
三維點雲配準
作者:劉緣
連結:https://www.zhihu.com/question/34170804/answer/121533317
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
本科畢業設計做的點雲配準,對這個方面有一些初步理解,希望有所幫助~
1、首先,點雲配準過程,就是求一個兩個點雲之間的旋轉平移矩陣(rigid transform or euclidean transform 剛性變換或歐式變換),將源點雲(source cloud)變換到目標點雲(target cloud)相同的座標系下。
可以表示為以下的方程:
其中就是target cloud與source cloud中的一對對應點。
而我們要求的就是其中的R
這裡,我們並不知道兩個點集中點的對應關係。這也就是配準的核心問題。
2、配準分為粗配準與精配準兩步。
粗配準就是再兩個點雲還差得十萬八千里、完全不清楚兩個點雲的相對位置關係的情況下,找到一個這兩個點雲近似的旋轉平移矩陣(不一定很精確,但是已經大概是對的了)。
精配準就是在已知一個旋轉平移的初值的情況下(這個初值大概已經是正確的了),進一步計算得到更加精確的旋轉平移矩陣。
這裡從精配準開始講起。
精配準的模式基本上已經固定為使用ICP演算法及其各種變種。ICP演算法由Besl and McKay 1992, Method for registration of 3-D shapes文章提出。文中提到的演算法不僅僅考慮了點集與點集之間的配準,還有點集到模型、模型到模型的配準等。
簡要介紹一下點集到點集ICP配準的演算法:
1)ICP演算法核心是最小化一個目標函式:
(這裡的表述與原文略微有些不同,原文是用四元數加上一個偏移向量來表達旋轉平移變換。)
2)尋找對應點。可是,我們現在並不知道有哪些對應點。因此,我們在有初值的情況下,假設用初始的旋轉平移矩陣對source cloud進行變換,得到的一個變換後的點雲。然後將這個變換後的點雲與target cloud進行比較,只要兩個點雲中存在距離小於一定閾值(這就是題主所說的ICP中的一個引數),我們就認為這兩個點就是對應點。這也是"最鄰近點"這個說法的來源。
3)R、T優化。有了對應點之後,我們就可以用對應點對旋轉R與平移T進行估計。這裡R和T中只有6個自由度,而我們的對應點數量是龐大的(存在多餘觀測值)。因此,我們可以採用最小二乘等方法求解最優的旋轉平移矩陣。一個數值優化問題,這裡就不詳細講了。
4)迭代。
演算法大致流程就是上面這樣。這裡的優化過程是一個貪心的策略。首先固定R跟T利用最鄰近演算法找到最優的點對,然後固定最優的點對來優化R和T,依次反覆迭代進行。這兩個步驟都使得目標函式值下降,所以ICP演算法總是收斂的,這也就是原文中收斂性的證明過程。這種優化思想與K均值聚類的優化思想非常相似,固定類中心優化每個點的類別,固定每個點的類別優化類中心。
關於引數的選擇:
ICP演算法的引數主要有兩個。一個是ICP的鄰近距離,另外一個是迭代的終止條件。這些引數的選擇,與實際的工程應用相關。比如說你的儀器精度是5mm,那麼小於5mm是可以認為是對應點,而最終的迭代終止條件也就是匹配點之間平均距離小於5mm。而且這些引數可以由演算法逐步迭代減小,最初使用較大的對應點距離引數,然後逐步減小到一個較小的值。(問過師兄才知道實際過程這樣操作會比較合適。)需要手動調整一些引數。(這跟機器學習調參比起來,簡直不是事~~)
3、粗配準
前面介紹到了,ICP演算法的基本原理。它需要一個旋轉平移矩陣的初值。這個初值如果不太正確,那麼由於它的greedy優化的策略,會使其目標函式下降到某一個區域性最優點(當然也是一個錯誤的旋轉平移矩陣)。因此,我們需要找到一個比較準確的初值,這也就是粗配準需要做的。
粗配準目前來說還是一個難點。針對於不同的資料,有許多不同的方法被提出。
我們先介紹配準的評價標準,再在這個標準下提出一些搜尋策略。
