
課程總結 -- CPU/GPU平行計算基礎(CPU篇)
上學期選修了Prof. Tolga Soyata的“GPU Parallel Programming using C/C++”課程。該課程主要分兩部分:前半部分通過講解CPU並行程式來介紹平行計算的原理和思路;後半部分講解如何用CUDA在GPU上進行平行計算。本文紀錄其中的基礎要點和關鍵實現方式。通過本文大家可以瞭解到:1、如何用CPU進行多執行緒平行計算;2、CUDA是什麼,GPU如何進行平行計算;3、平行計算的優越性;4、記憶體的應用對程式效能的影響。
本文分兩部分:第一部分是CPU計算部分,第二部分是GPU計算部分。其中主要介紹實現的具體方法(理論也講不清楚)。內容參考課上課件和程式碼,以及教材:
0、序列程式
在接下來的幾個小節,我們會用不同的方式完成同一個任務:縱向翻轉一張3200x1600的圖片,並比較它們之間的效能差異。首先我們來看的是採用序列方法的實現,即不使用平行計算,對逐個畫素進行交換操作。為了簡化讀寫等無關操作,我們用opencv進行影象的讀寫,具體程式碼見這裡。
效能:使用序列計算,其速度為平均每張圖片約 107ms。
1、第一個CPU並行程式
分析一下這個任務,我們可以發現:每一行執行的操作是獨立且相同的。因此我們其實可以讓不同行同時執行同樣的操作,這便是並行的程式。具體來說,假設我們有
利用CPU實現上述並行程式需要用到pthread。Pthread是執行緒的POSIX標準,定義了建立和操作執行緒的一套API。以下將一些重要的核心程式碼列出,完整程式碼可見這裡。
- 引用pthread庫及宣告需要用到的變數
#include <pthread.h>
#define MAX_THREADS 64
long NumThreads; // number of threads work in parallel - pthread初始化
pthread_attr_init(&ThAttr);
pthread_attr_setdetachstate(&ThAttr, PTHREAD_CREATE_JOINABLE);- 分配執行緒和結束
for (i=0; i<NumThreads; i++) {
ThParam[i] = i;
// important!! lauch threads
ThErr = pthread_create(&ThHandle[i], &ThAttr, MFlip, (void *)&ThParam[i]);
if (ThErr != 0) {
printf("\nThread Creation Error %d.\n", ThErr);
exit(EXIT_FAILURE);
}
}
for (i=0; i<NumThreads; i++) {
// important!! join all threads
pthread_join(ThHandle[i], NULL);
}
- 根據執行緒ID決定改執行緒開始執行的列數,及該執行緒退出語句
long ts = *((int *) tid); // thread ID
ts *= rows / NumThreads; // start index
...
pthread_exit(NULL);並行程式的效能如下:
| 執行緒數 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 時間(ms) | 135.54 | 91.72 | 52.18 | 27.99 | 15.13 | 13.62 | 14.40 |
從上表可以看出:
- 執行緒數為1時,由於增加了呼叫pthread的一些開銷,程式比上一小節的會慢一些
- 逐步增加執行緒數,可以看到接近線性的加速(增加兩倍執行緒數,時間減少兩倍),從中可以看到並行程式的有效性
- 當執行緒數增加到一定程度後(上表為32),速度提升會遇到瓶頸,即不能永遠的達到線性加速。其中的原因比較複雜(其實是我沒完全聽懂。。),可能涉及記憶體的共享、系統CPU核的數量、排程等問題,在此不妄加評論了。
2、改善並行程式
在這個小節中,我們會看到合理的記憶體應用和程式執行方式會對程式效能造成多大的影響。
我們先來分析一下上一小節的並行程式。我們將資料按照執行緒數量分割成等量的小塊,並讓不同執行緒同時執行各個小部分,這種並行方式可以成為資料並行。這種並行方式的好處是每個執行緒執行的任務都是相同的,只需要標記不同的處理位置。但是這樣就足夠了嗎?並非如此。在上述程式中,我們沒有考慮過程式的記憶體訪問模式(Memory Access Pattern)。
