
Python:爬蟲例項2:爬取貓眼電影——破解字型反爬
字型反爬
字型反爬也就是自定義字型反爬,通過呼叫自定義的字型檔案來渲染網頁中的文字,而網頁中的文字不再是文字,而是相應的字型編碼,通過複製或者簡單的採集是無法採集到編碼後的文字內容的。
現在貌似不少網站都有采用這種反爬機制,我們通過貓眼的實際情況來解釋一下。
下圖的是貓眼網頁上的顯示:
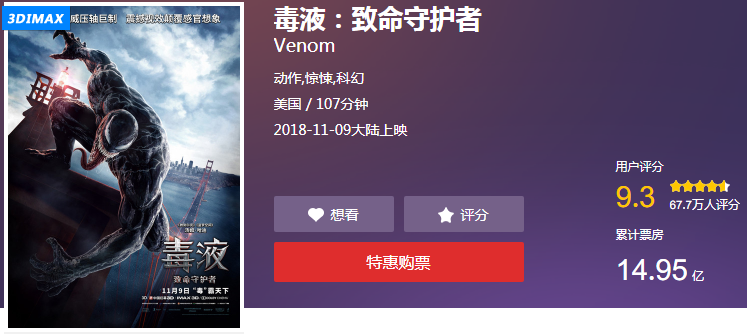
檢查元素看一下
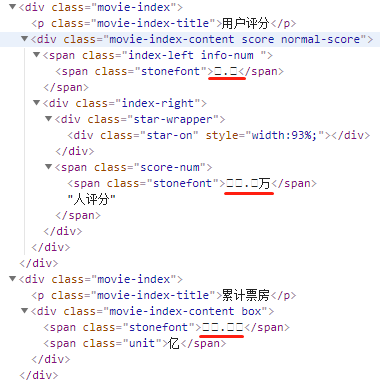
這是什麼鬼,關鍵資訊全是亂碼。
熟悉 CSS 的同學會知道,CSS 中有一個 @font-face,它允許網頁開發者為其網頁指定線上字型。原本是用來消除對使用者電腦字型的依賴,現在有了新作用——反爬。
漢字光常用字就有好幾千,如果全部放到自定義的字型中,那麼字型檔案就會變得很大,必然影響網頁的載入速度,因此一般網站會選取關鍵內容加以保護,如上圖,知道了等於不知道。
這裡的亂碼是由於 unicode 編碼導致的,檢視原始檔可以看到具體的編碼資訊。
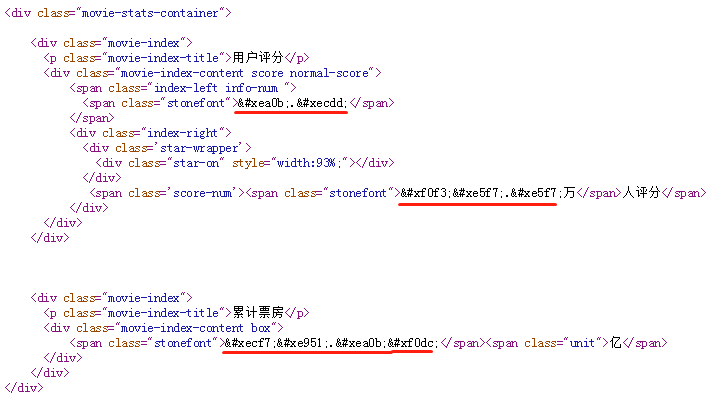
搜尋 stonefont,找到 @font-face 的定義:

這裡的 .woff 檔案就是字型檔案,我們將其下載下來,利用 http://fontstore.baidu.com/static/editor/index.html 網頁將其開啟,顯示如下:

網頁原始碼中顯示的  跟這裡顯示的是不是有點像?事實上確實如此,去掉開頭的 &#x 和結尾的 ; 後,剩餘的4個16進位制顯示的數字加上 uni 就是字型檔案中的編碼。所以  對應的就是數字“9”。
知道了原理,我們來看下如何實現。
處理字型檔案,我們需要用到 FontTools 庫。
先將字型檔案轉換為 xml 檔案看下:
from fontTools.ttLib import TTFont
font = TTFont('bb70be69aaed960fa6ec3549342b87d82084.woff')
font.saveXML('bb70be69aaed960fa6ec3549342b87d82084.xml')
開啟 xml 檔案
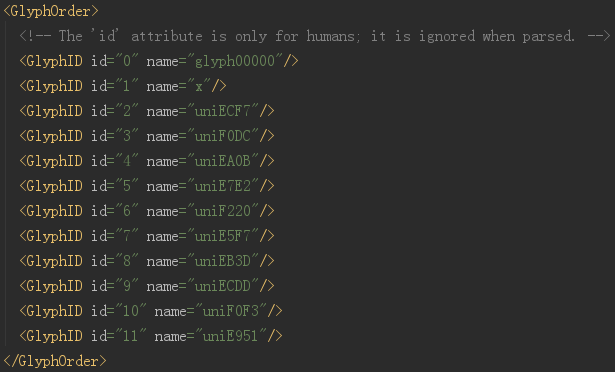
開頭顯示的就是全部的編碼,這裡的 id 僅僅是編號而已,千萬別當成是對應的真實值。實際上,整個字型檔案中,沒有任何地方是說明 EA0B 對應的真實值是啥的。
看到下面
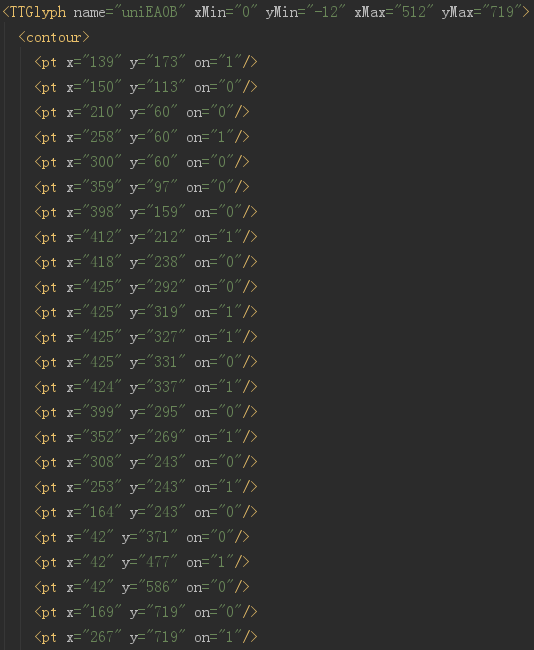
這裡就是每個字對應的字型資訊,計算機顯示的時候,根本不需要知道這個字是啥,只需要知道哪個畫素是黑的,哪個畫素是白的就可以了。
貓眼的字型檔案是動態載入的,每次重新整理都會變,雖然字型中定義的只有 0-9 這9個數字,但是編碼和順序都是會變的。就是說,這個字型檔案中“EA0B”代表“9”,在別的檔案中就不是了。
但是,有一樣是不變的,就是這個字的形狀,也就是上圖中定義的這些點。
我們先隨便下載一個字型檔案,命名為 base.woff,然後利用 fontstore 網站檢視編碼和實際值的對應關係,手工做成字典並儲存下來。爬蟲爬取的時候,下載字型檔案,根據網頁原始碼中的編碼,在字型檔案中找到“字形”,再迴圈跟 base.woff 檔案中的“字形”做比較,“字形”一樣那就說明是同一個字了。在 base.woff 中找到“字形”後,獲取“字形”的編碼,而之前我們已經手工做好了編碼跟值的對映表,由此就可以得到我們實際想要的值了。
這裡的前提是每個字型檔案中所定義的“字形”都是一樣的(貓眼目前是這樣的,以後也許還會更改策略),如果更復雜一點,每個字型中的“字形”都加一點點的隨機形變,那這個方法就沒有用了,只能祭出殺手鐗“OCR”了。
下面是完整的程式碼,抓取的是貓眼2018年電影的第一頁,由於主要是演示破解字型反爬,所以沒有抓取全部的資料。
程式碼中使用的 base.woff 檔案跟上面截圖顯示的不是同一個,所以會看到編碼跟值跟上面是對不上的。
import os
import time
import re
import requests
from fontTools.ttLib import TTFont
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
host = 'http://maoyan.com'
def main():
url = 'http://maoyan.com/films?yearId=13&offset=0'
get_moviescore(url)
os.makedirs('font', exist_ok=True)
