
Boosting演算法(GBDT,XGBoost,LightGBM)
1. 引言
提升(Boosting)是一種機器學習技術,可以用於迴歸和分類問題,它每一步產生一個弱預測模型(如決策樹),並加權累加到總模型中加權累加到總模型中;如果每一步的弱預測模型生成都是依據損失函式的梯度方向,則稱之為梯度提升(Gradient Boosting)。
梯度提升演算法首先給定一個目標損失函式,它的定義域是所有可行的弱函式集合(基函式);提升演算法通過迭代的選擇一個負梯度方向上的基函式來逐漸逼近區域性最小值。這種在函式域的梯度提升觀點對機器學習的很多領域都有深刻影響。
提升的理論意義:如果一個問題存在弱分類器,則可以通過提升的辦法得到強分類器。
2. Boosting演算法基本原理
- 給定輸入向量 x 和輸出變數 y 組成的若干訓練樣本(x1,y1)…(xn,yn),目標是找到近似函式F(X), 使得損失函式L (y, F(X))的損失值最小
- L(y, F(X))的典型定義為
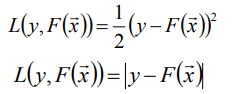
注:我們選擇損失函式是和y的分佈有關的,我們習慣選擇第一個損失函式,這是我們是先驗性認為y是服從正態分佈的;當我們選擇第二個損失函式我們是認為y服從拉布拉斯分佈。 - 確定最優函式F*(X),即(能夠使損失函式值最小化的函式):
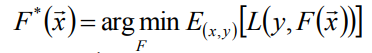
- 假定F(X)是一組基函式f(X)的加權和:
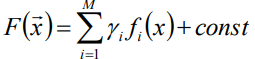
Boosting演算法推導
目標:梯度提升方法尋找最優解,使得損失函式在訓練集上的期望最小。
-
給定常函式F0(x):
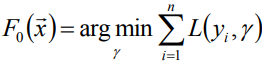
-
以貪心的思路擴充套件得到Fm(x):
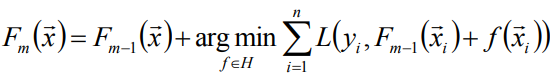
-
因為貪心法在每次選擇最優基函式f時仍然困難,在這裡使用梯度下降的方法近似計算。將樣本帶入到基函式f中得到f(x1),f(x2),f(x3)…f(xn),從而L退化為向量L(y1,f(x1)), L(y2, f(x2))…L(yn, f(xn)
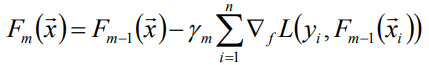
-
上式中的權值γ為梯度下降的步長,可使用線性搜尋求最優步長:
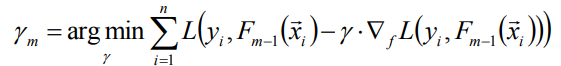
-
初始化給定模型為常數
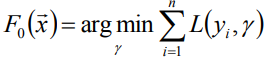
-
對於m=1到m
(1) 計算偽殘差
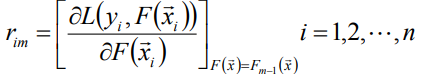
(2)使用資料計算擬合殘差fm(x)
(3)計算步長γ:
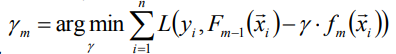
此時(3)已經轉化為一維優化問題
(4)更新模型

3. GBDT( Gradient Boosting Decison Tree)
概要
- 梯度提升的典型基函式即決策樹(特別是CART)
- GBDT的提升演算法與上類似 f(x)即tm(x):
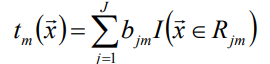
一個樹最重要的就是葉子節點和他的權值,其中bjm的預測值(權值),I表示所屬葉子節點。
演算法和上述提升演算法類似但更為優化;
引數設定和正則化
- 對訓練集擬合過高會降低模型的泛化能力,需要使用正則化技術來降低過擬合。對於複雜模型增加懲罰項,如:模型複雜度正比於葉節點數目或者葉節點預測值的平方和等;決策樹剪枝。
