
CPU與GPU平行計算聯絡與區別
最近在做利用GPU實現並行渲染的工作,前天同學問我CPU和GPU在多執行緒和平行計算方面的區別具體是什麼,雖然做了幾個月這方面的工作,但我一下子答卻不知道從何答起,因此在這裡做一下整理。
一、CPU和GPU的區別
CPU((Central Processing Unit, 中央處理器):CPU的結構主要包括運算器(ALU, Arithmetic and Logic Unit)、控制單元(CU, Control Unit)、暫存器(Register)、快取記憶體器(Cache)和它們之間通訊的資料、控制及狀態的匯流排。需要具備處理不同資料型別的能力,具有很強的通用性,CPU內部結構非常複雜。CPU擅長像作業系統、系統軟體和通用應用程式這類擁有複雜指令排程、迴圈、分支、邏輯判斷以及執行等的程式任務。它的並行優勢是程式執行層面的,程式邏輯的複雜度也限定了程式執行的指令並行性,上百個並行程式執行的執行緒基本看不到。
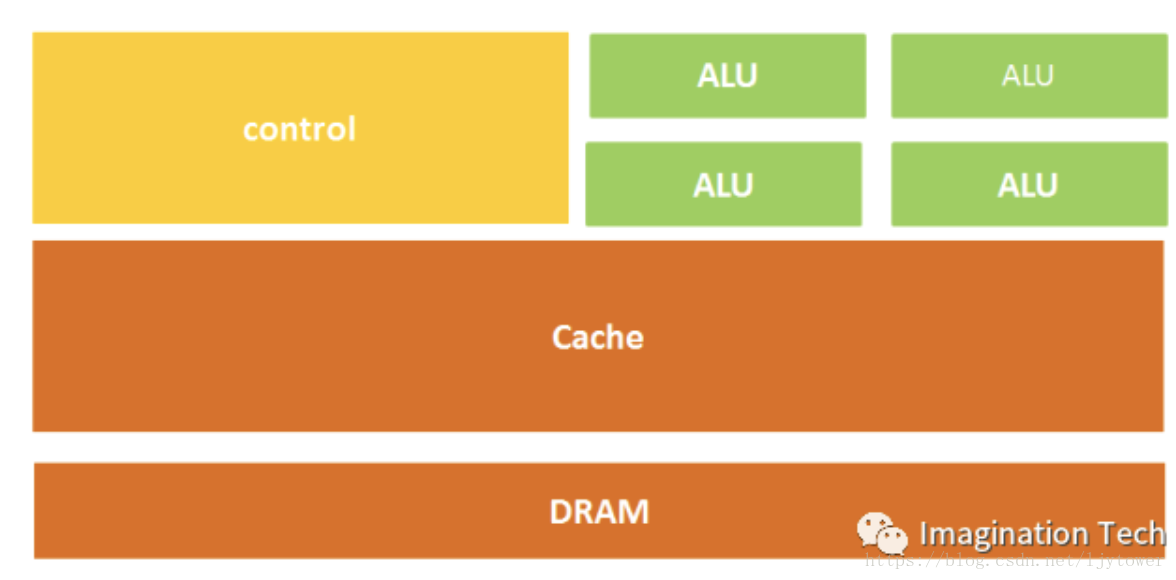

GPU(Graphics Processing Unit,圖形處理器):GPU由數量眾多的計算單元和超長的流水線組成,適合處理大量的型別統一的資料。但GPU無法單獨工作,必須由CPU進行控制呼叫才能工作。GPU以圖形類數值計算為核心。用於處理型別高度統一、相互無依賴的大規模資料和不需要被打斷的純淨的計算環境。GPU擅長的是圖形類的或者是非圖形類的高度並行數值計算,GPU可以容納上千個沒有邏輯關係的數值計算執行緒,它的優勢是無邏輯關係資料的平行計算。
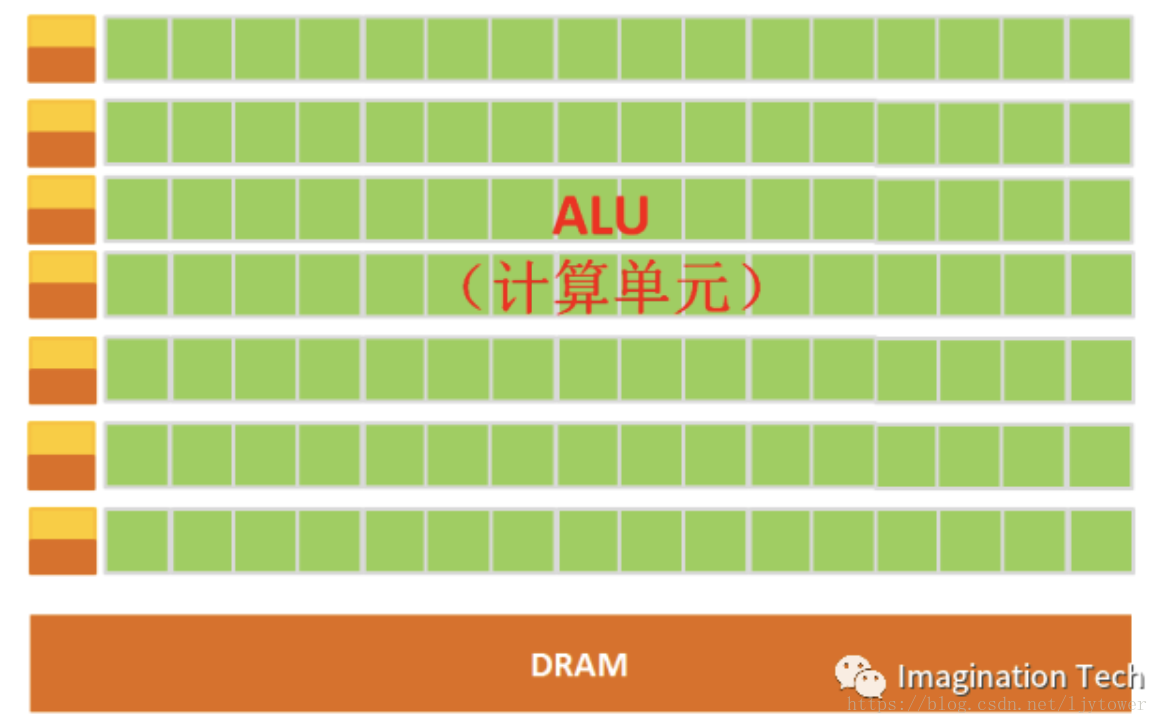
GPU中有很多的運算器ALU和很少的快取cache,快取的目的不是儲存後面需要訪問的資料的,而是為執行緒thread提高服務的。如果有很多執行緒需要訪問同一個相同的資料,快取會合並這些訪問,然後再去訪問dram。
二、多程序、多執行緒、併發、並行
1.程序(活動)
程序是一個具有獨立功能的程式關於某個資料集合的一次執行活動。多程序,就好比同時打開了Word,Excel和Visio,他們都是不同的程式執行活動,即多個程序同時啟動而已。
2.執行緒(執行路徑)
執行緒,是一個執行中的程式活動(即程序)的多個執行路徑,執行排程的單位。執行緒依託於程序存在,在程序之下,可以共享程序的記憶體,而且還擁有一個屬於自己的記憶體空間,這段記憶體空間也叫做執行緒棧。多執行緒,指在一個程序下有多個執行緒。各個執行緒執行自己的任務,這些執行緒可以“同時進行”。多執行緒強調”同時,一起進行“,而不是單一的順序操作。
