
dpdk之CPU繫結
Linux對執行緒的親和性是有支援的,在Linux核心中,所有執行緒都有一個相關的資料結構,稱為task_count,這個結構中和親和性有關的是cpus_allowed位掩碼,這個位掩碼由n位組成,n程式碼邏輯核心的個數。
Linux核心API提供了一些方法,讓使用者可以修改位掩碼或者檢視當前的位掩碼。
sched_setaffinity(); //修改位掩碼,主要事用來繫結程序 sched_getaffinity(); //檢視當前的位掩碼,檢視程序的親和性 pthread_setaffinity_np();//主要用來繫結執行緒 pthread_getaffinity_np();//檢視執行緒的親和性
使用親和性的原因是將執行緒和CPU繫結可以提高CPU cache的命中率,從而減少記憶體訪問損耗,提高程式的速度。多核體系的CPU,物理核上的執行緒來回切換,會導致L1/L2 cache命中率的下降,如果將執行緒和核心繫結的話,執行緒會一直在指定的核心上跑,不會被作業系統排程到別的核上,執行緒之間互相不干擾完成工作,節省了作業系統來回排程的時間。同時NUMA架構下,如果作業系統排程執行緒的時候,跨越了NUMA節點,將會導致大量的L3 cache的丟失。這樣NUMA使用CPU繫結的時候,每個核心可以更專注的處理一件事情,資源被充分的利用了。
DPDK通過把執行緒繫結到邏輯核的方法來避免跨核任務中的切換開銷,但是對於繫結執行的當前邏輯核,仍可能發生執行緒切換,若進一步減少其他任務對於某個特定任務的影響,在親和性的基礎上更進一步,可以採用把邏輯核從核心排程系統剝離的方法
DPDK的多執行緒
DPDK的執行緒基於pthread介面建立(DPDK執行緒其實就是普通的pthread),屬於搶佔式執行緒模型,受核心排程支配,DPDK通過在多核裝置上建立多個執行緒,每個執行緒繫結到單獨的核上,減少執行緒排程的開銷,以提高效能。
DPDK的執行緒可以屬於控制執行緒,也可以作為資料執行緒。在DPDK的一些示例中,控制執行緒一般當頂到MASTER核(一般用來跑主執行緒)上,接收使用者配置,並傳遞配置引數給資料執行緒等;資料執行緒分佈在不同的SLAVE核上處理資料包。
EAL中的lcore
DPDK的lcore指的是EAL執行緒,本質是基於pthread封裝實現的,lcore建立函式為:
rte_eal_remote_launch();在每個EAL pthread中,有一個TLS(Thread Local Storage)稱為_lcore_id,當使用DPDk的EAL ‘-c’引數指定核心掩碼的時候,EAL pehread生成相應個數lcore並預設是1:1親和到對應的CPU邏輯核,_lcore_id和CPU ID是一致的。
下面簡要介紹DPDK中lcore的初始化及執行任務的註冊
初始化
所有DPDK程式中,main()函式執行的第一個DPDK API一定是int rte_eal_init(int argc, char **argv);,這個函式是整個DPDK的初始化函式,在這個函式中會執行lcore的初始化。
初始化的介面為rte_eal_cpu_init(),這個函式讀取/sys/devices/system/cpu/cpuX下的相關資訊,確定當前系統有哪些CPU核,以及每個核心屬於哪個CPU Socket。
接下來是eal_parse_args()函式,解析-c引數,確認可用的CPU核心,並設定第一個核心為MASTER核。
然後主核為每一個SLAVE核建立執行緒,並呼叫eal_thread_set_affinity()繫結CPU。執行緒的執行體是eal_thread_loop()。eal_thread_loop()主體是一個while死迴圈,呼叫不同模組註冊的回撥函式。
註冊
不同的註冊模組呼叫rte_eal_mp_remote_launch(),將自己的回撥函式註冊到lcore_config[].f中,例子(來源於example/distributor)
rte_eal_remote_launch((lcore_function_t *)lcore_distributor, p, lcore_id);lcore的親和性
