DataFrame.groupby()函式
阿新 • • 發佈:2018-11-21
- 用二維列表構造原始資料
1 import pandas as pd
2
3 data = [['li', 'math', 100], ['bob', 'pe', 99], ['sar', 'english', 98], ['li', 'pe', 89]]
- 將資料轉換成DataFrame型別
1 import pandas as pd
2
3 dataFrame = pd.DataFrame(dada, columns = ['name', 'course', 'score']) # columns 為列名
- 列印dataFrame物件
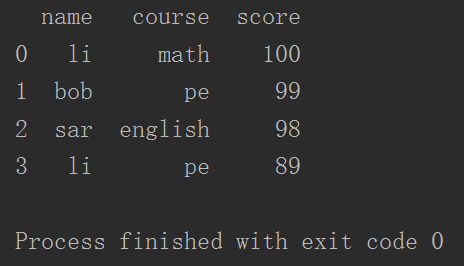
- 此時不能根據行號索引,但是可以根據列名索引
1 import pandas as pd
2
3 print(dataFrame[0])

1 import pandas as pd
2
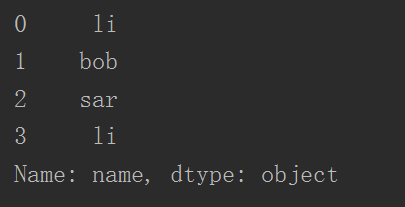
3 print(dataFrame["name"])
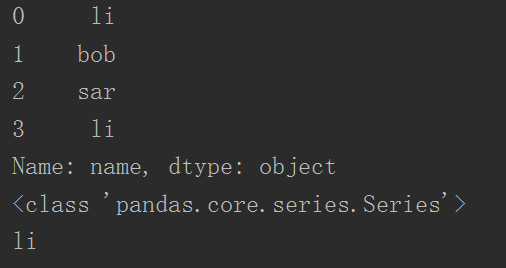
- 此時的dataFrame["name"] 是一個類似於一位陣列的series物件,可根據下標索引
1 import pandas as pd 2 3 print(dataFrame["name"])
4 print(type(dataFrame["name"]))
5 print(dataFrame["
- 像字典一樣用索引建立新列 dataFrame["age"]
1 import pandas as pd
2
3 dataFrame["age"] = [23, 24, 25, 23]
4 print(dataFrame)
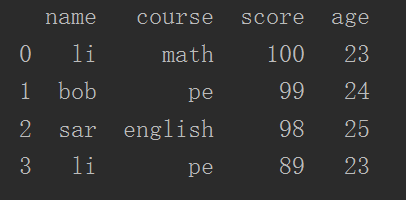
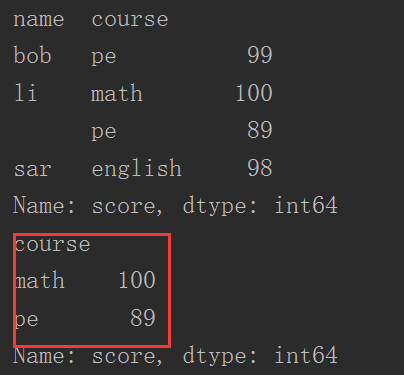
- 重點來了,dataFrame.groupby("name")根據name屬性分組,name列資料項預設成為索引
1 import pandas as pd
2
3 dataFrame = dataFrame.groupby(["name", "course"])["score
5 print(dataFrame["li"])