3.併發
併發的實質是一個物理CPU(也可以多個物理CPU) 在若干道程式(或執行緒)之間多路複用,併發性是對有限物理資源強制行使多使用者共享以提高效率。也就是說對於一個CPU資源,執行緒之間競爭得到執行機會。
4.並行
指兩個或兩個以上事件(或執行緒)在同一時刻發生,是真正意義上的不同事件或執行緒在同一時刻,在不同CPU資源上(多核),同時執行。
這裡引用知乎網友@pansz的比喻:
單程序單執行緒:一個人在一個桌子上吃菜。
單程序多執行緒:多個人在同一個桌子上一起吃菜。
多程序單執行緒:多個人每個人在自己的桌子上吃菜
三、CPU與GPU的平行計算
平行計算一般有兩個維度,一個是指令(Instruction)或程式(Program),另一個是資料(Data)。這樣,就可以歸納出各種並行模式(S代表Single,M代表Multiple)。

除了SISD,其他幾個都算是平行計算方法。
資料的儲存可以分為兩大類:分散式儲存和共享記憶體。分散式儲存意味著不同的程序/指令處理不同的資料,大家互相不干擾。共享記憶體則要求不同的程序/指令可以同時修改同一塊資料,程序之間的通訊將變得簡單,缺點是容易造成資料讀寫衝突而需要謹慎對待。
1.CPU平行計算
CPU 採用複雜的分支預測技術來達到平行計算目的。對於CPU平行計算,快取對程式設計師透明。應用程式設計師無法通過程式設計手段操縱快取。採用 MIMD - 多指令多資料型別。多條指令構成指令流水線,且每個執行緒都有獨立的硬體來操縱整個指令流。
2.GPU平行計算
GPU最大的特點是它擁有超多計算核心,往往成千上萬核。而每個核心都可以模擬一個CPU的計算功能,雖然單個GPU核心的計算能力一般低於CPU。對於GPU平行計算,快取對程式設計師不透明,程式設計師可根據實際情況操縱大部分快取。採用 SIMT - 單指令多執行緒模型,一條指令配備一組硬體,對應32個執行緒 (一個執行緒束)。GPU 內部有很多流多處理器。每個流多處理器都相當於一個“核",而且一個流多處理器每次處理 32 個執行緒。
CUDA,全稱是Compute Unified Device Architecture,即統一計算架構,是由生產GPU最有名的英偉達公司提出的CPU+GPU混合程式設計框架。CUDA C/C++語言有如下特點:也是SPMD框架,兼有分散式儲存和共享記憶體的優點,把握GPU的頻寬是充分利用GPU計算資源的關鍵。
一般,經過一定優化的CUDA C/C++程式的計算速度相比於傳統的CPU程式的計算速度要快幾倍到幾十倍。