
AI應用開發基礎傻瓜書系列3-損失函式
全套教程請點選:微軟 AI 開發教程
第三篇:啟用函式和損失函式(二)
在這一章,我們將簡要介紹一下損失函式~
損失函式
作用
在有監督的學習中,需要衡量神經網路輸出和所預期的輸出之間的差異大小。這種誤差函式需要能夠反映出當前網路輸出和實際結果之間一種量化之後的不一致程度,也就是說函式值越大,反映出模型預測的結果越不準確。
還是拿練槍的Bob做例子,Bob預期的目標是全部命中靶子的中心,但他現在的命中情況是這個樣子的:
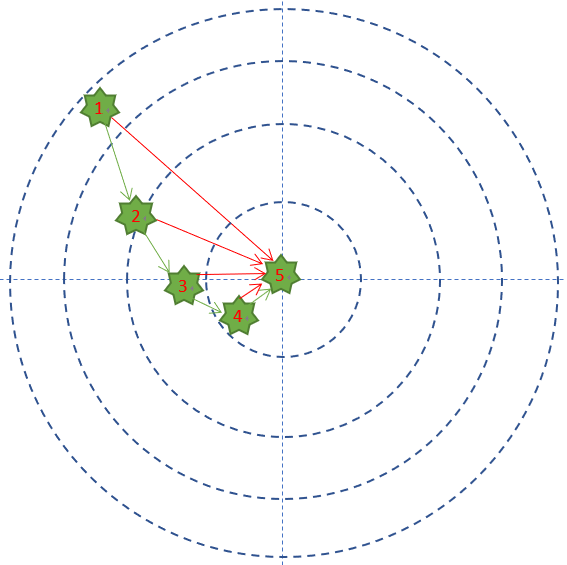
最外圈是1分,之後越向靶子中心分數是2,3,4分,正中靶心可以得5分。
那Bob每次射擊結果和目標之間的差距是多少呢?在這個例子裡面,用得分來衡量的話,就是說Bob得到的反饋結果從差4分,到差3分,到差2分,到差1分,到差0分,這就是用一種量化的結果來表示Bob的射擊結果和目標之間差距的方式。也就是誤差函式的作用。因為是一次只有一個樣本,所以這裡採用的是誤差函式的稱呼。如果一次有多個樣本,那麼就要稱呼這樣子衡量不一致程度的函式就要叫做損失函數了。
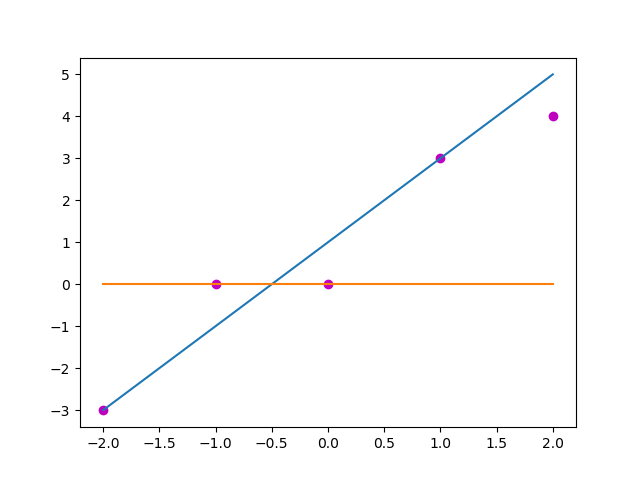
以做線性迴歸的實際值和預測值為例,若自變數x是[-2, -1, 0, 1, 2]這樣5個值,對應的期望值y是[-3, 0, 0, 3, 4]這樣的值,目前預測使用的引數是(w, b) = (2, 1), 那麼預測得到的值y_ = [-3, -1, 1, 3, 5], 採用均方誤差計算這個預測和實際的損失就是\(\sum_{i = 0}^{4}(y[i] - y_\_[i])^{2}\), 也就是3。那麼如果採用的參量是(0, 0),預測出來的值是[0, 0, 0, 0, 0],這是一個顯然錯誤的預測結果,此時的損失大小就是34,\(3 < 34\), 那麼(2, 1)是一組比(0, 0)要合適的參量。
那麼常用的損失函式有哪些呢?
