
ElasticSearch最佳入門實踐(四十八)_filter與query深入對比解密:相關度,效能
1、filter 與 query 示例
先構建兩條資料
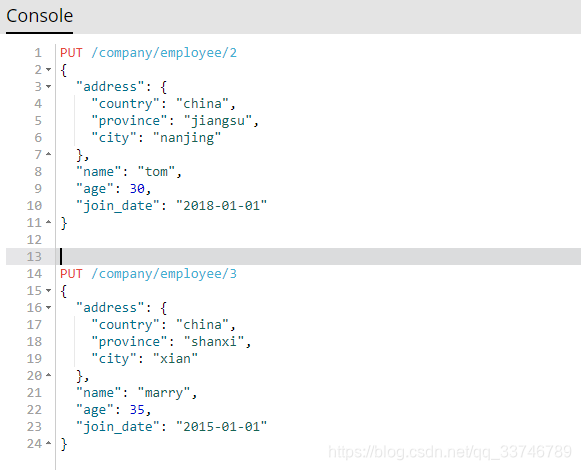
搜尋請求:年齡必須大於等於30,同時join_date必須是2018-01-01

2、filter與query對比大解密
filter,僅僅只是按照搜尋條件過濾出需要的資料而已,不計算任何相關度分數,對相關度沒有任何影響
query,會去計算每個document相對於搜尋條件的相關度,並按照相關度進行排序
一般來說,如果你是在進行搜尋,需要將最匹配搜尋條件的資料先返回,那麼用query;如果你只是要根據一些條件篩選出一部分資料,不關注其排序,那麼用filter
除非是你的這些搜尋條件,你希望越符合這些搜尋條件的document越排在前面返回,那麼這些搜尋條件要放在query中;如果你不希望一些搜尋條件來影響你的document排序,那麼就放在filter中即可
3、filter與query效能
filter,不需要計算相關度分數,不需要按照相關度分數進行排序,同時還有內建的自動cache最常使用filter的資料
query,相反,要計算相關度分數,按照分數進行排序,而且無法cache結果
相關推薦
ElasticSearch最佳入門實踐(四十八)_filter與query深入對比解密:相關度,效能
1、filter 與 query 示例 先構建兩條資料 搜尋請求:年齡必須大於等於30,同時join_date必須是2018-01-01 2、filter與query對比大解密 filter,僅僅只是按照搜尋條件過濾出需要的資料而已
ElasticSearch最佳入門實踐(四十二)什麼是mapping再次回爐透徹理解
(1)往es裡面直接插入資料,es會自動建立索引,同時建立type以及對應的mapping (2)mapping中就自動定義了每個field的資料型別 (3)不同的資料型別(比如說text和date),可能有的是exact value,有的是full text (4)exac
ElasticSearch最佳入門實踐(四十一)query string 的分詞以及 mapping 引入案例遺留問題的大揭祕
1、query string分詞 query string必須以和index建立時相同的analyzer進行分詞 query string對exact value和full text的區別對待 date:exact value _all:full text
ElasticSearch最佳入門實踐(三十八)精確匹配與全文搜尋的對比分析
1、ES中的兩種搜尋模式 1、exact value 2、full text 2、exact value 2017-01-01,exact value,搜尋的時候,必須輸入2017-01-01,才能搜尋出來。如果你輸入一個01,是搜尋不
ElasticSearch最佳入門實踐(二十八)剖析document資料路由原理
1、document路由到shard上是什麼意思? 我們這段,一個index的資料會被分為多片,每個片都在一個shard中,所以說,一個document存在於一個shard中 當客戶端建立的時候,es此時就需要決定說,這個document存在於那個shard上。 這個過程就稱
ElasticSearch最佳入門實踐(六十八)優化寫入流程實現NRT近實時(filesystem cache,refresh)
現有流程的問題,每次都必須等待fsync將segment刷入磁碟,才能將segment開啟供search使用,這樣的話,從一個document寫入,到它可以被搜尋,可能會超過1分鐘!!!這就不是近實時的搜尋了!!!主要瓶頸在於fsync實際發生磁碟IO寫資料進磁碟,是很耗時的。
ElasticSearch最佳入門實踐(四十九)各種query搜尋語法
1、match all 查詢所有 GET /_search { "query": { "match_all": {} } } 2、match 匹配某一個filed是否包含文字 GET /_search {
ElasticSearch最佳入門實踐(五十八)搜尋相關引數梳理以及bouncing results問題解決方案
1、preference 決定了哪些shard會被用來執行搜尋操作 _primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3 bounci
ElasticSearch最佳入門實踐(四十七)query DSL搜尋語法
