
L1正則化
正則化項本質上是一種先驗資訊,整個最優化問題從貝葉斯觀點來看是一種貝葉斯最大後驗估計,其中正則化項對應後驗估計中的先驗資訊,損失函式對應後驗估計中的似然函式,兩者的乘積即對應貝葉斯最大後驗估計的形式,如果你將這個貝葉斯最大後驗估計的形式取對數,即進行極大似然估計,你就會發現問題立馬變成了損失函式+正則化項的最優化問題形式。
在原始的代價函式後面加上一個L1正則化項,即所有權重w的絕對值的和,乘以λ/n:
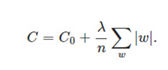
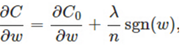
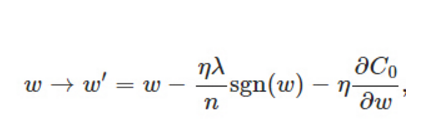
比原始的更新規則多出了η * λ * sgn(w)/n這一項。當w為正時,更新後的w變小。當w為負時,更新後的w變大——因此它的效果就是讓w往0靠,使網路中的權重儘可能為0,也就相當於減小了網路複雜度,防止過擬合。當w為0時怎麼辦?當w等於0時,|W|是不可導的,所以我們只能按照原始的未經正則化的方法去更新w,這就相當於去掉η*λ*sgn(w)/n這一項,所以可以規定sgn(0)=0,這樣就把w=0的情況也統一進來了。(在程式設計的時候,令sgn(0)=0,sgn(w>0)=1,sgn(w<0)=-1)
相關推薦
L1正則化和L2正則化
在機器學習中,我們非常關心模型的預測能力,即模型在新資料上的表現,而不希望過擬合現象的的發生,我們通常使用正則化(regularization)技術來防止過擬合情況。正則化是機器學習中通過顯式的控制模型複雜度來避免模型過擬合、確保泛化能力的一種有效方式。如果將模型原始的假設空間比作“天空”,那麼天空飛翔的“鳥
L1正則化
正則化項本質上是一種先驗資訊,整個最優化問題從貝葉斯觀點來看是一種貝葉斯最大後驗估計,其中正則化項對應後驗估計中的先驗資訊,損失函式對應後驗估計中的似然函式,兩者的乘積即對應貝葉斯最大後驗估計的形式,如果你將這個貝葉斯最大後驗估計的形式取對數,即進行極大似然估計,你就會發現問題立馬變成了損失函式+正則化項
為何說L1正則化會使得權重變得稀疏?
為何說L1正則化會使得權重變得稀疏? 前言 正則化的作用 L1與L2正則化的區別 前言 本文是筆者在學習吳恩達的深度學習課程時,在課程討論區看到的相關討論,加上筆者自己的理解整理而成。 正則化的作用 先說說正則化的概念:正則化是
批歸一化(Batch Normalization)、L1正則化和L2正則化
from: https://www.cnblogs.com/skyfsm/p/8453498.html https://www.cnblogs.com/skyfsm/p/8456968.html BN是由Google於2015年提出,這是一個深度神經網路訓練的技巧,它不僅可以加快了
為什麼L1正則化導致稀疏解
一、從資料先驗的角度 首先你要知道L1正規化和L2正規化是怎麼來的,然後是為什麼要把L1或者L2正則項加到代價函式中去.L1,L2正規化來自於對資料的先驗知識.如果你認為,你現有的資料來自於高斯分佈,那
座標軸下降法(解決L1正則化不可導的問題)
設lasso迴歸的損失函式為: 其中,n為樣本個數,m為特徵個數。 由於lasso迴歸的損失函式是不可導的,所以梯度下降演算法將不再有效,下面利用座標軸下降法進行求解。 座標軸下降法和梯度下降法具有同
泛化能力、訓練集、測試集、K折交叉驗證、假設空間、欠擬合與過擬合、正則化(L1正則化、L2正則化)、超引數
泛化能力(generalization): 機器學習模型。在先前未觀測到的輸入資料上表現良好的能力叫做泛化能力(generalization)。 訓練集(training set)與訓練錯誤(training error): 訓練機器學習模型使用的資料集稱為訓練集(tr
L1正則化與L2正則化的理解
一、概括: L1和L2是正則化項,又叫做罰項,是為了限制模型的引數,防止模型過擬合而加在損失函式後面的一項。 二、區別: 1.L1是模型各個引數的絕對值之和。 L2是模型各個引數的平方和的開方值。 2.L1會趨向於產生少量的特徵,而其他的特徵都是0. 因為最優的引數值很大概率
