
人工智慧、機器學習、深度學習、神經網路概念說明
首先要簡單區別幾個概念:人工智慧,機器學習,深度學習,神經網路。這幾個詞應該是出現的最為頻繁的,但是他們有什麼區別呢?
人工智慧:人類通過直覺可以解決的問題,如:自然語言理解,影象識別,語音識別等,計算機很難解決,而人工智慧就是要解決這類問題。
機器學習:機器學習是一種能夠賦予機器學習的能力以此讓它完成直接程式設計無法完成的功能的方法。但從實踐的意義上來說,機器學習是一種通過利用資料,訓練出模型,然後使用模型預測的一種方法。
深度學習:其核心就是自動將簡單的特徵組合成更加複雜的特徵,並用這些特徵解決問題。
神經網路:最初是一個生物學的概念,一般是指大腦神經元,觸點,細胞等組成的網路,用於產生意識,幫助生物思考和行動,後來人工智慧受神經網路的啟發,發展出了人工神經網路。
來一張圖就比較清楚了,如下圖:
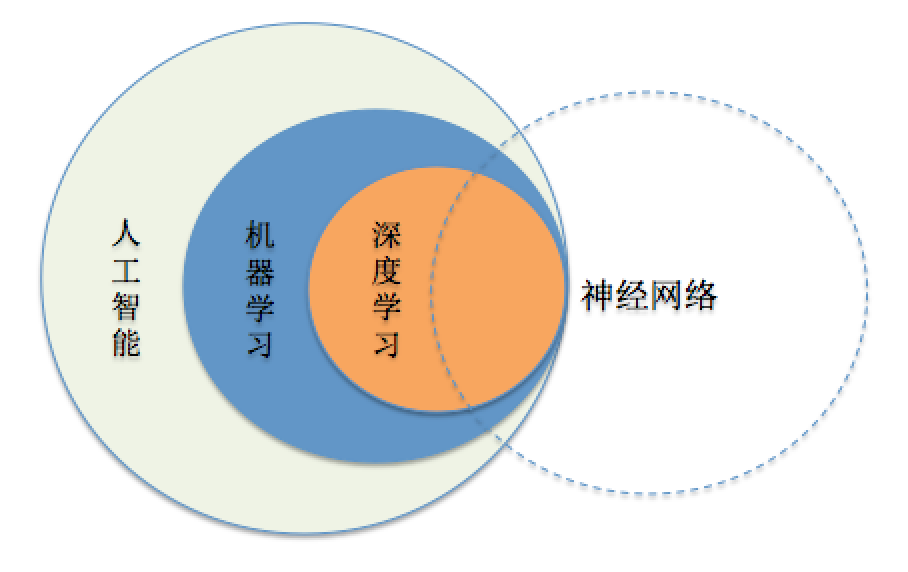
機器學習的範圍
機器學習跟模式識別,統計學習,資料探勘,計算機視覺,語音識別,自然語言處理等領域有著很深的聯絡。

模式識別
模式識別=機器學習。兩者的主要區別在於前者是從工業界發展起來的概念,後者則主要源自計算機學科。在著名的《Pattern Recognition And Machine Learning》這本書中,Christopher M. Bishop在開頭是這樣說的“模式識別源自工業界,而機器學習來自於計算機學科。不過,它們中的活動可以被視為同一個領域的兩個方面,同時在過去的10年間,它們都有了長足的發展”。
資料探勘
資料探勘=機器學習+資料庫。這幾年資料探勘的概念實在是太耳熟能詳。幾乎等同於炒作。但凡說資料探勘都會吹噓資料探勘如何如何,例如從資料中挖出金子,以及將廢棄的資料轉化為價值等等。但是,我儘管可能會挖出金子,但我也可能挖的是“石頭”啊。這個說法的意思是,資料探勘僅僅是一種思考方式,告訴我們應該嘗試從資料中挖掘出知識,但不是每個資料都能挖掘出金子的,所以不要神話它。一個系統絕對不會因為上了一個數據挖掘模組就變得無所不能(這是IBM最喜歡吹噓的),恰恰相反,一個擁有資料探勘思維的人員才是關鍵,而且他還必須對資料有深刻的認識,這樣才可能從資料中匯出模式指引業務的改善。大部分資料探勘中的演算法是機器學習的演算法在資料庫中的優化。
統計學習
統計學習近似等於機器學習。統計學習是個與機器學習高度重疊的學科。因為機器學習中的大多數方法來自統計學,甚至可以認為,統計學的發展促進機器學習的繁榮昌盛。例如著名的支援向量機演算法,就是源自統計學科。但是在某種程度上兩者是有分別的,這個分別在於:統計學習者重點關注的是統計模型的發展與優化,偏數學,而機器學習者更關注的是能夠解決問題,偏實踐,因此機器學習研究者會重點研究學習演算法在計算機上執行的效率與準確性的提升。
計算機視覺
計算機視覺=影象處理+機器學習。影象處理技術用於將影象處理為適合進入機器學習模型中的輸入,機器學習則負責從影象中識別出相關的模式。計算機視覺相關的應用非常的多,例如百度識圖、手寫字元識別、車牌識別等等應用。這個領域是應用前景非常火熱的,同時也是研究的熱門方向。隨著機器學習的新領域深度學習的發展,大大促進了計算機影象識別的效果,因此未來計算機視覺界的發展前景不可估量。
語音識別
語音識別=語音處理+機器學習。語音識別就是音訊處理技術與機器學習的結合。語音識別技術一般不會單獨使用,一般會結合自然語言處理的相關技術。目前的相關應用有蘋果的語音助手siri等。
自然語言處理
