
GPU平行計算
阿新 • • 發佈:2018-11-21
GPU平行計算包括同步模式和非同步模式:
非同步模式:
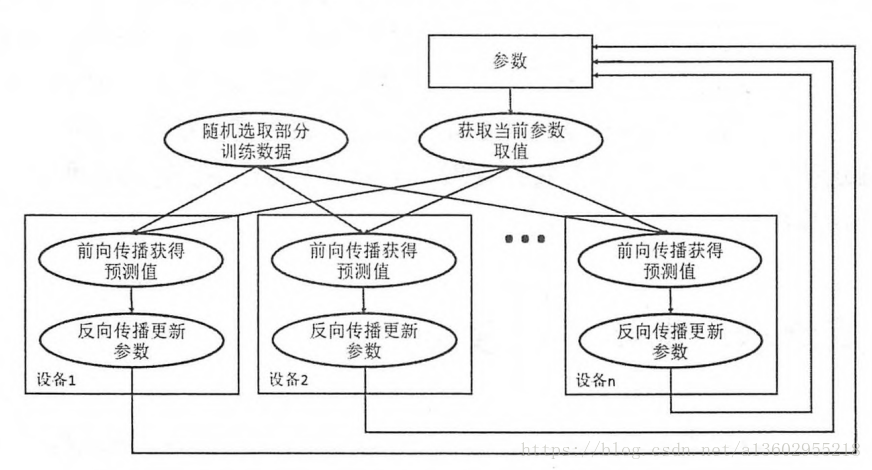
同步模式:
非同步模式的特點是速度快,不用等待其他GPU計算完畢再更新,但是更新的不確定性可能導致到達不了全域性最優。
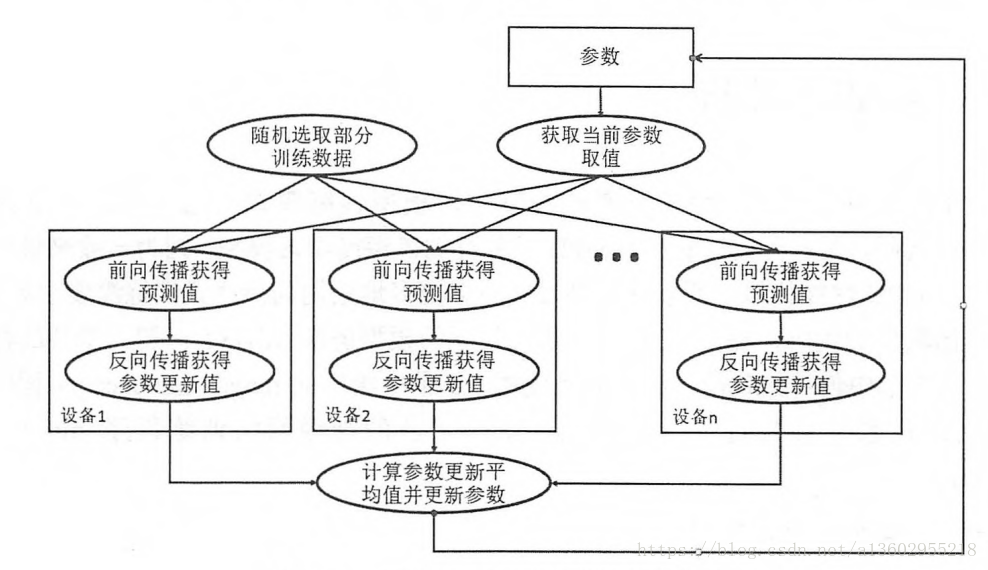
同步模式需要等到所有GPU計算完畢,並計算平均梯度,最後賦值,缺點是需要等待最後一個GPU計算完畢,時間較慢。
實踐中通常視情況使用上述兩種方式。
例項
from datetime import datetime
import os
import time
import tensorflow as tf
BATCH_SIZE = 128
LEARNING_RATE_BASE = 0.1