評價標準:比較通用的一個是LCP(Largetst Common Pointset)。給定兩個點集P,Q,找到一個變換T(P),使得變換後的P與Q的重疊度最大。在變換後的P內任意一點,如果在容差範圍內有另外一個Q的點,則認為該點是重合點。重合點佔所有點數量的比例就是重疊度。
解決上述LCP問題,最簡單粗暴的方法就是遍歷。假設點集P,Q的大小分別為m,n。而找到一個剛體變換需要3對對應點。那麼brute force 搜尋的需要的複雜度。對於動輒幾百萬個點的點雲,這種時間複雜度是不可接受的。因此,許多搜尋策略被提出。比較容易想到的是RANSAC之類的搜尋方法。而對於不同的場景特點,可以利用需配準點雲的特定資訊加快搜索。(例如知道點雲是由特定形狀的面構成的)這裡先介紹一個適用於各種點雲,不需要先驗資訊的搜尋策略,稱為4PC(4 Point Congruent)。
搜尋策略:4PC搜尋策略是在P,Q中找到四個共面的對應點。
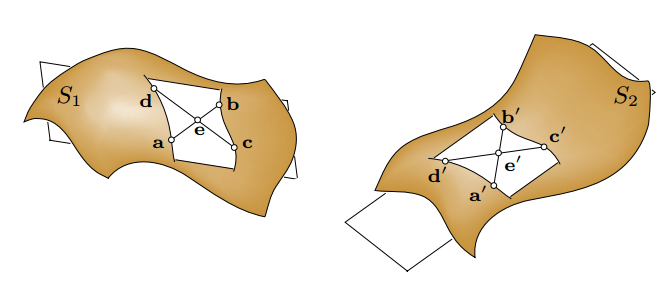
如上圖所示(來自4PC原文),這四個共面的點相交於e。這裡有兩個比例在剛體變化下是不變的。(實際上在仿射變換下也是不變的。)
而4PC將對於三個點的搜尋轉換為對e,e'的搜尋,從而將複雜度降低到了。這四個點的距離越遠,計算得到的轉換越穩健。但是這裡的四個點的搜尋依賴於兩個點雲的重疊度。
具體的演算法可以參考4-Points Congruent Sets for Robust Pairwise Surface Registration的原文。
4PC演算法通用性較好,但是對於重疊度較小、或是噪聲較大的資料也會出現配準錯誤或是執行時間過長的問題。針對於不同的場景很多其他的搜尋策略也被提出。
這裡安利一下我師兄的論文吧~Automatic registration of large-scale urban scene point clouds based on semantic feature points
我們課題組主要是研究室外地面站LiDAR獲取的點雲配準問題。這種情形下,由於掃描器內有自動安平裝置,Z軸都是豎直方向(重力方向),剛體變換隻存在三維平移與平面(XoY面上的)旋轉。我們就在場景中搜索豎直的特徵線並且得到它們與地面的交點。
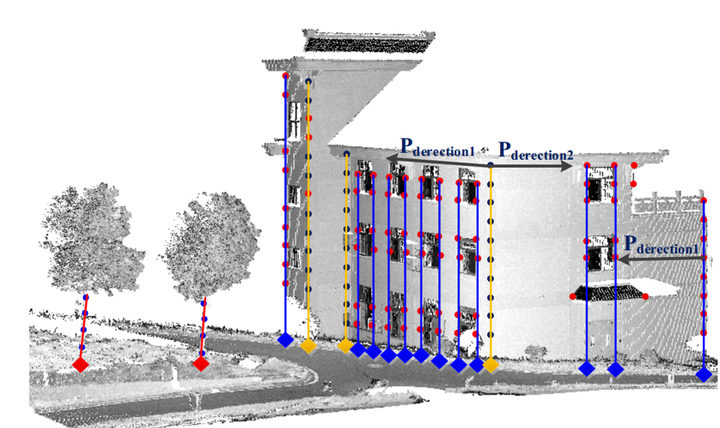
再將這些交點構建出三角形,以三角形的全等關係來得到匹配。

找出其中一致性最好的三角形集合,作為匹配的集合,進行粗配準。
這種方法適用於豎直線較多的場景,比如城區的建築物的邊線、林區樹木的樹幹等。設計的方法還是很巧妙的。當然如果場景內這種特徵較少,就比較難以配準。
(填坑完成~)
參考文獻:
[1] Besl P J, Mckay N D. Method for registration of 3-D shapes[C]// Robotics - DL tentative. International Society for Optics and Photonics, 1992:239-256.
[2] Aiger D, Mitra N J, Cohen-Or D. 4-points congruent sets for robust pairwise surface registration[J]. Acm Transactions on Graphics, 2008, 27(3):85.
[3]Yang B, Dong Z, Liang F, et al. Automatic registration of large-scale urban scene point clouds based on semantic feature points[J]. Isprs Journal of Photogrammetry & Remote Sensing, 2016, 113:43-58