這裡先給一些前提,比如神經網路中的一個神經元:
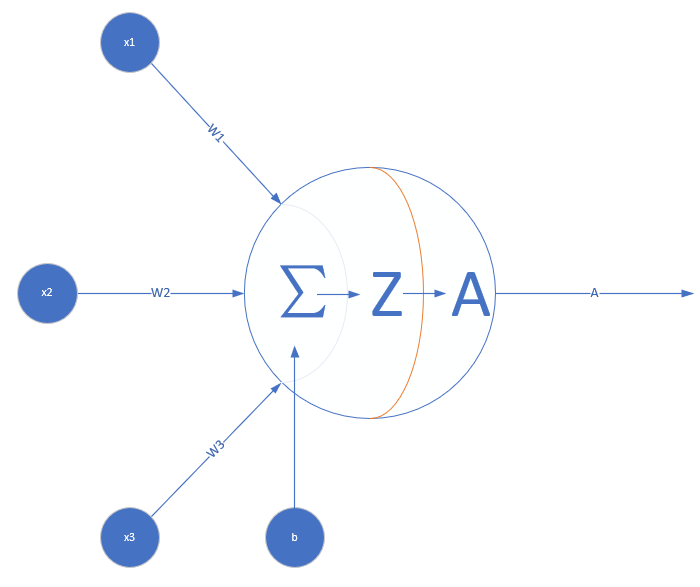
圖中 \(z = \sum\limits_{i}w_i*x_i+b_i=\theta^Tx\),\(\sigma(z)\)是對應的啟用函式,也就是說,在反向傳播時梯度的鏈式法則中,
\[\frac{\partial{z}}{\partial{w_i}}=x_i \tag{1}\]
\[\frac{\partial{z}}{\partial{b_i}}=1 \tag{2}\]
\[\frac{\partial{loss}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}x_i \tag{3}\]
\[\frac{\partial{loss}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} \tag{4}\]
從公式\((3),(4)\)可以看出,梯度計算中的公共項是\(\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} = \frac{\partial{loss}}{\partial{z}}\)。
下面我們來探討\(\frac{\partial{loss}}{\partial{z}}\)的影響。由於梯度的計算和函式的形式是有關係的,所以我們會從常用損失函式入手來逐個說明。
常用損失函式
- MSE (均方誤差函式)
該函式就是最直觀的一個損失函數了,計算預測值和真實值之間的歐式距離。預測值和真實值越接近,兩者的均方差就越小。
- 想法來源
在給定一些點去擬合直線的時候(比如上面的例子),常採用最小二乘法,使各個訓練點到擬合直線的距離儘量小。這樣的距離最小在損失函式中的表現就是預測值和真實值的均方差的和。 函式形式:
\[loss = \frac{1}{2}\sum_{i}(y[i] - a[i]) ^ 2\],
其中, \(a\)是網路預測所得到的結果,\(y\)代表期望得到的結果,也就是資料的標籤,\(i\)是樣本的序號。反向傳播:
\[\frac{\partial{loss}}{\partial{z}} = \sum_{i}(y[i] - a[i])*\frac{\partial{a[i]}}{\partial{z}}\]缺點:
和\(\frac{\partial{a[i]}}{\partial{z}}\)關係密切,可能會產生收斂速度緩慢的現象,以下圖為例(啟用函式為sigmoid)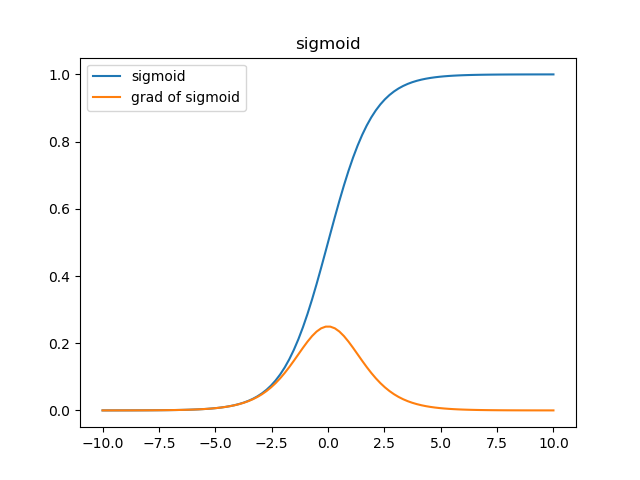
在啟用函式的兩端,梯度(黃色)都會趨向於0,採取MSE的方法衡量損失,在\(a\)趨向於1而\(y\)是0的情況下,損失loss是1,而梯度會趨近於0,在誤差很大時收斂速度也會非常慢。