python機器學習庫sklearn——Lasso迴歸(L1正則化)
Lasso The Lasso 是估計稀疏係數的線性模型。 它在一些情況下是有用的,因為它傾向於使用具有較少引數值的情況,有效地減少給定解決方案所依賴變數的數量。 因此,Lasso 及其變體是壓縮感知領域的基礎。 在一定條件下,它可以恢復一組非零權重的
pytorch中的L2和L1正則化,自定義優化器設定等操作
在pytorch中進行L2正則化,最直接的方式可以直接用優化器自帶的weight_decay選項指定權值衰減率,相當於L2正則化中的λλ,也就是: Lreg=||y−y^||2+λ||W||2(1)(
L1正則化和L2正則化比較
機器學習監督演算法的基本思路是 讓擬合的模型儘量接近真實資料, 換句更通俗的話, 要讓我們的模型儘量簡單又能很好的反應已知資料之間關係。在這個貼近的過程可能存在兩個截然相反的問題:過擬合和擬合不夠。 擬合不夠是模型預測值與真實值之間誤差較大,上篇文章中提到梯度下降就是討論解決問題(求損失函式最小)。 而正則化
對L1正則化和L2正則化的理解
一、 奧卡姆剃刀(Occam's razor)原理: 在所有可能選擇的模型中,我們應選擇能夠很好的解釋資料,並且十分簡單的模型。從貝葉斯的角度來看,正則項對應於模型的先驗概率。可以假設複雜模型有較小的先驗概率,簡單模型有較大的先驗概率。 二、正則化項
l1正則化的稀疏表示和l2正則化的協同表示
這些天一直在看稀疏表示和協同表示的相關論文,特此做一個記錄: 這篇文章將主要討論以下的問題: 1.稀疏表示是什麼? 2.l1正則化對於稀疏表示的幫助是什麼,l0,l1,l2,無窮範數的作用? 3.稀疏表示的robust為什麼好? 4.l2正則化的協同表
正則化項L1和L2的區別
梯度下降法 誤差 font 分享 特征 技術 技術分享 http 現在 https://blog.csdn.net/jinping_shi/article/details/52433975 https://blog.csdn.net/zouxy09/article/deta
機器學習之路: python線性回歸 過擬合 L1與L2正則化
擬合 python sco bsp orm AS score 未知數 spa git:https://github.com/linyi0604/MachineLearning 正則化: 提高模型在未知數據上的泛化能力 避免參數過擬合正則化常用的方法: 在目
L1和L2正則化直觀理解
正則化是用於解決模型過擬合的問題。它可以看做是損失函式的懲罰項,即是對模型的引數進行一定的限制。 應用背景: 當模型過於複雜,樣本數不夠多時,模型會對訓練集造成過擬合,模型的泛化能力很差,在測試集上的精度遠低於訓練集。 這時常用正則化來解決過擬合的問題,常用的正則化有L1正則化和L2
L1,L2正則化
正則化引入的思想其實和奧卡姆剃刀原理很相像,奧卡姆剃刀原理:切勿浪費較多東西,去做,用較少的東西,同樣可以做好的事情。 正則化的目的:避免出現過擬合(over-fitting) 經驗風險最小化 + 正則化項 = 結構風險最小化 經驗風險最小化(ERM),是為了讓擬合的誤差足夠小,即:對訓
正則化方法 L1和L2 regularization 資料集擴增 dropout
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
深度學習基礎--正則化與norm--L1範數與L2範數的聯絡
L1範數與L2範數的聯絡 假設需要求解的目標函式為:E(x) = f(x) + r(x) 其中f(x)為損失函式,用來評價模型訓練損失,必須是任意的可微凸函式,r(x)為規範化約束因子,用來對模型進行限制。 根據模型引數的概率分佈不同,r(x)一般有: 1)L1正規化
深度學習正則化-引數範數懲罰(L1,L2範數)
L0範數懲罰 機器學習中最常用的正則化措施是限制模型的能力,其中最著名的方法就是L1和L2範數懲罰。 假如我們需要擬合一批二次函式分佈的資料,但我們並不知道資料的分佈規律,我們可能會先使用一次函式去擬合,再