
mysql與mariaDB學習之innoDB儲存引擎
文章目錄
基礎知識
- 資料庫:物理作業系統檔案或其他形式檔案型別的集合。有些儲存引擎是存放於記憶體之中的檔案。
- 資料庫例項:由資料庫後臺執行緒以及一個共享記憶體區組成。資料庫例項才是真正用於操作資料庫檔案的。在MySQL資料庫中,一個例項對應一個數據庫,一個數據庫對應一個例項。我們的應用程式是不能直接操作資料庫的,只能通過操作資料庫例項來間接與資料庫互動。
- 資料庫啟動時,需要去載入配置檔案
my.cnf,查詢該配置檔案的命令是mysql --help|grep 'my.cnf',如果是Windows平臺則是.cnf檔案或.ini檔案。 - 資料庫路徑:通常在配置檔案的
datadir引數,linux作業系統下預設的datadir是/usr/local/mysql/data
innoDB儲存引擎
innoDB儲存引擎的體系架構圖如下:
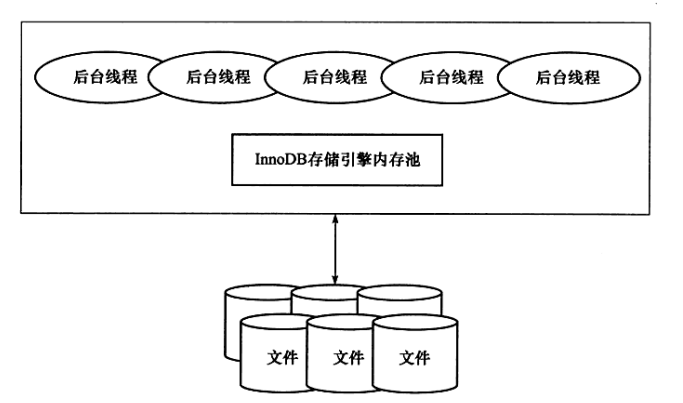
1、後臺執行緒
- 後臺執行緒分為
Master Thread和IO Thread,其中Master是一個核心的後臺執行緒,負責將緩衝池中的資料非同步重新整理到磁碟,保證資料的一致性,包括髒頁的重新整理、合併插入緩衝(INSERT BUFFER)、UNDO頁的回收。IO Thread主要是用來處理AIO處理請求後的回撥。InnoDB共有4個IO Thread,分別是write、read、insert buffer、log IO thread。 - write和read的執行緒個數可以通過配置檔案中的以下兩個引數來調整。
innodb-read-io-threads = 8
innodb-write-io-threads = 8 - log IO thread執行緒通過
show engine innoDB status命令來檢視,如果查詢結果是一條記錄,就說明該執行緒只有一條。
- Purge Thread:事務被提交後,其所使用的undolog可能不再需要,需要PurgeThread來回收已經使用並分配的undo頁。可以通過修改配置檔案中的這個配置來修改執行緒個數。
innodb_purge_threads = 1 - Page Cleaner Thread:在InnoDB 1.2.x版本引入。其作用是將之前版本中髒頁的重新整理操作都放入到單獨的執行緒中來完成。其目的是為了減輕原來Master Thread的工作對於使用者查詢執行緒的阻塞,提高InnoDB的效能。

2、記憶體
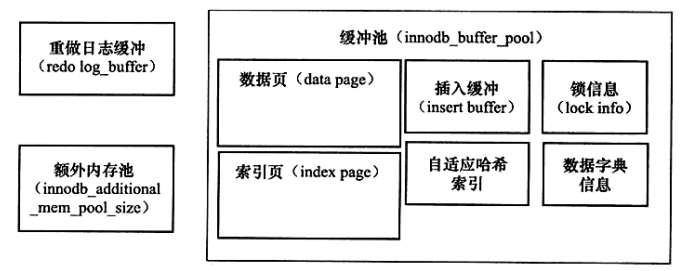
2.1 緩衝池簡介
緩衝池:緩衝池就是一塊記憶體區域,通過記憶體的速度來彌補磁碟速度較慢對資料庫效能的影響。在資料庫中進行讀取頁的操作,首先將從磁碟讀到的頁存放在緩衝池中,這個過程被稱為頁FIX在緩衝池中。下一次再讀相同的頁時,首先判斷該頁是否在緩衝池中,如果在緩衝池中,稱該頁在緩衝池中被命中,直接讀取該頁。否則,讀取磁碟上的頁。
- 對於資料庫中頁的修改操作,首先是修改在緩衝池中的頁,然後再以一定的頻率重新整理到磁碟上。不過頁從緩衝池重新整理回磁碟的操作並不是在每次頁發生更改時出發。而是通過一種稱為Checkpoint的機制重新整理回磁碟。
- 可以通過修改配置檔案中引數來修改緩衝池的大小
innodb-buffer-pool-size = 2G。 - 緩衝池中記憶體頁的結構如下:緩衝池中的頁大小預設未為16K。
- InnoDB1.0.x版本開始,允許有多個緩衝池例項。每個頁根據雜湊值平均分配到不同緩衝池例項中。這樣做的好處是增加資料庫併發的處理能力。緩衝池的個數可以通過配置檔案中的
innodb-buffer-pool-instances = 8來修改。 - 可以通過下面的查詢方式來檢視當前記憶體池的使用狀態。

