
AI應用開發基礎傻瓜書系列3-啟用函式和損失函式
第三篇:啟用函式和損失函式
在這一章,我們將簡要介紹一下啟用函式和損失函式~
啟用函式
看神經網路中的一個神經元,為了簡化,假設該神經元接受三個輸入,分別為\(x_1, x_2, x_3\),那麼\(z=\sum\limits_{i}w_ix_i+b_i\),
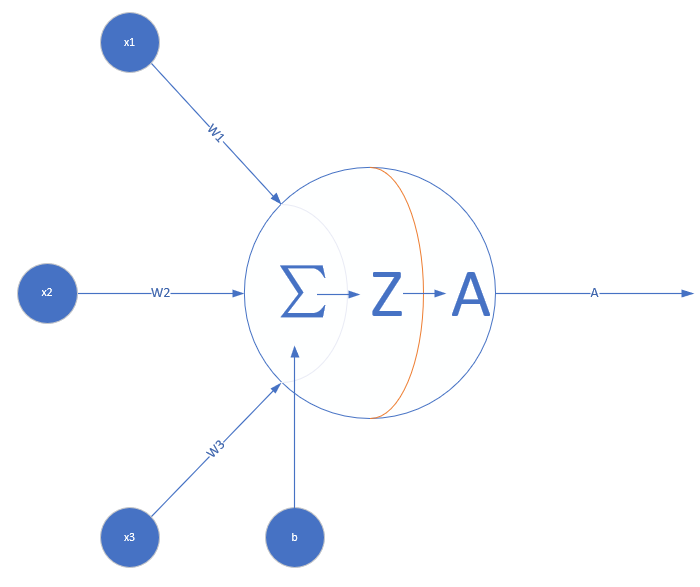
啟用函式也就是\(A=\sigma(Z)\)這一步了,他有什麼作用呢?
- 從模仿人類大腦的角度來說:
神經元在利用突觸傳遞資訊時,不是所有資訊都可以傳遞下去的,每個神經元有自己的閾值,必須要刺激強過某個閾值才會繼續向後傳遞。啟用函式在某些方面就可以扮演這樣一個啟用閾值的作用,不達到一定要求的訊號是不可以繼續向後傳遞的
- 說得形象一點,
假設老張家有一個在滴(漏)水的水龍頭:水龍頭漏水這件事情的嚴重等級有0~9這樣10個的等級,憑藉自己的力量可以解決0~2這樣3的等級的情況,維修部門可以解決3~6這樣的等級,然後譬如需要修改水管線路什麼的就是需要更加專業的部門了,他們可以解決7~9這樣等級的情況。發現一個等級為5的漏水事件,處理步驟是什麼樣的呢?
首先,看到水龍頭在滴水,通過視覺細胞處理成訊號輸入大腦,經過大腦這個黑盒子複雜的處理,判斷出這不是簡簡單單擰緊或者拍拍就能解決的漏水的問題,也就是說,判斷出這個事情的嚴重等級大於2,執行這樣一個處理函式:
if 嚴重等級 > 2: 老張打電話給隔壁老王尋求幫助 else: 自己解決
這件事情的嚴重等級超過了自己能力的閾值,所以需要開始傳遞給隔壁老王,之後老王執行一個類似的判斷
if 嚴重等級 > 6: 尋求物業公司幫助 else: 老王拿著管鉗去老張家幫忙
類似這個例子中的判斷需不需要更專業的人來解決問題,如果嚴重等級超過了某個設定的閾值,那就需要尋找更專業的人來幫助。在這裡的閾值就是能解決的嚴重等級的上限。
啟用函式在神經網路中起到的就是在控制自己接收到的訊息到底是不是需要向後傳播的作用。
- 從數學的角度來說
形如\(z=\sum\limits_{i}w_ix_i+b_i\)的傳遞是一種線性的傳遞過程。如果沒有非線性函式新增非線性,直接把很多層疊加在一起會怎麼樣呢?
以兩層為例:
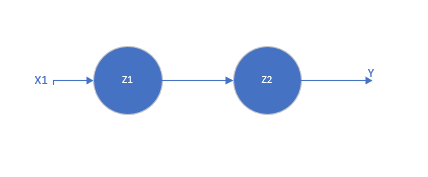
\[z_1 = w_1x_1 + b_1 \tag{1}\]
\[z_2 = w_2z_1 + b_2 = w_2(w_1x_1 + b_1) + b_2 = (w_2 w_1) x_1 + (w_2b_1 + b_2)=w_{3}x_1+b_{3} \tag{2}\]
\(z_1, z_2\)即為這兩個神經元結點的輸出。可以看到,疊加後的\(z_2\)的輸出也是一個線性函式。
以此類推,如果缺少非線性層,無論如何疊加,最後得到的還只是一個線性函式。
然而,按照生活經驗來說,大多數的事情都不是線性規律變化的,比如身高隨著年齡的變化,價格隨著市場的變化。所以需要給這樣一個線性傳遞過程新增非線性才可以更好的去模擬這樣一個真實的世界。具體該怎麼做呢?