- 葉節點數目控制了輸的層次,一般選擇4<=j<=8
- 葉節點包含的最少樣本數目。防止出現過小的葉節點,降低預測方差
- 梯度提升迭代次數M。增加M可降低訓練集的損失值,擔憂過擬合風險。
- 交叉驗證
衰減因子,降取樣
衰減Shrinkage:
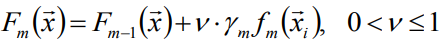
其中v稱為學習率,v=1即為原始模型;推薦選擇v<0.1的小學習率,單會造成迭代次數增多。
GBDT小結
- 損失函式是最小平方誤差,絕對值誤差等,側圍迴歸問題;而誤差函式換成多類別Logistic似然函式,側圍分類問題。
- 對目標函式分解成若干基函式的加權和,是最常見的技術手段:神經網路,徑向基函式,傅立葉/小波變換,SVM中都有它的影子。
4. XGBoost
XGBoost與GBDT
相比於GBDT總的來說XGBoost的功能更加強大,效能更加問題,適用範圍更加廣,但它們仍各有優缺點。
- 傳統的GBDT是以CART作為基分類器,特指梯度提升決策樹演算法。而XGBoost還支援線性分類器(gblinear) 這個時候XGBoost相當於帶L1和L2正則化項的logistic迴歸(分類問題)或者線性迴歸(迴歸問題)
- 傳統GBDT在優化時只用到一階導數資訊,xgboost則對代價函式進行了二階泰勒展開,同時用到了一階和二階導數。
- xgboost在代價函式里加入了正則項,用於控制模型的複雜度。正則項裡包含了樹的葉子節點個數、每個葉子節點上輸出的score的L2模的平方和。從Bias-variance tradeoff角度來講,正則項降低了模型的variance,使學習出來的模型更加簡單,防止過擬合,這也是xgboost優於傳統GBDT的一個特性。
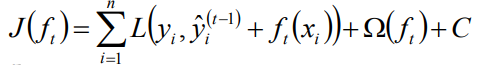
其中正則項控制著模型的複雜度,包括了葉子節點數目T和leaf score的L2的平方: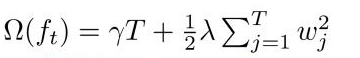
- xgboost中樹節點分裂時所採用的公式:
Shrinkage(縮減),相當於學習速率(xgboost中的eta)。xgboost在進行完一次迭代後,會將葉子節點的權重乘上該係數,主要是為了削弱每棵樹的影響,讓後面有更大的學習空間。實際應用中,一般把eta設定得小一點,然後迭代次數設定得大一點。(傳統GBDT的實現也有學習速率) - 列抽樣(column subsampling)。xgboost借鑑了隨機森林的做法,支援列抽樣,不僅能降低過擬合,還能減少計算,這也是xgboost異於傳統gbdt的一個特性。
- 對缺失值的處理。對於特徵的值有缺失的樣本,xgboost可以自動學習出它的分裂方向。
- xgboost工具支援並行。注意xgboost的並行不是tree粒度的並行,xgboost也是一次迭代完才能進行下一次迭代的(第t次迭代的代價函式裡包含了前面t-1次迭代的預測值)。xgboost的並行是在特徵粒度上的。我們知道,決策樹的學習最耗時的一個步驟就是對特徵的值進行排序(因為要確定最佳分割點),xgboost在訓練之前,預先對資料進行了排序,然後儲存為block結構,後面的迭代中重複地使用這個結構,大大減小計算量。這個block結構也使得並行成為了可能,在進行節點的分裂時,需要計算每個特徵的增益,最終選增益最大的那個特徵去做分裂,那麼各個特徵的增益計算就可以開多執行緒進行。(特徵粒度上的並行,block結構,預排序)
這篇部落格對於XGBoost中目標函式的優化原理,計算方法沒有詳細說明,感興趣的可以自行查閱資料。
5. LightGBM
lightGBM:基於決策樹演算法的分散式梯度提升框架。lightGBM與XGBoost的區別:
總的來說相較於XGBoost速度更快,記憶體消耗更低。
-
切分演算法(切分點的選取)
佔用的記憶體更低,只儲存特徵離散化後的值,而這個值一般用8位整型儲存就足夠了,記憶體消耗可以降低為原來的1/8。
降低了計算的代價:預排序演算法每遍歷一個特徵值就需要計算一次分裂的增益,而直方圖演算法只需要計算k次(k可以認為是常數),時間複雜度從O(#data#feature)優化到O(k#features)。(相當於LightGBM犧牲了一部分切分的精確性來提高切分的效率,實際應用中效果還不錯)
空間消耗大,需要儲存資料的特徵值以及特徵排序的結果(比如排序後的索引,為了後續快速計算分割點),需要消耗兩倍於訓練資料的記憶體
時間上也有較大開銷,遍歷每個分割點時都需要進行分裂增益的計算,消耗代價大 -
對cache優化不友好,在預排序後,特徵對梯度的訪問是一種隨機訪問,並且不同的特徵訪問的順序不一樣,無法對cache進行優化。同時,在每一層長樹的時候,需要隨機訪問一個行索引到葉子索引的陣列,並且不同特徵訪問的順序也不一樣,也會造成較大的cache miss。
-
XGBoost使用的是pre-sorted演算法(對所有特徵都按照特徵的數值進行預排序,基本思想是對所有特徵都按照特徵的數值進行預排序;然後在遍歷分割點的時候用O(#data)的代價找到一個特徵上的最好分割點最後,找到一個特徵的分割點後,將資料分裂成左右子節點。優點是能夠更精確的找到資料分隔點;但這種做法有以下缺點
LightGBM使用的是histogram演算法,基本思想是先把連續的浮點特徵值離散化成k個整數,同時構造一個寬度為k的直方圖。在遍歷資料的時候,根據離散化後的值作為索引在直方圖中累積統計量,當遍歷一次資料後,直方圖累積了需要的統計量,然後根據直方圖的離散值,遍歷尋找最優的分割點;優點在於 -
決策樹生長策略上:
XGBoost採用的是帶深度限制的level-wise生長策略,Level-wise過一次資料可以能夠同時分裂同一層的葉子,容易進行多執行緒優化,不容易過擬合;但不加區分的對待同一層的葉子,帶來了很多沒必要的開銷(因為實際上很多葉子的分裂增益較低,沒必要進行搜尋和分裂)
LightGBM採用leaf-wise生長策略,每次從當前所有葉子中找到分裂增益最大(一般也是資料量最大)的一個葉子,然後分裂,如此迴圈;但會生長出比較深的決策樹,產生過擬合(因此 LightGBM 在leaf-wise之上增加了一個最大深度的限制,在保證高效率的同時防止過擬合)。 -
histogram 做差加速。一個容易觀察到的現象:一個葉子的直方圖可以由它的父親節點的直方圖與它兄弟的直方圖做差得到。通常構造直方圖,需要遍歷該葉子上的所有資料,但直方圖做差僅需遍歷直方圖的k個桶。利用這個方法,LightGBM可以在構造一個葉子的直方圖後,可以用非常微小的代價得到它兄弟葉子的直方圖,在速度上可以提升一倍。
-
直接支援類別特徵:LightGBM優化了對類別特徵的支援,可以直接輸入類別特徵,不需要額外的0/1展開。並在決策樹演算法上增加了類別特徵的決策規則。
-
分散式訓練方法上(並行優化)
在特徵並行演算法中,通過在本地儲存全部資料避免對資料切分結果的通訊;
在資料並行中使用分散規約(Reduce scatter)把直方圖合併的任務分攤到不同的機器,降低通訊和計算,並利用直方圖做差,進一步減少了一半的通訊量。基於投票的資料並行(Parallel Voting)則進一步優化資料並行中的通訊代價,使通訊代價變成常數級別。
特徵並行的主要思想是在不同機器在不同的特徵集合上分別尋找最優的分割點,然後在機器間同步最優的分割點。
資料並行則是讓不同的機器先在本地構造直方圖,然後進行全域性的合併,最後在合併的直方圖上面尋找最優分割點。
小結:演算法不分優劣,適合的就是最好的。