
【python學習筆記】39:認識SQLAlchemy,簡單操作Pandas中的DataFrame
阿新 • • 發佈:2018-11-19
學習《Python3爬蟲、資料清洗與視覺化實戰》時自己的一些實踐。
認識SQLAlchemy
SQLAlchemy是Python的ORM工具,就像Java有Hibernate一樣,實現關係型資料庫中的記錄與Python自定義Class的物件的轉化,實現操作之間的對映。
書上底層用了pymysql,但是實踐中會出現問題,網上查了一下改用mysql-connector-python就可以了。
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker, 執行結果:
name:北京兩日遊,type景+酒
簡單操作Pandas中的DataFrame
Numpy那章講得比較碎,內容也比較少,沒有什麼好記錄的。Pandas資料處理這章的資料檔案要到書網站上去下載。
import pandas as pd
# (1)從csv檔案中讀取資料生成DataFrame物件.按','分割,編碼為utf-8,0號行作為列名
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# print(type(df)) # <class 'pandas.core.frame.DataFrame'>
# (2)將(剛剛讀出的)df物件中的資料寫到另一個csv檔案中.columns指定要寫的是哪些列,禁止寫入索引,儲存表頭資訊
df.to_csv("E:/Data/practice/test_in.csv", columns=['寶貝', '價格'], index=False, header=True)
# (3)取前3行(得到的還是DataFrame物件)
rows = df[0:3]
# print(rows)

# (4)取指定的某些列
cols = df[['寶貝', '成交量', '位置']]
# print(cols.head()) # 至多前5行

# (5)取前4行中的某些列.第一個維度指定行,在第二個維度上選取指定的列
print(df.ix[0:3, ['成交量', '價格']]) # 注意這裡是0:3,另外ix方法已經被棄用
# 或(使用loc按label索引)
print(df.loc[0:3, ['成交量', '價格']]) # 這裡0:3可以替換成df.index[0:4]
# 或(使用iloc按index索引)
print(df.iloc[0:4, df.columns.get_indexer(['成交量', '價格'])]) # 這裡是0:4

# (6)從已有的列中計算新的列,並直接將其寫入到df物件中
df['銷售額'] = df['價格'] * df['成交量']
# print(df.head())
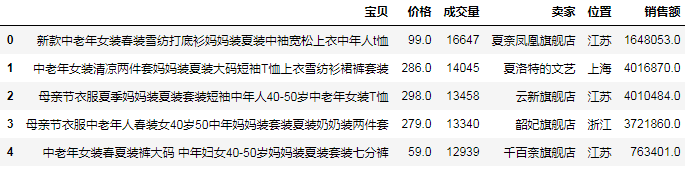
# (7)根據條件過濾行
result = df[(df['價格'] < 100) & (df['成交量'] > 10000)]
# print(result.head())

# (8)按照某個欄位排序
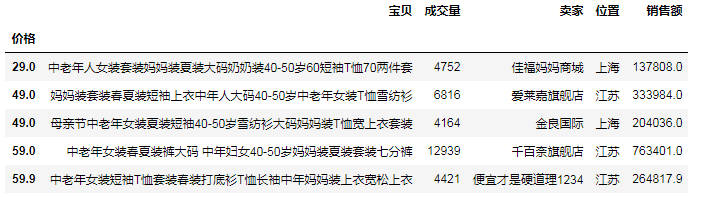
df1 = df.set_index("價格").sort_index()
# print(df1.head())
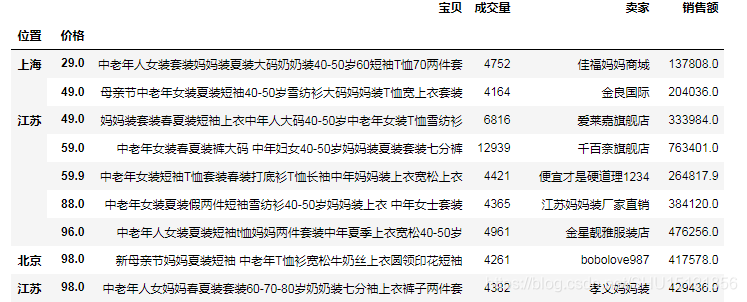
# (9)按照多個欄位排序
# 預設level是0,這裡即先"位置"再"價格"
df2 = df.set_index(['位置', '價格']).sort_index()
# print(df2)

# level設定為1時,這裡即先"價格"再"位置"
df2 = df2.sort_index(level=1)
# print(df2)
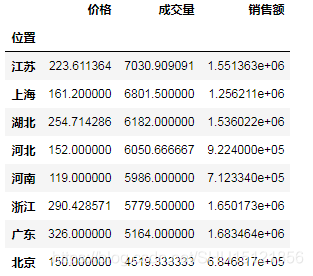
# (10)資料整理操作
# 先刪除label為'寶貝'和'賣家'的列,然後按位置分組,計算組內的均值,再按成交量進行排序(降序)
df_mean = df.drop(['寶貝', '賣家'], axis=1).groupby("位置").mean().sort_values("成交量", ascending=False)
# print(df_mean)
# 先刪除label為'寶貝'和'賣家'的列,然後按位置分組,計算組內的加和,再按成交量進行排序(降序)
df_sum = df.drop(['寶貝', '賣家'], axis=1).groupby("位置").sum().sort_values("成交量", ascending=False)
# print(df_sum)
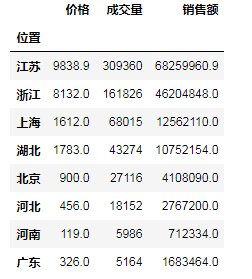
# (11)查看錶的資料資訊和描述性統計資訊
print(df.info())
print(df.describe())