2.2 LRU演算法
LRU(Latest Recent Used,最近最少使用),最頻繁使用的頁再LRU列表的前端,最少使用的頁在LRU列表的尾端。當緩衝池不能繼續存放新讀取到的頁時,將首先釋放LRU列表中尾端的頁。InnoDB對LRU演算法做了很多優化:
- midpoint位置:新讀取到的頁,雖然是最新訪問的頁,但並不是直接放入到LRU列表的midpoint位置。預設的配置時在LRU長度的5/8的位置。可以通過修改配置檔案的這個引數
innodb_old_blocks_pct=37來調整該位置,引數中的37表示的37%,約等於5/8。mid前面的頁被稱為old頁,mid後面的頁被稱為new頁。 - 等待時間:頁讀取到mid位置後需要等待多久才會被加入帶LRU列表的熱端。通過修改這個引數
innodb_old_blocks_time=1000來調整。
引數
innodb_old_blocks_pct的作用:如果直接採用樸素的LRU演算法,將直接讀取到的頁直接放入到LRU的首部,那麼某些SQL操作可能會使緩衝池中的頁被刷新出,從而影響緩衝池的效率。常見的這類操作作為索引或資料的掃描操作。這類操作需要訪問表中的許多頁,甚至全部的頁。而這些頁通常不是活躍的熱點資料。如果將這些資料放入首部,那麼非常有可能將所需要的熱點資料頁從LRU列表中移除,再下一次需要讀取該頁時,InnoDB儲存引擎需要再次訪問磁碟。
引數
innodb_old_blocks_time的作用,如果上面的操作始終將新頁放在mid,那麼在mid前面的頁將始終不會被重新整理,這個引數就是用來解決這個問題的。
2.3 檢視innodb狀態
- Free列表:LRU是用來管理已讀讀取的頁。當資料庫剛啟動時,LRU列表時空的,沒有任何的頁。這是頁都存放在Free列表中。當需要從緩衝池中分頁時,首先從Free列表中查詢是否有可用的空閒頁,若有,則將該頁從Free列表中刪除,放入到LRU列表中。
- page made young:LRU列表的old部分加入到new部分時,這時的操作被叫做page made young。
- page not made young:因為
innodb_old_blocks_time的設定而導致頁沒有從old部分移動到new部分的操作被叫做 page not made young。
1、通過show engine innodb status可以檢視LRU和Free列表的狀態,該命令展示的並不是當前狀態,展示的是過去24s的狀態。Per second averages …… 24 seconds,如下圖。


Buffer pool size表示共有8197個頁,總共有(8197*16k)個G的緩衝池。Free Buffer表示當前Free列表中頁的數量。Database pages表示LRU列表中頁的數量。Free Buffer和Database pages數量之和不等於Buffer pool size,是因為緩衝池中的頁還可能會被分配給自適應雜湊索引、Lock資訊、Insert Buffer等頁。這部分不需要LRU演算法來維護,所以不存在與LRU列表中。page made young顯示了LRU列表中頁移動到前端的次數。Buffer pool hit rate表示緩衝池的命中率,如果該值小於95%,就要考慮是否由於全表稻苗引起的LRU列表汙染的問題。
2、InnoDB 1.2版本開始,還可以通過表INNODB_BUFFER_POOL_STATS來觀察緩衝池,查詢sql如下:
select pool_id,hit_rate,
pages_made_young,
pages_not_made_young
from information_schema.INNODB_BUFFER_POOL_STATS
查詢結果如下:

通過INNODB_BUFFER_PAGE_LRU這個表還可以查詢每個頁的詳細資訊,查詢語句如下:
select TABLE_NAME,SPACE,
PAGE_NUMBER,PAGE_TYPE
from INNODB_BUFFER_PAGE_LRU where space=1;
查詢結果如下:

3、壓縮頁
InnoDB儲存引擎從1.0.x版本開始支援壓縮頁的功能,將原本16K的頁壓縮為1K、2K、4K和8K。由於頁的大小發生了變化,LRU列表也有了些許的改變。對於非16K的頁,是通過unzip_LRU列表進行管理的。通過命令show engine innoDB status可以看到如下內容:
unzip_LRU是怎樣從緩衝池中分配記憶體的呢?例如:對需要從緩衝池中申請4KB的大小,過程如下:

- 檢查4K的unzip_LRU列表,檢查是否有可用的空閒頁。
- 若有,則直接使用。
- 否則,檢查8KB的unzip_LRU列表。
- 若能夠得到空閒頁,將頁分成2個4KB頁,存放到4KB的unzip_LRU。
- 若不能得到空閒頁,從LRU列表申請一個16KB的頁,將頁分為1個8KB的頁,2個4KB的頁,分別存放到對應的unzip_LRU列表中。
查詢unzip_LRU列表中的頁。
select TABLE_NAME,SPACE,PAGE_NUMBER,COMPRESSED_SIZE
from INNODB_BUFFER_PAGE_LRU WHERE COMPRESSED_SIZE <> 0;
查詢結果如下:下面的查詢沒有加where條件,是因為測試用的資料庫沒有被壓縮的頁。