毫無疑問,MFlip() 函式是一個記憶體密集型(memory-intensive)的函式。因為它對每個畫素並沒有進行任何計算,但是需要頻繁的對記憶體進行讀取和寫入(為了交換畫素值)。對於這一類的函式,其記憶體訪問模式會大大地影響程式的效能。
從直觀上我們便能體會到上節中程式的記憶體訪問模式有多麼糟糕。每次交換兩個畫素值,程式都要從記憶體中讀取兩個不同位置的資料,並且這兩個位置相隔非常的遠。而且每次從記憶體中讀取一個畫素的值(1位元)也是非常浪費資源的做法。再加上多執行緒同時進行不同位置的記憶體讀寫操作,會使程式的記憶體訪問變得非常低效。從理論上講,為了達到好的DRAM讀寫效能,我們需要遵守以下幾條規則(為了描述的準確性直接上原文):

對比一下我們可以發現,上節的程式違反了Granularity的規則,即每次都讀寫過於少量的資料,造成讀寫時資源的浪費。另外,上節的程式並沒有利用好快取(cache memory),因為它從來沒有進行資料的複用。
因此,我們來改進上節的程式,使其能滿足上述的幾點規則。從上表可以看到,雖然圖片資料儲存在DRAM中,我們並不希望頻繁地對它進行訪問。因此我們可以一次把一行圖片的資料讀取到一個臨時緩衝區中,再對其中的資料進行處理。這樣的好處不僅能夠減少對DRAM的訪問,還能充分利用L1快取的作用對讀取的資料進行重複利用。核心實現程式碼如下,整體程式碼在這裡。
- 準備兩個緩衝區用來存放兩行的資料
unsigned char Buffer1[16384]; // This is the buffer to get the first row of image;
unsigned char Buffer2[16384]; // This is the buffer to get the second row of image;- 讀取資料進入緩衝區
// important!! copy data to cache memory
memcpy((void *)Buffer1, TheImage.ptr<uchar>(r), cols*sizeof(unsigned char));
memcpy((void *)Buffer2, TheImage.ptr<uchar>(rows-(r+1)), cols*sizeof(unsigned char));- 交換資料(從緩衝區寫入記憶體)
memcpy((void *) TheImage.ptr<uchar>(r), (void *)Buffer2, cols*sizeof(unsigned char));
memcpy((void *) TheImage.ptr<uchar>(rows-(r+1)), (void *)Buffer1, cols*sizeof(unsigned char));效能如下:(注意,這裡的提速有點誇張,個人認為除了記憶體訪問模式的影響以為,還和之前程式中直接對opencv的矩陣物件進行操作有關)
| 執行緒數 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 時間(ms) | 1.65 | 0.95 | 0.96 | 0.85 | 0.86 | 1.42 | 2.52 |
3、同步和非同步
前面介紹的並行方式都屬於同步並行(synchronized),即程式等待所有並行的執行緒都執行完當前的任務,再執行下一步工作。這樣可能會出現的一個問題是:有些執行緒由於某些原因執行速度變慢了,則所有執行緒都會受到它的影響而滯後,因為它們需要等待所有執行緒都完成任務。換句話說,具有木桶效應。
除了同步並行以外,我們還有另一種並行方式叫作非同步並行(asynchronized)。這種並行方式可以使執行緒無需等待其它執行緒的工作情況,而直接進行其它任務。下圖可以看到它們的關係:
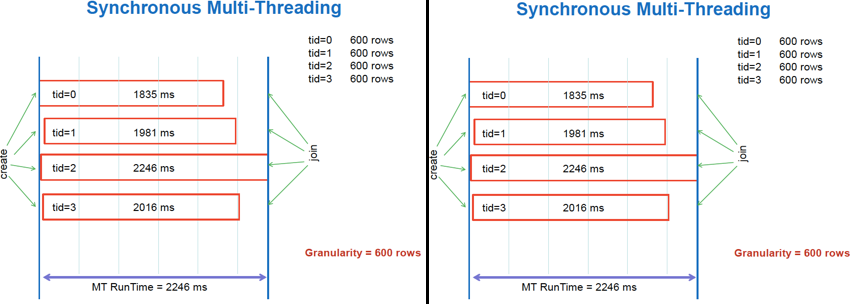
這裡我們不討論同步和非同步之間的優劣,只介紹如何實現一個非同步的並行程式。與同步並行不同,非同步並行會出現執行緒之間對資源訪問的衝突問題。解決這個問題的一種方法是使用互斥量(mutex)。簡單來說就是通過對一個共享變數的上鎖(lock)和解鎖(unlock)來保證在同一時期只有一個執行緒對共享資源進行修改,從而解決衝突的問題。下圖說明了其工作原理:

利用互斥量實現非同步並行的核心程式碼如下,完整程式碼見這裡。注意我們不再將資料等分為
- 定義和初始化mutex
pthread_mutex_t CounterMutex; // define mutex
...