DPDK除了-c引數,還有一個–lcore(-l)引數是指定CPU核的親和性的,這個引數講一個lcore ID組繫結到一個CPU ID組,這樣邏輯核和執行緒其實不是完全1:1對應的,這是為了滿足網路流量潮汐現象時刻,可以更加靈活的處理資料包。
lcore可以親和到一個CPU或一組CPU集合,使得在執行時調整具體某個CPU承載lcore成為可能。
多個lcore也可以親和到同個核,這裡要注意的是,同一個核上多個可搶佔式的任務排程涉及非搶佔式的庫時,會有一定的限制,例如非搶佔式無鎖rte_ring:
- 單生產者/單消費者:不受影響,正常使用
- 多生產者/多消費者,且排程策略都是SCHED_OTHER(分時排程策略),可以使用,但是效能稍有影響
- 多生產者/多消費者,且排程策略都是SCHED_FIFO (實時排程策略,先到先服務)或者SCHED_RR(實時排程策略,時間片輪轉 ),會死鎖。
一個lcore初始化和執行任務分發的流程如下:
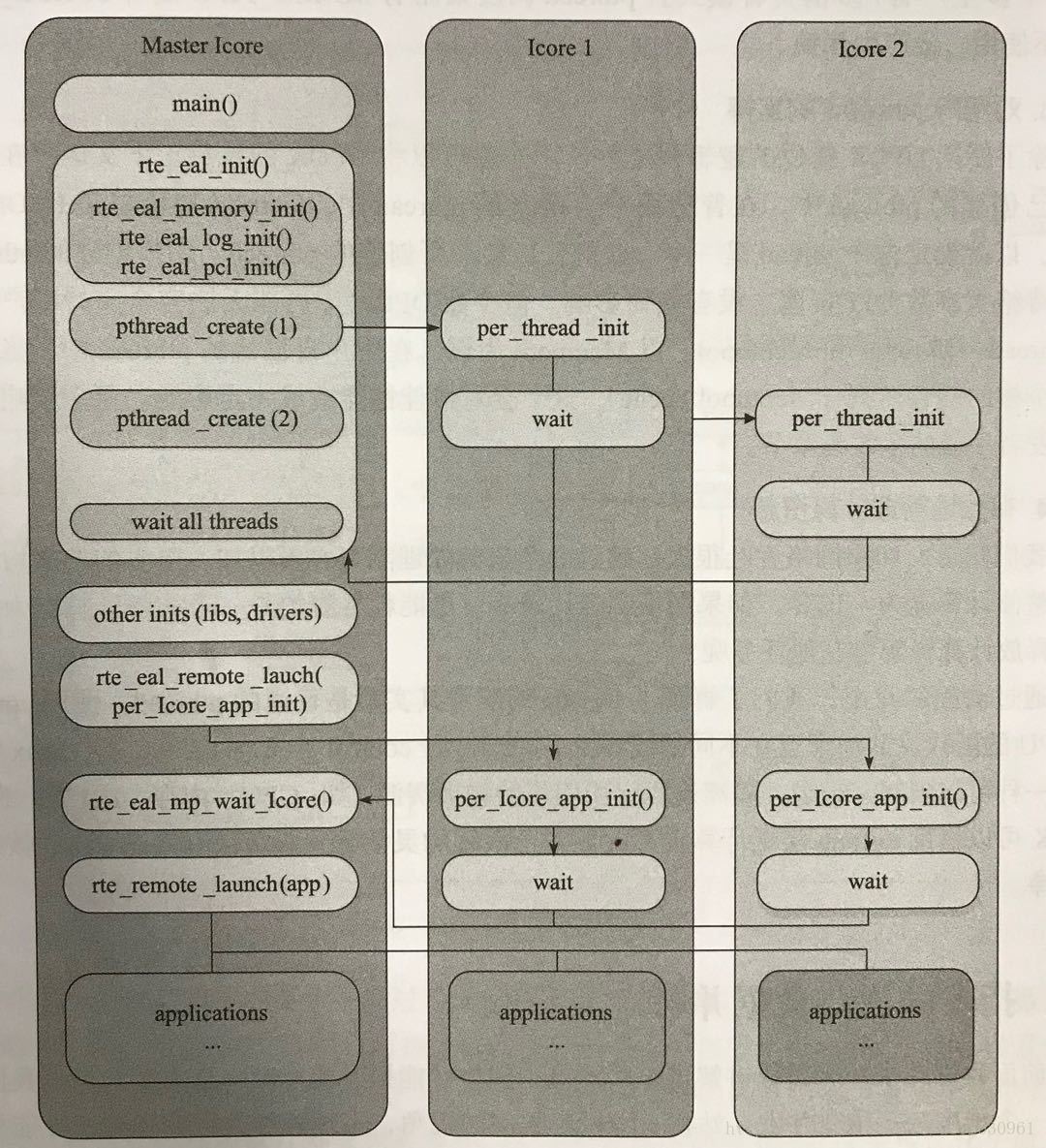
使用者態初始化具體的流程如下:
- 主核啟動main()
- rte_eal_init()進行初始化,主要包括記憶體、日誌、PCI等方面的初始化工作,同時啟動邏輯核線程
- pthread()在邏輯核上進行初始化,並處於等待狀態
- 所有邏輯核都完成初始化後,主核進行後續初始化步驟,如初始化lib庫和驅動
- 主核遠端啟動各個邏輯核上的應用例項初始化操作
- 主核啟動各個核(主核和邏輯核)上的應用
CPU的繫結
先將主執行緒繫結在master核上,然後通過主執行緒建立執行緒池,通過執行緒池進行分配副執行緒到slave核上。在這之前首先要獲取CPU的核數量等資訊,將這些資訊存放到全域性的結構體中。
int
rte_eal_init(int argc, char **argv)
{
。。。。。。
thread_id = pthread_self();
if (rte_eal_log_early_init() < 0)
rte_panic("Cannot init early logs\n");
if (rte_eal_cpu_init() < 0)//賦值全域性結構struct lcore_config,獲取全域性配置結構struct rte_config,初始指向全域性變數early_mem_config,探索CPU並讀取其CPU ID
rte_panic("Cannot detect lcores\n");
。。。。。。。。
eal_thread_init_master(rte_config.master_lcore);//繫結CPU,繫結到master核上
ret = eal_thread_dump_affinity(cpuset, RTE_CPU_AFFINITY_STR_LEN);//檢視CPU繫結情況
。。。。。。。。。。
ret = pthread_create(&lcore_config[i].thread_id, NULL,
eal_thread_loop, NULL);//啟動執行緒池中的副執行緒,為每個lcore建立一個執行緒,繫結到slave核上
if (ret != 0)
rte_panic("Cannot create thread\n");
}以上可以清楚的看見dpdk在初始化的時候繫結cpu的大致過程。
首先看一下 rte_eal_cpu_init()函式:
/*解析/sys/device /system/cpu以獲得機器上的物理和邏輯處理器的數量。該函式將填充cpu_info結構。*/
int
rte_eal_cpu_init(void)
{
/* pointer to global configuration */
struct rte_config *config = rte_eal_get_configuration();//獲取全域性結構體指標
unsigned lcore_id;
unsigned count = 0;
/*
* 設定邏輯核心的最大集合,檢測正在執行的邏輯核心的子集並預設啟用它們
*/
for (lcore_id = 0; lcore_id < RTE_MAX_LCORE; lcore_id++) {
