
PyTorch—計算機視覺目標檢測 mmdetection
一、前言
商湯和港中文聯合開源了 mmdetection—基於 PyTorch 的開源目標檢測工具包。
工具包支援 Mask RCNN 等多種流行的檢測框架,讀者可在 PyTorch 環境下測試不同的預訓練模型及訓練新的檢測分割模型。
專案地址:https://github.com/open-mmlab/mmdetection
mmdetection 目標檢測工具包
mmdetection 的主要特徵可以總結為以下幾個方面:
- 模組化設計:你可以通過連線不同元件輕鬆構建自定義目標檢測框架。
- 支援多個框架,開箱即用:該工具包直接支援多種流行的檢測框架,如 Faster RCNN、Mask RCNN、RetinaNet等。
- 高效:所有基礎邊界框和掩碼運算都在 GPU 上執行。不同模型的訓練速度大約比 FAIR 的 Detectron 快 5% ~ 20%。
- 當前最優:這是 MMDet 團隊的程式碼庫,該團隊贏得了 2018 COCO 檢測挑戰賽的冠軍。
open-mmlab 專案
├─── mmcv 計算機視覺基礎庫
| ├── deep learning framework 工具函式(IO/Image/Video )
| └── PyTorch 訓練工具
└─── mmdetection
其實 mmdetection 很多演算法的實現都依賴於 mmcv 庫。
第一個版本中實現了 RPN、Fast R-CNN、Faster R-CNN、Mask R-CNN,近期還計劃放出 RetinaNet 和 Cascade R-CNN。
先簡單與 Detectron 的對比
- performance 稍高
- 訓練速度稍快
- 所需視訊記憶體稍小
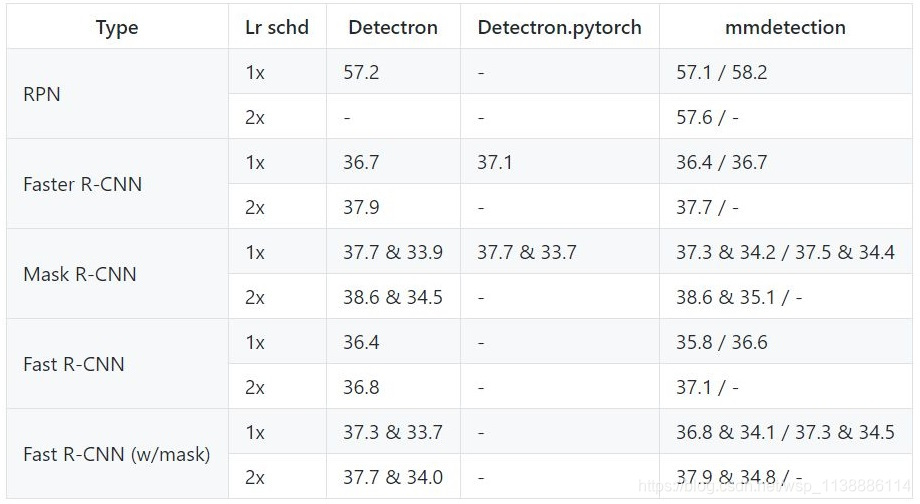
performance:由於 PyTorch 官方 model zoo 裡面的 ResNet 結構和 Detectron 所用的 ResNet 有細微差別(mmdetection 中可以通過 backbone 的 style 引數指定),導致模型收斂速度不一樣,所以我們用兩種結構都跑了實驗,一般來說在 1x 的 lr schedule 下 Detectron 的會高,但 2x 的結果 PyTorch 的結構會比較高。
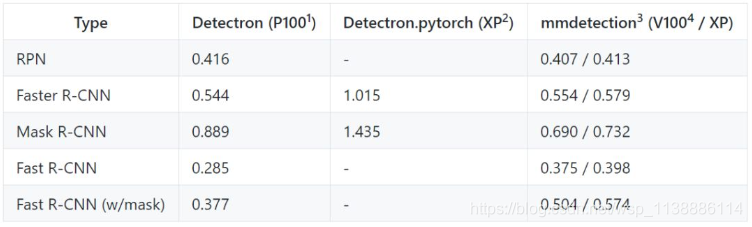
速度方面 :Mask R-CNN 差距比較大,其餘的很小。採用相同的 setting,Detectron 每個 iteration 需要 0.89s,而 mmdetection 只需要 0.69s。Fast R-CNN 比較例外,比 Detectron 的速度稍慢。另外在我們的伺服器上跑 Detectron 會比官方 report 的速度慢 20% 左右,猜測是 FB 的 Big Basin 伺服器效能比我們好?
