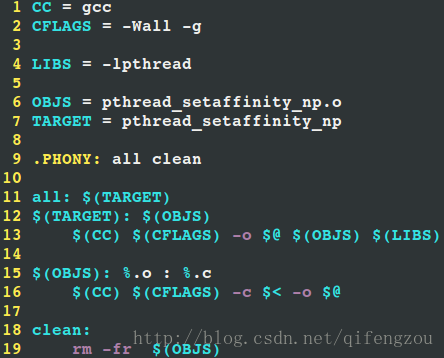
圖6 Makefile
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
