
【python學習筆記】38:使用Selenium抓取去哪兒網動態頁面
阿新 • • 發佈:2018-11-19
學習《Python3爬蟲、資料清洗與視覺化實戰》時自己的一些實踐。
在去哪兒網PC端自由行頁面,使用者需要輸入出發地和目的地,點選開始定製,然後就可以看到一系列相關的旅遊產品。在這個旅遊產品頁換頁不會改變URL,而是重新載入,這時頁碼沒有體現在URL中,這種動態頁面用傳統的爬蟲實現不了。
安裝配置
Selenium本身用Anaconda安裝,作為模擬使用者行為的自動化測試工具,它另外還要使用瀏覽器驅動。在這篇裡講述了Chrome和其驅動ChromeDriver的相容關係,驅動可以直接在官網下載,解壓後直接放在系統環境變數目錄下就可以,我放在Anaconda目錄下了。
XPath的選取和使用
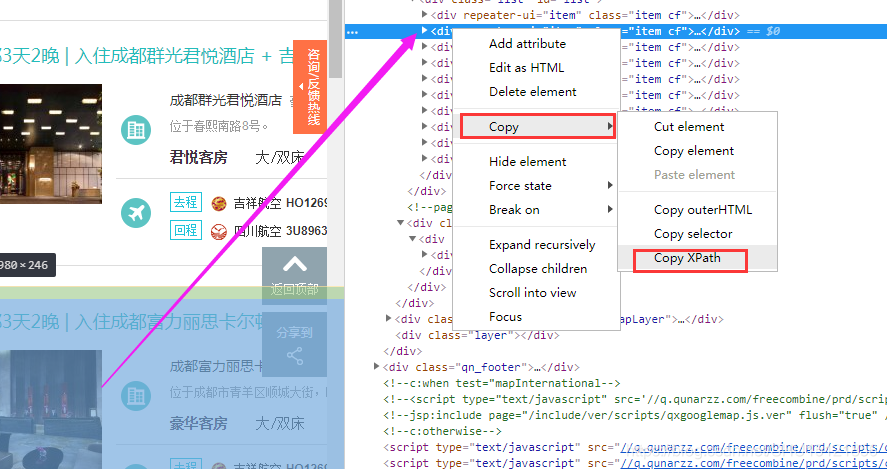
XPath使用路徑表示式來選取XML文件中的節點或節點集,在Chrome中通過檢查元素可以很方便的定位並獲取HTML中某個或某些元素的XPath:
 圖中元素的XPath是
圖中元素的XPath是//*[@id="list"]/div[2],這表示它是該列表中的第二個div,如果需要選取整個列表,在使用時XPath只要不指明下標就可以了,在這裡也就是//*[@id="list"]/div。
在使用時,注意driver.find_element_by_xpath()返回的是一個WebElement物件,driver.find_elements_by_xpath()才能返回可迭代的一系列物件,兩個函式僅有一個字母s之差,很容易弄混。
爬蟲程式碼
import requests
import urllib.request
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By # 用於指定HTML檔案中的DOM元素
from selenium.webdriver.support.ui import WebDriverWait # 用於等待網頁載入完成
from selenium.webdriver.support import expected_conditions as 執行結果
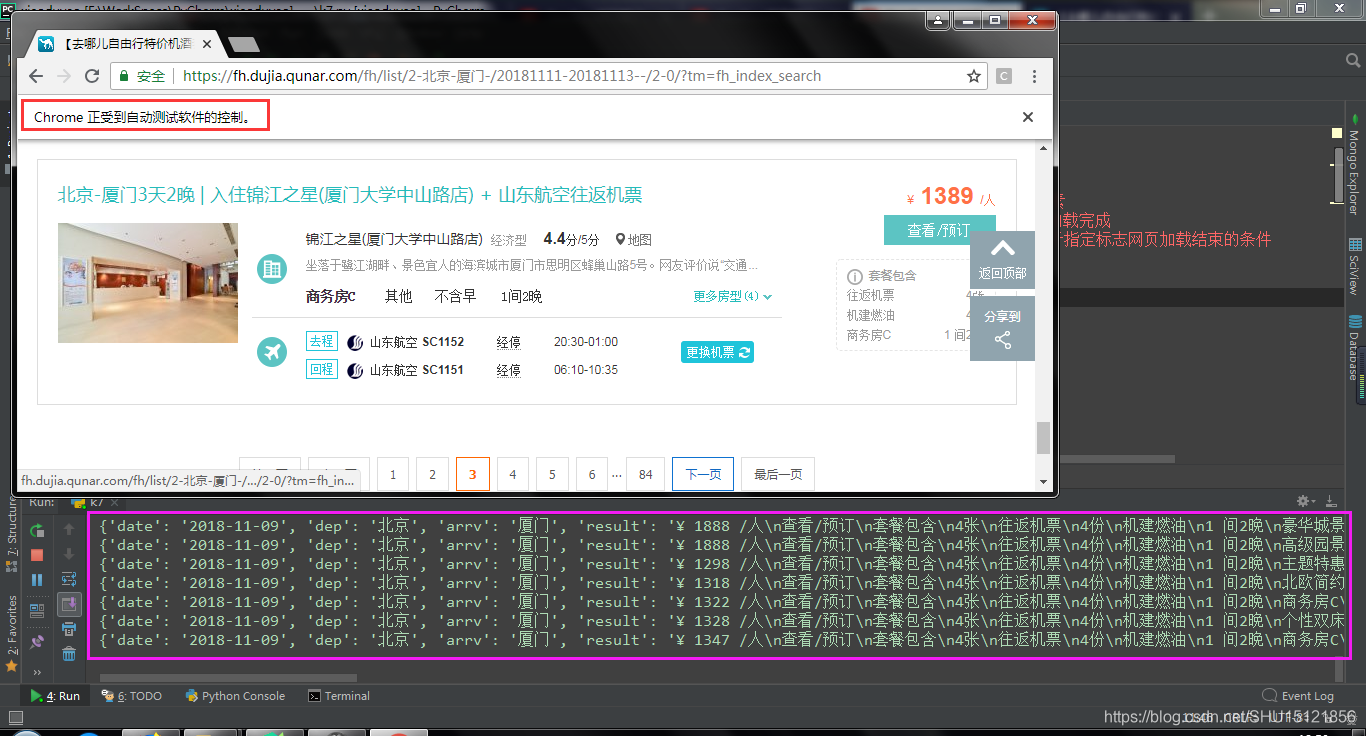
善後處理
後臺可能還存在chromedriver程序:
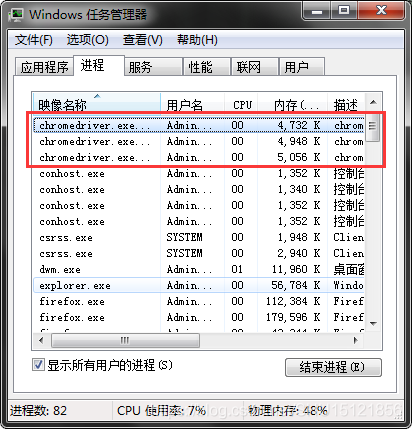
工作管理員裡右鍵->結束程序樹。