在這裡我們可以參考activation中關於sigmoid函式求導的例子,假定x保持不變,只有一個輸入的一個神經元,權重\(w = ln(9)\), 偏置\(b = 0\),也就是這樣一個神經元:
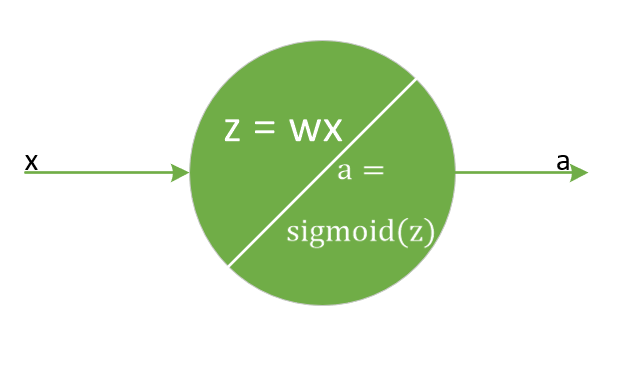
保持引數統一不變,也就是學習率\(\eta = 0.2\),目標輸出\(y = 0.5\), 此處輸入x固定不變為\(x = 1\),採用MSE作為損失函式計算,一樣先做公式推導,
第一步,計算當前誤差
\[loss = \frac{1}{2}(a - y)^2 = \frac{1}{2}(0.9 - 0.5)^2 = 0.08\]
第二步,求出當前梯度
\[grad = (a - y) \times \frac{\partial{a}}{\partial{z}} \frac{\partial{z}}{\partial{w}} = (a - y) \times a \times (1 - a) \times x = (0.9 - 0.5) \times 0.9 \times (1-0.9) \times 1= 0.036\]
第三步,根據梯度更新當前輸入值
\[w = w - \eta \times grad = ln(9) - 0.2 \times 0.036 = 2.161\]
第四步,計算當前誤差是否小於閾值(此處設為0.001)
\[a = \frac{1}{1 + e^{-wx}} = 0.8967\]
\[loss = \frac{1}{2}(a - y)^2 = 0.07868\]第五步,重複步驟2-4直到誤差小於閾值
作出函式影象如圖所示:
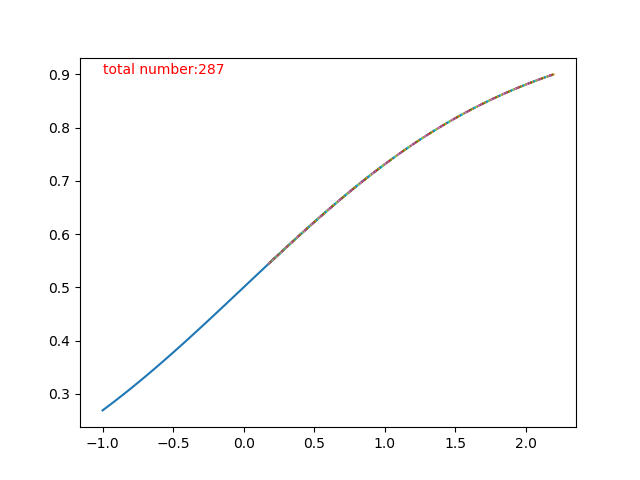
可以看到函式迭代了287次從才收斂到接近0.5的程度,這比單獨使用sigmoid函式還要慢了很多。
- 交叉熵函式
這個損失函式的目的是使得預測得到的概率分佈和真實的概率分佈儘量的接近。兩個分佈越接近,那麼這個損失函式得到的函式值就越小。怎麼去衡量兩個分佈的接近程度呢?這就要用到夏農資訊理論中的內容了。兩個概率分佈之間的距離,也叫做KL Divergence,他的定義是這個形式的,給定離散概率分佈P(x), Q(x),這兩個分佈之間的距離是
\[ D_{KL}(P || Q) = - \sum_{i}P(i)log(\frac{Q(i)}{P(i)})\]
試想如果兩個分佈完全相同,那麼\(log(\frac{Q(i)}{P(i)}) = 0\), 也就是兩個分佈之間的距離是零,如果兩個分佈差異很大,比如一個是\(P(0)=0.9, P(1)=0.1\),另一個是\(Q(0)=0.1,Q(1)=0.9\),那麼這兩個分佈之間的距離就是0.763,如果是\(Q(0)=0.5,Q(1)=0.5\),那麼距離就是0.160,直覺上來說兩個分佈越接近那麼他們之間的距離就是越小的,具體的理論證明參看《資訊理論基礎》,不過為什麼要選用這個作為損失函式呢?