// initialize mutex
pthread_mutex_init(&CounterMutex, NULL);
pthread_mutex_lock(&CounterMutex);
NextRowToProcess = 0;
for (i=0; i<NumThreads; i++) {
ThParam[i] = 0;
}
pthread_mutex_unlock(&CounterMutex);- 利用mutex互斥地讀取和修改下一行的值
// get the next row number
pthread_mutex_lock(&CounterMutex); // lock it before accessing
r = NextRowToProcess;
NextRowToProcess ++;
pthread_mutex_unlock(&CounterMutex); // unlock it after accessing
效能如下:
| 執行緒數 | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| 時間(ms) | 1.70 | 1.99 | 1.15 | 1.18 | 1.32 | 1.67 | 2.66 |
4、程式與效能(optional)
在這課程中,除了學習到平行計算的原理及實現方式外,我最大的感觸便是程式的細微改動對效能巨大的影響。這些改動涉及到記憶體的訪問、CPU計算量的減少等方面。下面這個例子中,我們用7種不同方式實現旋轉圖片的任務,其中每種實現逐步地對程式碼進行修改和優化。我們可以看見rotate7()比rotate()的效能要優越很多。由於篇幅關係就不再一一講解了,具體程式碼請看這裡。
相關推薦
課程總結 -- CPU/GPU平行計算基礎(CPU篇)
上學期選修了Prof. Tolga Soyata的“GPU Parallel Programming using C/C++”課程。該課程主要分兩部分:前半部分通過講解CPU並行程式來介紹平行計算的原理和思路;後半部分講解如何用CUDA在GPU上進行平行計算。本
CPU與GPU平行計算聯絡與區別
最近在做利用GPU實現並行渲染的工作,前天同學問我CPU和GPU在多執行緒和平行計算方面的區別具體是什麼,雖然做了幾個月這方面的工作,但我一下子答卻不知道從何答起,因此在這裡做一下整理。 一、CPU和GPU的區別 CPU((Central Processing Uni
Yeslab 華為安全HCIE七門之-防火墻基礎(12篇)
nat原理 分享課 多出口 spf 鏈接 baidu 路徑 .com 體系 Yeslab 華為安全HCIE七門之-防火墻基礎(12篇) Yeslab 全套華為安全HCIE七門之第二門防火墻基礎(12篇),第一門課論壇很早就有了,可自行下載,後面的陸續分享給大家。 華為安全H
Asp.net過濾器理論基礎(上篇)
Filter 微軟為Asp.net MVC開發的4種過濾器: 許可權校驗過濾器 Action過濾器(IActionFilter),action方法執行前和執行後會執行的過濾器,需要實現介面 IActionFilter Result(IResultFilt
最全總結 | 聊聊 Python 資料處理全家桶(Mysql 篇)
 ## 1\. 前言 在爬蟲、自動化、資料
最全總結 | 聊聊 Python 資料處理全家桶(Memcached篇)
 ## 1\. 前言 本篇文章繼續繼續另外
最全總結 | 聊聊 Python 資料處理全家桶(配置篇)
 ## 1.前言 在實際專案中,經常會接觸
學習大資料課程 spark 基於記憶體的分散式計算框架(二)RDD 程式設計基礎使用
學習大資料課程 spark 基於記憶體的分散式計算框架(二)RDD 程式設計基礎使用 1.常用的轉換 假設rdd的元素是: {1,2,2,3} 很多初學者,對大資料的概念都是模糊不清的,大資料是什麼,能做什麼,學的時候,該按照什麼線路去學習,學完
