
三、支援向量機
1. 間隔與支援向量
資料集$D = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_m},{y_m})\} $,其中${{\bf{x}}_i} = \{ {x_{i1}},{x_{i2}},...,{x_{id}}\} $,包含d維特徵,${y_i} \in \{ - 1, + 1\} $。
分類學習就是在樣本空間裡找到一個超平面,能夠分離開“+”、“-”兩類。如下圖所示,在二維特徵的樣本空間裡,找到一條線能夠分離開兩類。但是針對該資料集D,這樣的線可能有很多,我們應該用哪一個呢?直觀上看,應該是正中間加粗的那條線是“最合適”的線,對訓練集D區域性擾動的“容忍”性最好。換言之,這個劃分超平面所產生的分類結果是最魯棒的,對未見
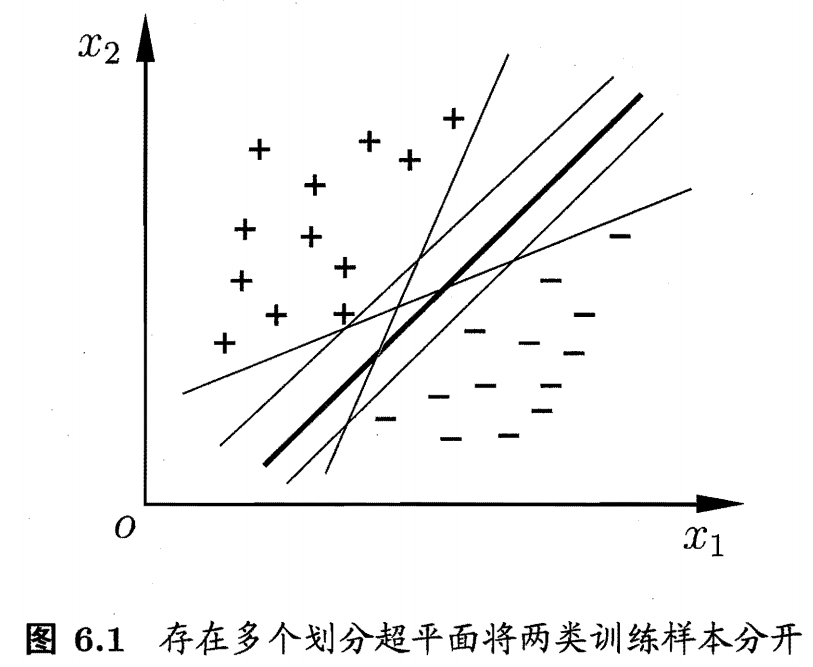
該超平面可通過線性方程來描述,${{\bf{\omega }}^T}{\bf{x}} + b = 0$,該超平面記為$({\bf{\omega }},b)$。
假設超平面$({\bf{\omega }},b)$能將訓練樣本正確分類,即對於$({{\bf{x}}_i},y_i) \in D$,若$y_i = +1$,則有${{{\bf{\omega }}^T}{{\bf{x}}_i} + b}>0$,若$y_i = -1$,則有${{{\bf{\omega }}^T}{{\bf{x}}_i} + b}<0$。令,
$\left\{ {\begin{array}{*{20}{c}}
{{{\bf{\omega }}^T}{{\bf{x}}_i} + b \ge + 1,{y_i} = + 1}\\
{{{\bf{\omega }}^T}{{\bf{x}}_i} + b \le - 1,{y_i} = - 1}
\end{array}} \right.$

距離超平面最近的這幾個訓練樣本點(如上圖中被圈出來的三個樣本點)等號成立,被稱為"支援向量" (support vector),兩個異類支援向量到超平面的距離之和為 $\gamma = \frac{2}{{\left\| {\bf{\omega }} \right\|}}$,稱為“間隔”。
我們希望在滿足樣本約束${y_i}({{\bf{\omega }}^T}{{\bf{x}}_i} + b) \ge 1$的條件下,找到具有最大間隔的劃分超平面$\mathop {\max }\limits_{{\bf{\omega }},b} \frac{2}{{\left\| {\bf{\omega }} \right\|}}$。
支援向量機的基本型如下,
$\begin{array}{l}
\mathop {\min }\limits_{{\bf{\omega }},b} \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2}\\
{\rm{s}}{\rm{.t}}{\rm{. }}{y_i}({{\bf{\omega }}^T}{{\bf{x}}_i} + b) \ge 1,i = 1,2,...,m
\end{array}$
2. 對偶問題
我們希望求解支援向量機基本型的最小化問題,來得到大間隔劃分超平面所對應的{+1,-1}二分類模型
$f({\bf{x}}) = {{\bf{\omega }}^T}{\bf{x}} + b$
怎麼求這個凸優化問題,求得最優模型引數$\bf{\omega }, b$呢?
