
Scrapy資料流的工作流程
Scrapy資料流是由執行的核心引擎(engine)控制,流程是這樣的:
1、爬蟲引擎獲得初始請求開始抓取。
2、爬蟲引擎開始請求排程程式,並準備對下一次的請求進行抓取。
3、爬蟲排程器返回下一個請求給爬蟲引擎。
4、引擎請求傳送到下載器,通過下載中介軟體下載網路資料。
5、一旦下載器完成頁面下載,將下載結果返回給爬蟲引擎。
6、引擎將下載器的響應通過中介軟體返回給爬蟲進行處理。
7、爬蟲處理響應,並通過中介軟體返回處理後的items,以及新的請求給引擎。
8、引擎傳送處理後的items到專案管道,然後把處理結果返回給排程器,排程器計劃處理下一個請求抓取。
9、重複該過程(繼續步驟1),直到爬取完所有的url請求。
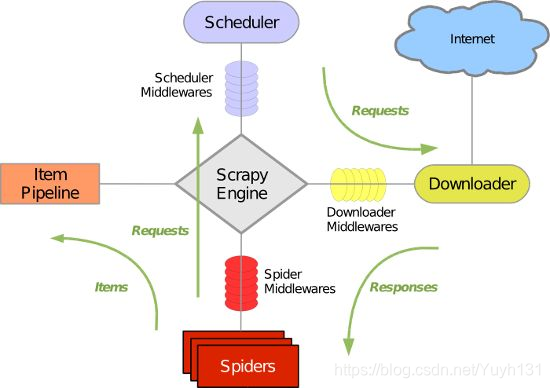
上圖展示了scrapy的所有元件工作流程,下面單獨介紹各個元件
爬蟲引擎(ENGINE)
爬蟲引擎負責控制各個元件之間的資料流,當某些操作觸發事件後都是通過engine來處理。
排程器
排程接收來engine的請求並將請求放入佇列中,並通過事件返回給engine。
下載器
通過engine請求下載網路資料並將結果響應給engine。
Spider
Spider發出請求,並處理engine返回給它下載器響應資料,以items和規則內的資料請求(urls)返回給engine。
管道專案(item pipeline)
負責處理engine返回spider解析後的資料,並且將資料持久化,例如將資料存入資料庫或者檔案。
下載中介軟體
下載中介軟體是engine和下載器互動元件,以鉤子(外掛)的形式存在,可以代替接收請求、處理資料的下載以及將結果響應給engine。
spider中介軟體
spider中介軟體是engine和spider之間的互動元件,以鉤子(外掛)的形式存在,可以代替處理response以及返回給engine items及新的請求集。