GPU平行計算
GPU平行計算包括同步模式和非同步模式: 非同步模式: 同步模式: 非同步模式的特點是速度快,不用等待其他GPU計算完畢再更新,但是更新的不確定性可能導致到達不了全域性最優。 同步模式需要等到所有GPU計算完畢,並計算平均梯度,最後賦值,缺點是需要等待最後一個GPU
【平行計算-CUDA開發】淺談GPU平行計算新趨勢
隨著GPU的可程式設計性不斷增強,GPU的應用能力已經遠遠超出了圖形渲染任務,利用GPU完成通用計算的研究逐漸活躍起來,將GPU用於圖形渲染以外領域的計算成為GPGPU(General Purpose computing on graphics proces
GPU平行計算入門1——背景知識
專有名詞: GPGPU 通用圖形處理器 (英語:General-purpose computing on graphics processing units,簡稱GPGPU或GP²U),利用處理圖形任務的圖形處理器來計算原本由中央處理器處理的通用計算任務,這些
利用GPU平行計算來加速簡單積分過程的實驗
由於CPU的摩爾定律已經不再適用,目前加速程式的最佳選擇就是通過GPU並行。經過幾天的摸索後,完成了這個利用GPU加速積分演算法的小實驗。 數值積分中最常用的方法之一就是辛普森積分法,首先我們寫出一段三階辛普森積分的小程式: double Simpson_integ (i
平行計算-CUDA開發:淺談GPU平行計算新趨勢
前幾天偶然之間與同事談論到ROM,RAM,FLASH一些知識,而突然之間當我們去說這些英文單詞的
一起做實驗 | 多GPU平行計算訓練深度神經網路
科技你好關注我們·成為科技潮人2018年2月25日,平昌東奧會閉幕式上,備受矚目的“北京八分鐘”
89、tensorflow使用GPU平行計算
''' Created on May 25, 2017 @author: p0079482 ''' # 分散式深度學習模型訓練模式 # 在一臺機器的多個GPU上並行訓練深度學習模型 from datetime import datetime import os impor
效能測試基礎——(CPU)轉
效能測試基礎——(CPU) 發表於:2017-8-01 11:12 作者:aceaoh 來源:51Testing軟體測試網採編 字型:大 中 小 | 上一篇 | 下一篇 |我要投稿 |&
PTA_基礎程式設計題目集_7-15 計算圓周率 (15 分)_C語言實現
題目地址 題目分析:此處唯一需要注意的是都用double,不然精度無法滿足。 我的程式碼: #include<stdio.h> int main() { double a; scanf("%lf", &a); double up = 1,
CPU與GPU之間資料傳輸(轉)
一般的資料複製到的顯示卡記憶體的部份,稱為 global memory int* gpudata, *result; cudaMalloc((void**) &gpudata, sizeof(int) * DATA_SIZE); cudaMallo
Matlab平行計算示例(一)
使用Matlab實現演算法較為簡單,但是涉及for迴圈時,效率比不上C++。對於一個多核處理器,不開多核平行計算,實在是對不住Matlab自帶的平行計算功能。parfor迴圈較為簡單,但是它對for迴圈中的變數要求比較嚴格,稍有不慎就會出錯(我深受其害)。使
課程總結任務四-2 雪碧圖(1)
前面的課程在學習的時候沒有總結,現在開始補充。學過之後留下點痕跡還是好的。這是任務四中必須課第二個視訊中的一個知識點雪碧圖。 本節課的主要任務有: (1)雪碧圖 (2)滑動門 (3)CSS的漸變 一、雪碧圖 http://blog.csdn.net/bingkingboy