
Scrapy中的核心工作流程以及POST請求
阿新 • • 發佈:2019-01-10
五大核心元件工作流程
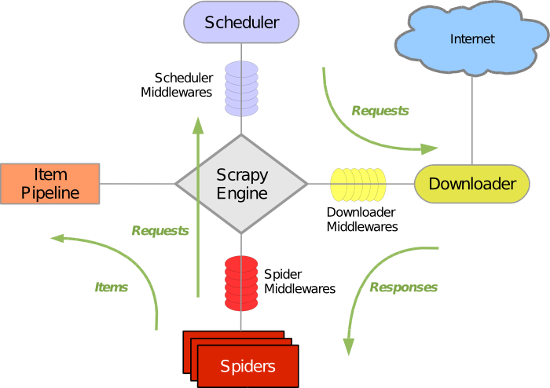
- 引擎(Scrapy)
用來處理整個系統的資料流處理, 觸發事務(框架核心) - 排程器(Scheduler)
用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址 - 下載器(Downloader)
用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的) - 爬蟲(Spiders)
爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面 - 專案管道(Pipeline)
負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。
post請求傳送
- 重寫爬蟲應用檔案中繼承Spider類的 類的裡面的start_requests(self)這個方法
def start_requests(self):#請求的url post_url = 'http://fanyi.baidu.com/sug' # post請求引數 formdata = { 'kw': 'wolf', } # 傳送post請求 yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)
遞迴爬取
- 遞迴爬取解析多頁頁面資料
- 需求:將糗事百科所有頁碼的作者和段子內容資料進行爬取切持久化儲存
- 需求分析:每一個頁面對應一個url,則scrapy工程需要對每一個頁碼對應的url依次發起請求,然後通過對應的解析方法進行作者和段子內容的解析。
- 實現方案:
1.將每一個頁碼對應的url存放到爬蟲檔案的起始url列表(start_urls)中。(不推薦)
2.使用Request方法手動發起請求。(推薦)
- 程式碼:
# -*- coding: utf-8 -*- import scrapy from qiushibaike.items import QiushibaikeItem # scrapy.http import Request class QiushiSpider(scrapy.Spider): name = 'qiushi' allowed_domains = ['www.qiushibaike.com'] start_urls = ['https://www.qiushibaike.com/text/'] #爬取多頁 pageNum = 1 #起始頁碼 url = 'https://www.qiushibaike.com/text/page/%s/' #每頁的url def parse(self, response): div_list=response.xpath('//*[@id="content-left"]/div') for div in div_list: #//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2 author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first() author=author.strip('\n') content=div.xpath('.//div[@class="content"]/span/text()').extract_first() content=content.strip('\n') item=QiushibaikeItem() item['author']=author item['content']=content yield item #提交item到管道進行持久化 #爬取所有頁碼資料 if self.pageNum <= 13: #一共爬取13頁(共13頁) self.pageNum += 1 url = format(self.url % self.pageNum) #遞迴爬取資料:callback引數的值為回撥函式(將url請求後,得到的相應資料繼續進行parse解析),遞迴呼叫parse函式 yield scrapy.Request(url=url,callback=self.parse)
五大核心元件工作流程
- 引擎(Scrapy)
用來處理整個系統的資料流處理, 觸發事務(框架核心) - 排程器(Scheduler)
用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址 - 下載器(Downloader)
用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的) - 爬蟲(Spiders)
爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面 - 專案管道(Pipeline)
負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。
post請求傳送
- 重寫爬蟲應用檔案中繼承Spider類的 類的裡面的start_requests(self)這個方法
def start_requests(self): #請求的url post_url = 'http://fanyi.baidu.com/sug' # post請求引數 formdata = { 'kw': 'wolf', } # 傳送post請求 yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)
遞迴爬取
- 遞迴爬取解析多頁頁面資料
- 需求:將糗事百科所有頁碼的作者和段子內容資料進行爬取切持久化儲存
- 需求分析:每一個頁面對應一個url,則scrapy工程需要對每一個頁碼對應的url依次發起請求,然後通過對應的解析方法進行作者和段子內容的解析。
- 實現方案:
1.將每一個頁碼對應的url存放到爬蟲檔案的起始url列表(start_urls)中。(不推薦)
2.使用Request方法手動發起請求。(推薦)
- 程式碼:
# -*- coding: utf-8 -*- import scrapy from qiushibaike.items import QiushibaikeItem # scrapy.http import Request class QiushiSpider(scrapy.Spider): name = 'qiushi' allowed_domains = ['www.qiushibaike.com'] start_urls = ['https://www.qiushibaike.com/text/'] #爬取多頁 pageNum = 1 #起始頁碼 url = 'https://www.qiushibaike.com/text/page/%s/' #每頁的url def parse(self, response): div_list=response.xpath('//*[@id="content-left"]/div') for div in div_list: #//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2 author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first() author=author.strip('\n') content=div.xpath('.//div[@class="content"]/span/text()').extract_first() content=content.strip('\n') item=QiushibaikeItem() item['author']=author item['content']=content yield item #提交item到管道進行持久化 #爬取所有頁碼資料 if self.pageNum <= 13: #一共爬取13頁(共13頁) self.pageNum += 1 url = format(self.url % self.pageNum) #遞迴爬取資料:callback引數的值為回撥函式(將url請求後,得到的相應資料繼續進行parse解析),遞迴呼叫parse函式 yield scrapy.Request(url=url,callback=self.parse)