自然語言處理=文字處理+機器學習。自然語言處理技術主要是讓機器理解人類的語言的一門領域。在自然語言處理技術中,大量使用了編譯原理相關的技術,例如詞法分析,語法分析等等,除此之外,在理解這個層面,則使用了語義理解,機器學習等技術。作為唯一由人類自身創造的符號,自然語言處理一直是機器學習界不斷研究的方向。按照百度機器學習專家餘凱的說法“聽與看,說白了就是阿貓和阿狗都會的,而只有語言才是人類獨有的”。如何利用機器學習技術進行自然語言的的深度理解,一直是工業和學術界關注的焦點。
機器學習的方法
1、迴歸演算法
在大部分機器學習課程中,迴歸演算法都是介紹的第一個演算法。原因有兩個:一.迴歸演算法比較簡單,介紹它可以讓人平滑地從統計學遷移到機器學習中。二.迴歸演算法是後面若干強大演算法的基石,如果不理解迴歸演算法,無法學習那些強大的演算法。迴歸演算法有兩個重要的子類:即線性迴歸和邏輯迴歸。
實現方面的話,邏輯迴歸只是對對線性迴歸的計算結果加上了一個Sigmoid函式,將數值結果轉化為了0到1之間的概率(Sigmoid函式的影象一般來說並不直觀,你只需要理解對數值越大,函式越逼近1,數值越小,函式越逼近0),接著我們根據這個概率可以做預測,例如概率大於0.5,則這封郵件就是垃圾郵件,或者腫瘤是否是惡性的等等。從直觀上來說,邏輯迴歸是畫出了一條分類線,見下圖。

邏輯迴歸演算法劃出的分類線基本都是線性的(也有劃出非線性分類線的邏輯迴歸,不過那樣的模型在處理資料量較大的時候效率會很低),這意味著當兩類之間的界線不是線性時,邏輯迴歸的表達能力就不足。
2、神經網路
讓我們看一個簡單的神經網路的邏輯架構。在這個網路中,分成輸入層,隱藏層,和輸出層。輸入層負責接收訊號,隱藏層負責對資料的分解與處理,最後的結果被整合到輸出層。每層中的一個圓代表一個處理單元,可以認為是模擬了一個神經元,若干個處理單元組成了一個層,若干個層再組成了一個網路,也就是"神經網路"。

在神經網路中,每個處理單元事實上就是一個邏輯迴歸模型,邏輯迴歸模型接收上層的輸入,把模型的預測結果作為輸出傳輸到下一個層次。通過這樣的過程,神經網路可以完成非常複雜的非線性分類。
3、SVM(支援向量機)
支援向量機演算法從某種意義上來說是邏輯迴歸演算法的強化:通過給予邏輯迴歸演算法更嚴格的優化條件,支援向量機演算法可以獲得比邏輯迴歸更好的分類界線。但是如果沒有某類函式技術,則支援向量機演算法最多算是一種更好的線性分類技術。
但是,通過跟高斯“核”的結合,支援向量機可以表達出非常複雜的分類界線,從而達成很好的的分類效果。“核”事實上就是一種特殊的函式,最典型的特徵就是可以將低維的空間對映到高維的空間。
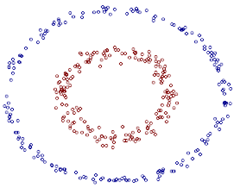
我們如何在二維平面劃分出一個圓形的分類界線?在二維平面可能會很困難,但是通過“核”可以將二維空間對映到三維空間,然後使用一個線性平面就可以達成類似效果。也就是說,二維平面劃分出的非線性分類界線可以等價於三維平面的線性分類界線。於是,我們可以通過在三維空間中進行簡單的線性劃分就可以達到在二維平面中的非線性劃分效果。
支援向量機是一種數學成分很濃的機器學習演算法(相對的,神經網路則有生物科學成分)。在演算法的核心步驟中,有一步證明,即將資料從低維對映到高維不會帶來最後計算複雜性的提升。於是,通過支援向量機演算法,既可以保持計算效率,又可以獲得非常好的分類效果。因此支援向量機在90年代後期一直佔據著機器學習中最核心的地位,基本取代了神經網路演算法。直到現在神經網路藉著深度學習重新興起,兩者之間才又發生了微妙的平衡轉變。
4、聚類演算法
無監督演算法中最典型的代表就是聚類演算法。
讓我們還是拿一個二維的資料來說,某一個數據包含兩個特徵。我希望通過聚類演算法,給他們中不同的種類打上標籤,我該怎麼做呢?簡單來說,聚類演算法就是計算種群中的距離,根據距離的遠近將資料劃分為多個族群。
聚類演算法中最典型的代表就是K-Means演算法。
5、降維演算法
降維演算法也是一種無監督學習演算法,其主要特徵是將資料從高維降低到低維層次。