4、髒頁(dirty page)
髒頁就是緩衝池裡面的資料頁和磁碟上的資料頁產生了不一致,此時需要使用Checkpoint技術重新將緩衝池中的頁的變化寫入磁碟上。FLUSH列表中存放的都是髒頁,不過要注意的是,髒頁在LRU列表和Flush列表中是共存的。LRU列表用來管理頁的可用性,FLUSH列表用來將資料刷回磁碟。
查詢髒頁的sql如下:需要在查詢INNODB_BUFFER_PAGE_LRU表時加個where條件OLDEST_MODIFICATION > 0。
select TABLE_NAME,SPACE,PAGE_NUMBER,COMPRESSED_SIZE
from INNODB_BUFFER_PAGE_LRU WHERE OLDEST_MODIFICATION > 0;
注意:所有查詢
INNODB_BUFFER_PAGE_LRU的結果如果TABLE_NAME的值是NULL,說明是系統的頁。
2.4 重做日誌緩衝
InnoDB儲存引擎的記憶體區域除了有緩衝池外,還有重做日誌緩衝(redo log buffer)。InnoDB儲存引擎先將重做日誌資訊先放入這個緩衝區,然後按照一定頻率將其重新整理重做日誌檔案。重做日誌緩衝一般不需要設定的很大,因為一般情況下每一秒鐘就會將重做日誌緩衝重新整理到日誌檔案,因此在設定日誌快取大小時,只需要考慮每秒的快取任務量即可。
在my.cnf配置檔案中通過修改引數innodb-log-buffer-size = 64M來配置日誌快取的大小。
當出現下面三種情況下會將重做日誌緩衝中的內容重新整理到外部磁碟的重做日誌檔案中。
- Master Thread每一秒將重做日誌緩衝重新整理到重做日誌檔案。
- 每個事務提交時會將重做日誌緩衝重新整理到重做日誌檔案。
- 當重做日誌緩衝池剩餘空間小於1/2時,重做日誌緩衝重新整理到重做日誌檔案。
2.5 額外的記憶體池
在InnoDB儲存引擎中,對記憶體的管理是通過一種稱為記憶體堆(heap)的方式進行的。在對一些資料結構本身的記憶體進行分配時,需要從額外的記憶體池中進行申請,當該區域的記憶體不夠時,會從緩衝池中進行申請。例如:分配了緩衝池(innodb_buffer_pool),但是每個緩衝池中的幀緩衝(frame buffer)還有對應的緩衝控制物件(buffer control block),這些物件記錄了一些LRU、鎖、等資訊,而這個物件的記憶體需要從額外記憶體池中申請。所以,如果在配置檔案中申請了很大的InnoDB緩衝池時,也考慮相應的增加這個值。
2.6 Checkpoint技術
如果一條DML語句,如Update或Delete改變了頁中的記錄,那麼此時頁是髒的,即緩衝池中的頁要比磁碟的新,資料庫需要將新版本的頁從緩衝池舒心到磁碟。倘若每一個頁發生變化,就將新頁的版本重新整理到磁碟,那麼這個開銷是非常大的。同時,如果在從緩衝池將新版本重新整理到磁碟時發生了宕機,那麼資料就不能恢復了,為了避免發生資料丟失的問題,當前事務資料庫系統普遍都採用了Write Ahead Log策略,即當事務提交時,先寫重做日誌,再修改頁。這樣當發生宕機導致資料丟失時,通過重做日誌來恢復。
Checkpoint技術就是為了解決上述過程中緩衝池不夠用和日誌不可用的問題:
- 緩衝池不夠用時,將髒頁重新整理到磁碟。
- 重做日誌不可用時,重新整理髒頁。
這樣當資料庫發生宕機時,資料庫不需要重做所有的日誌,因為Checkpoint之前的也都已經重新整理回磁碟。所以資料庫只需對Checkpoint後的重做日誌進行恢復。這樣就縮短了恢復時間。除此以外,當緩衝池不夠用時,根據LRU演算法會溢位最少使用的頁,若此頁為髒頁,那麼需要強制執行Checkpoint,將髒頁也就是頁的新版本刷回磁碟。
重做日誌不可用的情況:當前事務資料庫系統對重做日誌的設計都是迴圈使用的,並不是讓其無限增大的,這從成本及管理上都是比較困難的。如果重做日誌的某一部分已經被寫到磁碟上,也就是恢復資料時並不需要這部分,那這部分就日誌可以覆蓋掉。若此時重做日誌還需要使用,不能被覆蓋,那麼必須強制產生Checkpoint,將緩衝池中的頁至少重新整理到當前重做日誌的位置。
同樣可以通過show engine INNODB STATUS來檢視checkpoint的相關狀態。如下:
對於innoDB儲存引擎而言,是通過LSN(Log Sequence Number)來標記版本的。而LSN是8位元組的數字,單位是位元組,每個頁都有LSN,重做日誌中也有LSN,Checkpoint也有LSN。
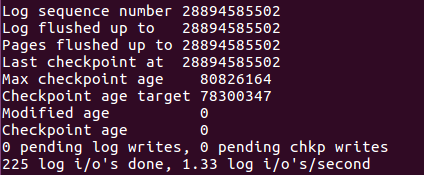
Checkpoint所做的事情其實就是將緩衝池中的髒頁刷回到磁碟。不同之處在於每次重新整理多少頁到磁碟,每次從哪裡去髒頁,以及什麼時間出發Checkpoint。在InnoDB儲存引擎內部,有兩種Checkpoint,分別是:Sharp Checkpoint和Fuzzy Checkpoint
- Sharp Checkpoint發生在資料庫關閉時,將所有的髒頁都重新整理回磁碟,這是預設的工作方式。
- Fuzzy Checkpoint在資料庫執行時使用,只重新整理一部分髒頁,而不是重新整理所有的髒頁回磁碟。
2.7 Master Thread工作方式
3、InnoDB關鍵特性
- 插入緩衝(Insert Buffer)
- 兩次寫(Double Write)
- 自適應雜湊索引(Adaptive Hash Index)
- 非同步IO(Async IO)
- 重新整理鄰接頁(Flush Neighbor Page)
4、啟動、關閉與恢復
MySQL例項的啟動過程中對InnoDB儲存引擎可以做相應的處理。
1.引數innodb_fast_shutdown影響著表的儲存引擎為InnoDB的行為。該引數可取的值為0、1 、2,預設值為1.
- 0表示在Mysql資料庫關閉時,InnoDB需要完成所有的full purge和merge insert buffer,並且將左右的髒頁重新整理回磁碟。這需要一些時間,有時甚至需要幾個小時來完成。如果進行InnoDB升級時,必須將這個引數調為0,然後關閉資料庫。
- 1表示不完成full purge和merge insert buffer操作,但是在換充值中的一些資料髒頁還是會重新整理回磁碟。
- 2表示不完成full purge和merge insert buffer操作,也不將緩衝池中的資料髒頁寫回磁碟,而是將日誌都寫入檔案,這樣不會有任何事物的丟失,但是下次MySQL資料庫啟動時,會進行恢復操作。
- 引數
innosb_force_recovery影響了整個InnoDB儲存引擎恢復的狀況。該引數的預設值是0,表示當發生需要恢復時,進行所有的恢復操作,當不能進行有效恢復時,如資料頁發生了corruption,MySQL資料庫可能發生宕機(crash),並把錯誤寫入錯誤日誌中去。該引數可設定的值如下:- 1(SRV_FORCE_IGNORE_CORRUPT):忽略檢查到的corrupt頁。
- 2(SRV_FORCE_NO_BACKGROUND):阻止主執行緒的執行,如主執行緒需要執行full purge操作,會導致crash。
- 3(SRV_FORCE_NO_TRX_UNDO):不執行事務回滾操作。
- 4(SRV_FORCE_NO_IBUF_MERGE):不執行插入緩衝的合併操作。
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN):不檢視重做日誌,InnoDB儲存引擎會將未提交的事務視為已提交。
- 6(SRV_FORCE_NO_LOG_REDO):不執行前滾的操作。