/* init cpuset for per lcore config */
CPU_ZERO(&lcore_config[lcore_id].cpuset);
/* 在1:1對映中,記錄相關的cpu檢測狀態 */
lcore_config[lcore_id].detected = cpu_detected(lcore_id);//檢測CPU狀態
if (lcore_config[lcore_id].detected == 0) {
config->lcore_role[lcore_id] = ROLE_OFF;
continue;
}
//對映到cpu id
CPU_SET(lcore_id, &lcore_config[lcore_id].cpuset);
/* 檢測cpu核啟動 */
config->lcore_role[lcore_id] = ROLE_RTE;
lcore_config[lcore_id].core_id = cpu_core_id(lcore_id);
lcore_config[lcore_id].socket_id = eal_cpu_socket_id(lcore_id);
if (lcore_config[lcore_id].socket_id >= RTE_MAX_NUMA_NODES)
#ifdef RTE_EAL_ALLOW_INV_SOCKET_ID
lcore_config[lcore_id].socket_id = 0;
#else
rte_panic("Socket ID (%u) is greater than "
"RTE_MAX_NUMA_NODES (%d)\n",
lcore_config[lcore_id].socket_id, RTE_MAX_NUMA_NODES);
#endif
RTE_LOG(DEBUG, EAL, "Detected lcore %u as core %u on socket %u\n",
lcore_id,
lcore_config[lcore_id].core_id,
lcore_config[lcore_id].socket_id);
count ++;
}
/* 設定EAL配置的啟用邏輯核心的計數 */
config->lcore_count = count;
RTE_LOG(DEBUG, EAL, "Support maximum %u logical core(s) by configuration.\n",
RTE_MAX_LCORE);
RTE_LOG(DEBUG, EAL, "Detected %u lcore(s)\n", config->lcore_count);
return 0;
}
在這個函式中,並沒有繫結具體執行緒,只是將cpu中的核給預設啟動起來,並且放入到全域性結構體中,我們後面會用到這個結構體來進行繫結執行緒。
eal_thread_init_master()函式:
void eal_thread_init_master(unsigned lcore_id)
{
/* set the lcore ID in per-lcore memory area */
RTE_PER_LCORE(_lcore_id) = lcore_id;
/* set CPU affinity */
if (eal_thread_set_affinity() < 0)
rte_panic("cannot set affinity\n");
}
。。。
int
rte_thread_set_affinity(rte_cpuset_t *cpusetp)
{
int s;
unsigned lcore_id;
pthread_t tid;
tid = pthread_self();
s = pthread_setaffinity_np(tid, sizeof(rte_cpuset_t), cpusetp);
if (s != 0) {
RTE_LOG(ERR, EAL, "pthread_setaffinity_np failed\n");
return -1;
}
/* store socket_id in TLS for quick access */