regex_woff = re.compile("(?<=url\(').*\.woff(?='\))")
regex_text = re.compile('(?<=<span class="stonefont">).*?(?=</span>)')
regex_font = re.compile('(?<=&#x).{4}(?=;)')
basefont = TTFont('base.woff')
fontdict = {'uniF30D': '0', 'uniE6A2': '8', 'uniEA94': '9', 'uniE9B1': '2', 'uniF620': '6',
'uniEA56': '3', 'uniEF24': '1', 'uniF53E': '4', 'uniF170': '5', 'uniEE37': '7'}
def get_moviescore(url):
# headers = {"User-Agent": UserAgent(verify_ssl=False).random}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36'}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
ddlist = soup.find_all('dd')
for dd in ddlist:
a = dd.find('a')
if a is not None:
link = host + a['href']
time.sleep(5)
dhtml = requests.get(link, headers=headers).text
msg = {}
dsoup = BeautifulSoup(dhtml, 'lxml')
msg['name'] = dsoup.find(class_='name').text
ell = dsoup.find_all('li', {'class': 'ellipsis'})
msg['type'] = ell[0].text
msg['country'] = ell[1].text.split('/')[0].strip()
msg['length'] = ell[1].text.split('/')[1].strip()
msg['release-time'] = ell[2].text[:10]
# 下載字型檔案
woff = regex_woff.search(dhtml).group()
wofflink = 'http:' + woff
localname = 'font\\' + os.path.basename(wofflink)
if not os.path.exists(localname):
downloads(wofflink, localname)
font = TTFont(localname)
# 其中含有 unicode 字元,BeautifulSoup 無法正常顯示,只能用原始文字通過正則獲取
ms = regex_text.findall(dhtml)
if len(ms) < 3:
msg['score'] = '0'
msg['score-num'] = '0'
msg['box-office'] = '0'
else:
msg['score'] = get_fontnumber(font, ms[0])
msg['score-num'] = get_fontnumber(font, ms[1])
msg['box-office'] = get_fontnumber(font, ms[2]) + dsoup.find('span', class_='unit').text
print(msg)
def get_fontnumber(newfont, text):
ms = regex_font.findall(text)
for m in ms:
text = text.replace(f'&#x{m};', get_num(newfont, f'uni{m.upper()}'))
return text
def get_num(newfont, name):
uni = newfont['glyf'][name]
for k, v in fontdict.items():
if uni == basefont['glyf'][k]:
return v
def downloads(url, localfn):
with open(localfn, 'wb+') as sw:
sw.write(requests.get(url).content)
if __name__ == '__main__':
main()