我們對每條約束引入拉格朗日乘子$\alpha_i \ge 0$,則該問題的拉格朗日函式可寫為,
$L({\bf{\omega }},b,{\bf{\alpha }}) = \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2} + \sum\limits_{i = 1}^m {{\alpha _i}\left( {1 - {y_i}\left( {{{\bf{\omega }}^T}{{\bf{x}}_i} + b} \right)} \right)} $
該優化問題表示為,
$\mathop {{\rm{min}}}\limits_{{\rm{w,b}}} \mathop {\max }\limits_{{\alpha _i} \ge 0} L(w,b,\alpha )$
轉化為對偶問題,
$\mathop {\max }\limits_{{\alpha _i} \ge 0} \mathop {{\rm{min}}}\limits_{{\rm{w,b}}} L(w,b,\alpha )$
求$L({\bf{\omega }},b,{\bf{\alpha }})$對$\bf{\omega }$和$b$的偏導為零
$\begin{array}{l}
{\bf{\omega }} = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} {{\bf{x}}_i},\\
0 = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} .
\end{array}$
則對偶問題表示為
$\begin{array}{l}
\mathop {\max }\limits_{\bf{\alpha }} \sum\limits_{i = 1}^m {{\alpha _i} - } \frac{1}{2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}} } {y_i}{y_j}\left\langle {{{\bf{x}}_i},{{\bf{x}}_j}} \right\rangle \\
s.t. \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0,\\
{\alpha _i} \ge 0,i = 1,2,...,m.
\end{array}$
解得${\bf{\alpha }}$後,求出$\bf{\omega }$和$b$即可得到模型,
$\begin{array}{l}
f({\bf{x}}) = {{\bf{\omega }}^T}{\bf{x}} + b\\
= \sum\limits_{i = 1}^m {{\alpha _i}{y_i}{{\bf{x}}^T}{\bf{x}} + b}
\end{array}$
從對偶優化問題解出$\alpha_i$,對應著每一個樣本$({{\bf{x}}_i},y_i)$,和它滿足的約束。滿足KKT條件,
$\left\{ {\begin{array}{*{20}{c}}
{{\alpha _i} \ge 0;}\\
{{y_i}f({{\bf{x}}_i}) - 1 \ge 0;}\\
{{\alpha _i}({y_i}f({{\bf{x}}_i}) - 1) = 0.}
\end{array}} \right.$
所以,對於任意訓練樣本$({{\bf{x}}_i},y_i)$,總有$\alpha _i=0$或${y_i}f({{\bf{x}}_i})=1$。若$\alpha _i=0$,則該樣本不會在$\bf{\omega }$求和模型中出現,不會對$f({\bf{x}})$有任何影響; 若$\alpha _i>0$,則必有${y_i}f({{\bf{x}}_i})=1$,所對應的樣本點位於最大間隔邊界上,是一個支援向量。這顯示出支援向量機的一個重要性質:訓練完成後?大部分的訓練樣本都不需保留,最終模型僅與支援向量有關 。
那麼如何求解${\bf{\alpha }} = ({\alpha _1};{\alpha _2},...,{\alpha _m})$呢,這裡介紹一個高效演算法,SMO
SMO 的基本思路是先固定$\alpha _i$之外的所有引數,然後求$\alpha _i$上的極值。由於存在約束$\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0$,若固定$\alpha _i$之外的其他變數,則 $\alpha _i$可由其他變數匯出,所以SMO每次選擇兩個變數$\alpha _i$和$\alpha _j$,並固定其他引數。這樣,在引數初始化後, SMO 不斷執行如下兩個步驟直至收斂:
- 選取一對需要更新的變數$\alpha _i$和$\alpha _j$,
- 固定除$\alpha _i$和$\alpha _j$以外的引數,求解對偶優化問題,獲得更新後的$\alpha _i$和$\alpha _j$
3. 核函式