RTE_PER_LCORE(_socket_id) =
eal_cpuset_socket_id(cpusetp);
/* store cpuset in TLS for quick access */
memmove(&RTE_PER_LCORE(_cpuset), cpusetp,
sizeof(rte_cpuset_t));
lcore_id = rte_lcore_id();
if (lcore_id != (unsigned)LCORE_ID_ANY) {
/* EAL thread will update lcore_config
執行緒更新,這塊程式碼為何自己覆蓋自己,不應該啊*/
lcore_config[lcore_id].socket_id = RTE_PER_LCORE(_socket_id);
memmove(&lcore_config[lcore_id].cpuset, cpusetp,
sizeof(rte_cpuset_t));
}
return 0;
}這個地方我們就清楚的看見將主執行緒繫結到master核上了,可以看見傳的引數就是master核的id,然後繫結master核更新cpu核結構體 資訊。
eal_thread_loop()函式:
從上面程式碼中可以看見是主執行緒建立了一個副執行緒來進行的。接下來我們就看看這個執行緒中eal_thread_loop到底幹了些什麼。
__attribute__((noreturn)) void *
eal_thread_loop(__attribute__((unused)) void *arg)
{
char c;
int n, ret;
unsigned lcore_id;
pthread_t thread_id;
int m2s, s2m;
char cpuset[RTE_CPU_AFFINITY_STR_LEN];
thread_id = pthread_self();
/* retrieve our lcore_id from the configuration structure */
//迴圈查詢當前執行緒的id所在的核
RTE_LCORE_FOREACH_SLAVE(lcore_id) {
if (thread_id == lcore_config[lcore_id].thread_id)
break;
}
if (lcore_id == RTE_MAX_LCORE)
rte_panic("cannot retrieve lcore id\n");
m2s = lcore_config[lcore_id].pipe_master2slave[0];
s2m = lcore_config[lcore_id].pipe_slave2master[1];
/* set the lcore ID in per-lcore memory area */
RTE_PER_LCORE(_lcore_id) = lcore_id;
/* set CPU affinity */
//設定當前執行緒CPU的親和性
if (eal_thread_set_affinity() < 0)
rte_panic("cannot set affinity\n");
ret = eal_thread_dump_affinity(cpuset, RTE_CPU_AFFINITY_STR_LEN);
RTE_LOG(DEBUG, EAL, "lcore %u is ready (tid=%x;cpuset=[%s%s])\n",
lcore_id, (int)thread_id, cpuset, ret == 0 ? "" : "...");
/* read on our pipe to get commands */
//下面說是等待讀取管道上的命令,這個地方其實在等待一個有趣的東西(執行函式)
while (1) {
void *fct_arg;
/* wait command */
do {
n = read(m2s, &c, 1);
} while (n < 0 && errno == EINTR);
if (n <= 0)
rte_panic("cannot read on configuration pipe\n");