視訊記憶體方面優勢比較明顯:會小 30% 左右。但這個和框架有關,不完全是 codebase 優化的功勞。一個讓我們比較意外的結果是現在的 codebase 版本跑 ResNet-50 的 Mask R-CNN,每張卡(12 G)可以放 4 張圖,比我們比賽時候小了不少。
- 效能
開發者報告了使用使用 caffe-style 和 pytorch-style ResNet 骨幹網路的結果,前者的權重來自 Detectron 中 MODEL ZOO 的預訓練模型,後者的權重來自官方 model zoo。
- 訓練速度
訓練速度的單位是 s/iter,數值越低代表速度越高
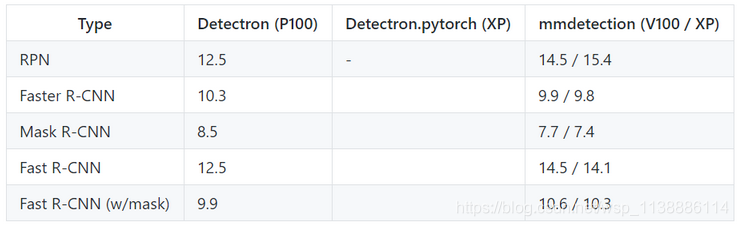
3. 推斷測試
推斷速度的單位是 fps (img/s),數值越高代表效果越好。
二、測試與訓練
mmdetection 需要以下環境
Linux (tested on Ubuntu 16.04 and CentOS 7.2)
Python 3.4+
PyTorch 0.4.1 and torchvision
Cython
mmcv
windows環境下 Anaconda | python==3.6.6 直接安裝
測試和儲存執行示例
測試和儲存結果:python tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --gpus <GPU_NUM> --out <OUT_FILE>
要想執行測試後的評估,你需要新增 --eval <EVAL_TYPES>。支援型別包括:
proposal_fast:使用 mmdetection 的程式碼求 proposal 的召回率。
proposal: 使用 COCO 提供的官方程式碼求 proposal 的召回率。
bbox: 使用 COCO 提供的官方程式碼求 box AP 值。
segm: 使用 COCO 提供的官方程式碼求 mask AP 值。
keypoints:使用 COCO 提供的官方程式碼求 keypoint AP 值。
例如,估計使用 8 個 GPU 的 Mask R-CNN,並將結果儲存為 results.pkl:
python tools/test.py configs/mask_rcnn_r50_fpn_1x.py \
<CHECKPOINT_FILE> --gpus 8 --out results.pkl --eval bbox segm
在測試過程中視覺化結果同樣很方便,只需新增一個引數 --show:
python tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --show
測試影象
import mmcv
from mmcv.runner import load_checkpoint
from mmdet.models import build_detector
from mmdet.apis import inference_detector, show_result
# 匯入模型引數
cfg = mmcv.Config.fromfile('configs/faster_rcnn_r50_fpn_1x.py')
cfg.model.pretrained = None
# 構建化模型和載入檢查點卡
model = build_detector(cfg.model, test_cfg=cfg.test_cfg)
_ = load_checkpoint(model, 'https://s3.ap-northeast-2.amazonaws.com/open-mmlab/mmdetection\
/models/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth')
# 測試單張圖片
img = mmcv.imread('test.jpg')
result = inference_detector(model, img, cfg)
show_result(img, result)
# 測試(多張)圖片列表
imgs = ['test1.jpg', 'test2.jpg']
for i, result in enumerate(inference_detector(model, imgs, cfg, device='cuda:0')):
print(i, imgs[i])
show_result(imgs[i], result)
訓練模型
mmdetection 使用 MMDistributedDataParallel 和 MMDataParallel 分別實現分散式訓練和非分散式訓練。
開發者建議在單個機器上也要使用分散式訓練,因為它速度更快,而非分散式訓練可以用於 debug 或其他目的。
- 分散式訓練
mmdetection 潛在支援多種 launch 方法,如 PyTorch 的內建 launch utility、 slurm 和 MPI。
開發者使用 PyTorch 內建的 launch utility 提供訓練指令碼:
./tools/dist_train.sh <CONFIG_FILE> <GPU_NUM> [optional arguments]
支援的引數有:
--validate:訓練過程中每 k(預設值為 1)個 epoch 執行估計。
--work_dir <WORK_DIR>:如果指定,配置檔案中的路徑將被重寫。 - 非分散式訓練
python tools/train.py <CONFIG_FILE> --gpus <GPU_NUM> --work_dir <WORK_DIR> --validate