從最大似然角度開始說
關於最大似然,請參看:https://www.zhihu.com/question/20447622/answer/161722019
將神經網路的引數作為\(\theta\),資料的真實分佈是\(P_{data}(y;x)\), 輸入資料為\(x\),那麼在\(\theta\)固定情況下,神經網路輸出\(y\)的概率就是\(P(y;x, \theta)\),構建似然函式,
\[L = \sum_{i}log(P(y_i;x_i, \theta))\],
以\(\theta\)為引數最大化該似然函式,即\(\theta^{*} = {argmax}_{\theta}L\)。
真實分佈\(P(x_i)\)對於每一個\((i, x_i, y_i)\)來說均是定值,在確定\(x_i\)情況下,輸出是\(y_i\)的概率是確定的。在一般的情況下,對於每一個確定的輸入,輸出某個類別的概率是0或者1,所以可以將真實概率新增到上述式子中而不改變式子本身的意義:\[\theta^{*} = {argmax}_{\theta}\sum_{i}P_{data}(y_i;x_i)log(P(y_i;x_i, \theta))\]
將\(D_{KL}\)展開,得到,
\[D_{KL}(P || Q) = - \sum_{i}P(i)log(\frac{Q(i)}{P(i)}) = \sum_{i}P(i)log(P(i)) - \sum_{i}P(i)log(Q(i)) \]
\(P(i)\)代表\(P_{data}(y_i;x_i)\), \(Q(i)\)代表\(P(y_i;x_i,\theta)\)。
上述右側式中第一項是和僅真實分佈\(P(i)\)有關的,在最小化\(D_{KL}\)過程中是一個定值,所以最小化\(D_{KL}\)等價於最小化\(-\sum_{i}P(i)log(Q(i))\),也就是在最大化似然函式。函式形式(以二分類任務為例)
\[loss = \sum_{i}y(x_i)log(a(x_i)) + (1 - y(x_i))log(1 - a(x_i))\]
其中,\(y(x_i)\)是真實分佈,\(a(x_i)\)是神經網路輸出的概率分佈反向傳播
\[\frac{\partial{loss}}{\partial{z}} = (-\frac{y(z)}{a(z)} + \frac{1 - y(z)}{1 - a(z)})*\frac{\partial{a(z)}}{\partial{z}} = \frac{a(z) - y(z)}{a(z)(1-y(z))}*\frac{\partial{a(z)}}{\partial{z}}\]
在使用sigmoid作為啟用函式情況下,\(\frac{\partial{a(z)}}{\partial{z}} = a(z)(1-a(z))\),也就是說,sigmoid本身的梯度和分母相互抵消,得到,
\[\frac{\partial{loss}}{\partial{z}} = \frac{a(z) - y(z)}{y(z)(1-a(z))}*\frac{\partial{a(z)}}{\partial{z}} = a(z) - y(z)\]
在上述反向傳播公式中不再涉及到sigmoid本身的梯度,故不會受到在誤差很大時候函式飽和導致的梯度消失的影響。
總的說來,在使用sigmoid作為啟用函式時,使用交叉熵計算損失往往比使用均方誤差的結果要好上一些。但是,這個也並不是絕對的,需要具體問題具體分析,針對具體應用,有時需要自行設計損失函式來達成目標。
參考資料:
https://www.cnblogs.com/alexanderkun/p/8098781.html
本系列部落格連結:
- 神經網路的基本工作原理
- 神經網路中反向傳播與梯度下降的基本概念
- 損失函式
- 啟用函式
- 線性迴歸來理解神經網路訓練過程
- 徒手搭建神經網路
- 徒手搭建CNN網路
- 徒手搭建RNN網路
- 模型內部
- 附錄:基本數學導數公式