降維演算法的主要作用是壓縮資料與提升機器學習其他演算法的效率。通過降維演算法,可以將具有幾千個特徵的資料壓縮至若干個特徵。另外,降維演算法的另一個好處是資料的視覺化,例如將5維的資料壓縮至2維,然後可以用二維平面來可視。降維演算法的主要代表是PCA演算法(即主成分分析演算法)。
6、推薦演算法
推薦演算法是目前業界非常火的一種演算法,在電商界,如亞馬遜,天貓,京東等得到了廣泛的運用。推薦演算法的主要特徵就是可以自動向使用者推薦他們最感興趣的東西,從而增加購買率,提升效益。推薦演算法有兩個主要的類別:
一類是基於物品內容的推薦,是將與使用者購買的內容近似的物品推薦給使用者,這樣的前提是每個物品都得有若干個標籤,因此才可以找出與使用者購買物品類似的物品,這樣推薦的好處是關聯程度較大,但是由於每個物品都需要貼標籤,因此工作量較大。
另一類是基於使用者相似度的推薦,則是將與目標使用者興趣相同的其他使用者購買的東西推薦給目標使用者,例如小A歷史上買了物品B和C,經過演算法分析,發現另一個與小A近似的使用者小D購買了物品E,於是將物品E推薦給小A。
兩類推薦都有各自的優缺點,在一般的電商應用中,一般是兩類混合使用。推薦演算法中最有名的演算法就是協同過濾演算法。
7、其他
除了以上演算法之外,機器學習界還有其他的如高斯判別,樸素貝葉斯,決策樹等等演算法。但是上面列的六個演算法是使用最多,影響最廣,種類最全的典型。機器學習界的一個特色就是演算法眾多,發展百花齊放。
下面做一個總結,按照訓練的資料有無標籤,可以將上面演算法分為監督學習演算法和無監督學習演算法,但推薦演算法較為特殊,既不屬於監督學習,也不屬於非監督學習,是單獨的一類。
監督學習演算法:
線性迴歸,邏輯迴歸,神經網路,SVM
無監督學習演算法:
聚類演算法,降維演算法
特殊演算法:
推薦演算法
除了這些演算法以外,有一些演算法的名字在機器學習領域中也經常出現。但他們本身並不算是一個機器學習演算法,而是為了解決某個子問題而誕生的。你可以理解他們為以上演算法的子演算法,用於大幅度提高訓練過程。其中的代表有:梯度下降法,主要運用線上型迴歸,邏輯迴歸,神經網路,推薦演算法中;牛頓法,主要運用線上型迴歸中;BP演算法,主要運用在神經網路中;SMO演算法,主要運用在SVM中。
機器學習的分類
目前機器學習主流分為:監督學習,無監督學習,強化學習。
a) 監督學習是最常見的一種機器學習,它的訓練資料是有標籤的,訓練目標是能夠給新資料(測試資料)以正確的標籤。例如,將郵件進行是否垃圾郵件的分類,一開始我們先將一些郵件及其標籤(垃圾郵件或非垃圾郵件)一起進行訓練,學習模型不斷捕捉這些郵件與標籤間的聯絡進行自我調整和完善,然後我們給一些不帶標籤的新郵件,讓該模型對新郵件進行是否是垃圾郵件的分類。
b) 無監督學習常常被用於資料探勘,用於在大量無標籤資料中發現些什麼。無監督主要有三種:聚類、離散點檢測和降維。
它的訓練資料是無標籤的,訓練目標是能對觀察值進行分類或者區分等。例如無監督學習應該能在不給任何額外提示的情況下,僅依據所有“貓”的圖片的特徵,將“貓”的圖片從大量的各種各樣的圖片中將區分出來。
c) 強化學習通常被用在機器人技術上(例如機械狗),它接收機器人當前狀態,演算法的目標是訓練機器來做出各種特定行為。工作流程多是:機器被放置在一個特定環境中,在這個環境裡機器可以持續性地進行自我訓練,而環境會給出或正或負的反饋。機器會從以往的行動經驗中得到提升並最終找到最好的知識內容來幫助它做出最有效的行為決策。
機器學習模型的評估
拿貓的識別來舉例,假設機器通過學習,已經具備了一定的識別能力。那麼,我們輸入4張圖片,機器的判斷如下:

常用的評價指標有三種:準確率(precision)、召回率(recall)和精準率(accuracy),其中:
Precision = TP/(TP+FP),表示我們抓到的人中,抓對了的比例;
Recall = TP/ (TP+FN),表示我們抓到的壞人佔所有壞人的比例;
Accuracy = (TP + TN)/ All ,表示識別對了(好人被識別成好人,壞人被識別成壞人)的比例。
三個指標越高,表示演算法的適應性越好。
機器學習的應用
機器學習與大資料的結合產生了巨大的價值。基於機器學習技術的發展,資料能夠“預測”。對人類而言,積累的經驗越豐富,閱歷也廣泛,對未來的判斷越準確。例如常說的“經驗豐富”的人比“初出茅廬”的小夥子更有工作上的優勢,就在於經驗豐富的人獲得的規律比他人更準確。而在機器學習領域,根據著名的一個實驗,有效的證實了機器學習界一個理論:即機器學習模型的資料越多,機器學習的預測的效率就越好。
機器學習界的名言:成功的機器學習應用不是擁有最好的演算法,而是擁有最多的資料!
在大資料的時代,有好多優勢促使機器學習能夠應用更廣泛。例如隨著物聯網和移動裝置的發展,我們擁有的資料越來越多,種類也包括圖片、文字、視訊等非結構化資料,這使得機器學習模型可以獲得越來越多的資料。同時大資料技術中的分散式計算Map-Reduce使得機器學習的速度越來越快,可以更方便的使用。種種優勢使得在大資料時代,機器學習的優勢可以得到最佳的發揮。
機器學習的子類--深度學習
2006年,Geoffrey Hinton在科學雜誌《Science》上發表了一篇文章,論證了兩個觀點:
1.多隱層的神經網路具有優異的特徵學習能力,學習得到的特徵對資料有更本質的刻畫,從而有利於視覺化或分類;
2.深度神經網路在訓練上的難度,可以通過“逐層初始化” 來有效克服。
通過這樣的發現,不僅解決了神經網路在計算上的難度,同時也說明了深層神經網路在學習上的優異性。從此,神經網路重新成為了機器學習界中的主流強大學習技術。同時,具有多個隱藏層的神經網路被稱為深度神經網路,基於深度神經網路的學習研究稱之為深度學習。
目前業界許多的影象識別技術與語音識別技術的進步都源於深度學習的發展,除了本文開頭所提的Cortana等語音助手,還包括一些影象識別應用,其中典型的代表就是下圖的百度識圖功能。
深度學習屬於機器學習的子類。基於深度學習的發展極大的促進了機器學習的地位提高,更進一步地,推動了業界對機器學習父類人工智慧夢想的再次重視。
機器學習的父類--人工智慧
人工智慧是機器學習的父類。深度學習則是機器學習的子類。如果把三者的關係用圖來表明的話,則是下圖:

總結起來,人工智慧的發展經歷瞭如下若干階段,從早期的邏輯推理,到中期的專家系統,這些科研進步確實使我們離機器的智慧有點接近了,但還有一大段距離。直到機器學習誕生以後,人工智慧界感覺終於找對了方向。基於機器學習的影象識別和語音識別在某些垂直領域達到了跟人相媲美的程度。機器學習使人類第一次如此接近人工智慧的夢想。
讓我們再看一下機器人的製造,在我們具有了強大的計算,海量的儲存,快速的檢索,迅速的反應,優秀的邏輯推理後我們如果再配合上一個強大的智慧大腦,一個真正意義上的人工智慧也許就會誕生,這也是為什麼說在機器學習快速發展的現在,人工智慧可能不再是夢想的原因。
人工智慧的發展可能不僅取決於機器學習,更取決於前面所介紹的深度學習,深度學習技術由於深度模擬了人類大腦的構成,在視覺識別與語音識別上顯著性的突破了原有機器學習技術的界限,因此極有可能是真正實現人工智慧夢想的關鍵技術。無論是谷歌大腦還是百度大腦,都是通過海量層次的深度學習網路所構成的。也許藉助於深度學習技術,在不遠的將來,一個具有人類智慧的計算機真的有可能實現。
出處:
https://www.cnblogs.com/lizheng114/p/7439556.html
http://www.cnblogs.com/subconscious/p/4107357.html