lcore_config[lcore_id].state = RUNNING;
/* send ack */
n = 0;
while (n == 0 || (n < 0 && errno == EINTR))
n = write(s2m, &c, 1);
if (n < 0)
rte_panic("cannot write on configuration pipe\n");
if (lcore_config[lcore_id].f == NULL)
rte_panic("NULL function pointer\n");
/* call the function and store the return value */
fct_arg = lcore_config[lcore_id].arg;
ret = lcore_config[lcore_id].f(fct_arg);
lcore_config[lcore_id].ret = ret;
rte_wmb();
lcore_config[lcore_id].state = FINISHED;
}
/* never reached */
/* pthread_exit(NULL); */
/* return NULL; */
}這個函式非常的有趣,再繫結的時候還是呼叫的上面繫結函式,繫結好了之後,讓這個執行緒處於等待狀態,等待什麼呢?其實這個地方再等待分配執行函式過來,也就是說,這個核需要給他分配一個任務他才去執行。
總結
dapk設定cpu親和性大大的提高了效率,減少了執行緒之間的切換。這是一個值得學習的地方。下面就說一下執行緒遷移問題。
遷移執行緒
在普通程序的load_balance過程中,如果負載不均衡,當前CPU會試圖從最繁忙的run_queue中pull幾個程序到自己的run_queue來。
但是如果程序遷移失敗呢?當失敗達到一定次數的時候,核心會試圖讓目標CPU主動push幾個程序過來,這個過程叫做active_load_balance。這裡的“一定次數”也是跟排程域的層次有關的,越低層次,則“一定次數”的值越小,越容易觸發active_load_balance。
這裡需要先解釋一下,為什麼load_balance的過程中遷移程序會失敗呢?最繁忙run_queue中的程序,如果符合以下限制,則不能遷移:
1、程序的CPU親和力限制了它不能在當前CPU上執行;
2、程序正在目標CPU上執行(正在執行的程序顯然是不能直接遷移的);
(此外,如果程序在目標CPU上前一次執行的時間距離當前時間很小,那麼該程序被cache的資料可能還有很多未被淘汰,則稱該程序的cache還是熱的。對於cache熱的程序,也儘量不要遷移它們。但是在滿足觸發active_load_balance的條件之前,還是會先試圖遷移它們。)
對於CPU親和力有限制的程序(限制1),即使active_load_balance被觸發,目標CPU也不能把它push過來。所以,實際上,觸發active_load_balance的目的是要嘗試把當時正在目標CPU上執行的那個程序弄過來(針對限制2)。
在每個CPU上都會執行一個遷移執行緒,active_load_balance要做的事情就是喚醒目標CPU上的遷移執行緒,讓它執行active_load_balance的回撥函式。在這個回撥函式中嘗試把原先因為正在執行而未能遷移的那個程序push過來。為什麼load_balance的時候不能遷移,active_load_balance的回撥函式中就可以了呢?因為這個回撥函式是執行在目標CPU的遷移執行緒上的。一個CPU在同一時刻只能執行一個程序,既然這個遷移執行緒正在執行,那麼期望被遷移的那個程序肯定不是正在被執行的,限制2被打破。
當然,在active_load_balance被觸發,到回撥函式在目標CPU上被執行之間,目標CPU上的TASK_RUNNING狀態的程序可能發生一些變化,所以回撥函式發起遷移的程序未必就只有之前因為限制2而未能被遷移的那一個,可能更多,也可能一個沒有。
部分參考:https://blog.csdn.net/u012630961/article/details/80918682