1、一個例子讓你明白什麼是Query DSL GET /_search { "query": { "match_all": {} } } 2、Query DSL的基本語
ElasticSearch最佳入門實踐(四十)分詞器的內部組成到底是什麼,以及內建分詞器的介紹
1、什麼是分詞器 一個分詞器,很重要,將一段文字進行各種處理,最後處理好的結果才會拿去建立倒排索引 切分詞語,normalization(提升recall召回率) 給你一段句子,然後將這段句子拆分成一個一個的單個的單詞,同時對每個單詞進行normalizat
ElasticSearch最佳入門實踐(四十四)手動建立和修改mapping以及定製string型別資料是否分詞
1、如何建立索引 如果想設定 string 為分詞 把它設定為 analyzed not_analyzed 則是 設定為 exact value 全匹配 no 則 是不能被索引和匹配 2、修改mapping 注意事項:只能建立index時手動建立mapp
ElasticSearch最佳入門實踐(三十九)倒排索引核心原理揭祕
1、例子,兩段文字 doc1:I really liked my small dogs, and I think my mom also liked them doc2:He never liked any dogs, so I hope that my m
ElasticSearch最佳入門實踐(三十七)用一個例子告訴你 mapping 到底是什麼
1、插入幾條資料 PUT /website/article/1 { "post_date": "2017-01-01", "title": "my first article", "content": "this is my first article in this w
ElasticSearch最佳入門實踐(三十六)query string search 語法以及 _all metadata 原理揭祕
1、query string基礎語法 GET /test_index/test_type/_search?q=test_field:test GET /test_index/test_type/_search?q=+test_field:test
ElasticSearch最佳入門實踐(三十五)分頁搜尋以及deep paging效能問題深度揭祕
1、如何使用es進行分頁搜尋的語法 size,from GET /_search?size=10 GET /_search?size=10&from=0 GET /_search?size=10&from=20 假設將這6條資料分成3頁,每一頁是2
ElasticSearch最佳入門實踐(三十二)bulk api的奇特json格式與底層效能優化關係揭祕
1、bulk api奇特的json格式 {"action": {"meta"}}\n {"data"}\n {"action": {"meta"}}\n {"data"}\n 2、bulk中的每個操作都可能要轉發到不同的node的shard去執行 3、如果採用比較良好的js
ElasticSearch最佳入門實踐(三十一)document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node 對於讀請求,不一定所有的請求都發送的primary shard 上去,也可以轉發到replied shard 上去,因為replied shard 也是可以服務所有讀請求的 2、coordin
ElasticSearch最佳入門實踐(二十九)document增刪改內部原理揭祕
步驟 (1)客戶端選擇一個node傳送請求過去,這個node就是coordinating node(協調節點) (2)coordinating node,對document進行路由,將請求轉發給對應的node(有primary shard) (3)實際的node上的prima
ElasticSearch最佳入門實踐(二十五)mget批量查詢api
1、批量查詢的好處 就是一條一條的查詢,比如說要查詢100條資料,那麼就要傳送100次網路請求,這個開銷還是很大的 如果進行批量查詢的話,查詢100條資料,就只要傳送1次網路請求,網路請求的效能開銷縮減100倍 2、mget的語法 可以說mget是很重要
ElasticSearch最佳入門實踐(二十七)總結以及什麼是distributed document store
1、總結 快速入門了一下,最基本的原理,最基本的操作 在入門之後,對ES的分散式的基本原理,進行了相對深入一些的剖析 圍繞著document這個東西,進行操作,進行講解和分析 2、什麼是distributed document s