習慣上,用‘1’來代表一個神經元被啟用,‘0’代表一個神經元未被啟用,那預期的函式影象是這個樣子的:
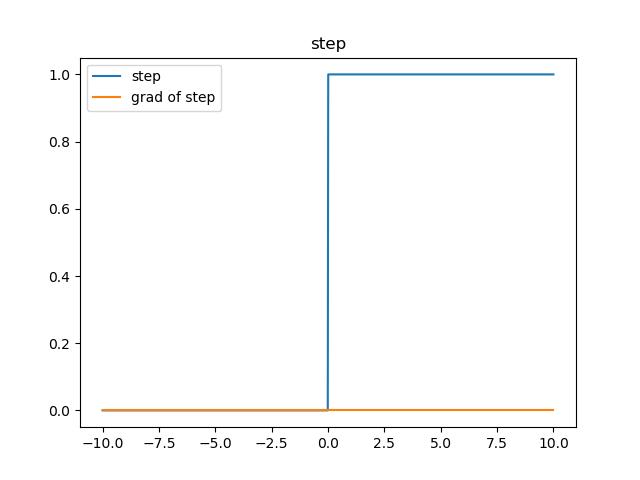
這個函式有什麼不好的地方呢?主要的一點就是,他的梯度(導數)恆為零(個別點除外)。
想想我們說過的反向傳播公式?梯度傳遞用到了鏈式法則,如果在這樣一個連乘的式子其中有一項是零,結果會怎麼樣呢?這樣的梯度就會恆為零。這個樣子的函式是沒有辦法進行反向傳播的。
那有沒有什麼函式可以近似實現這樣子的階梯效果而且還可以反向傳播呢?常用的啟用函式有哪些呢?
sigmoid函式
公式:\(f(z) = \frac{1}{1 + e^{-z}}\)
反向傳播: \(f^{'}(z) = f(z) * (1 - f(z))\),推導過程請參看數學導數公式。
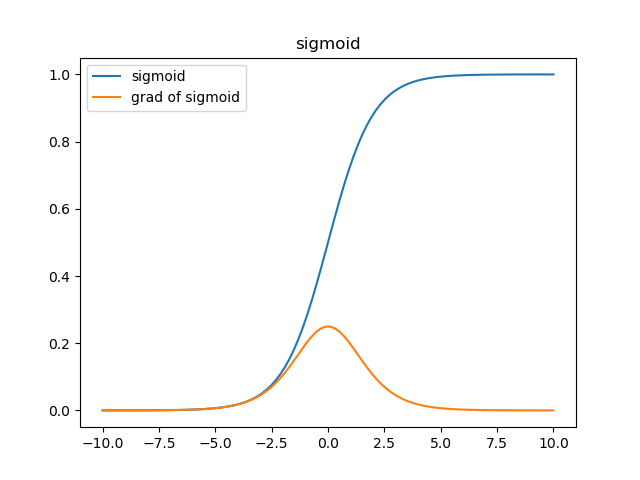
從函式影象來看,sigmoid函式的作用是將輸入限制到(0, 1)這個區間範圍內,這種輸出在0~1之間的函式可以用來模擬一些概率分佈的情況。他還是一個連續函式,導數簡單易求。
用mnist資料的例子來通俗的解釋一下:
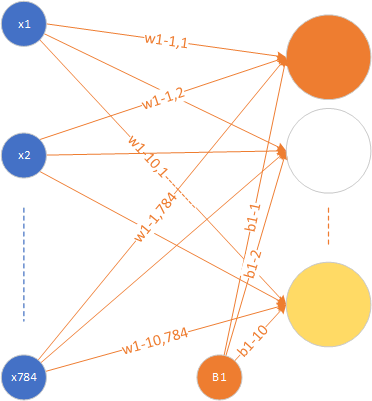
形象化的說,每一個隱藏層神經元代表了對某個筆畫的感知,也就是說可能第一個神經元代表是否從圖中檢測到有一條像1一樣的豎線存在,第二個神經元代表是否有一小段曲線的存在。但是在實際傳播中,怎麼表示是不是有這樣一條直線或者這樣一段曲線存在呢?在生活中,我們經常聽到這樣的對白“你覺得這件事情成功概率有多大?”“我有六成把握能成功”。sigmoid函式在這裡就起到了如何把一個數值轉化成一個通俗意義上的把握的表示。值越大,那麼這個神經元對於這張圖裡有這樣一條線段的把握就越大,經過sigmoid函式之後的結果就越接近100%,也就是1這樣一個值,表現在圖裡,也就是這個神經元越興奮(亮)。
但是這個樣子的啟用函式有什麼問題呢?
從梯度影象中可以看到,sigmoid的梯度在兩端都會接近於0,根據鏈式法則,把其他項作為\(\alpha\),那麼梯度傳遞函式是\(\alpha*\sigma'(x)\),而\(\sigma'(x)\)這時是零,也就是說整體的梯度是零。這也就很容易出現梯度消失的問題,並且這個問題可能導致網路收斂速度比較慢,比如採取MSE作為損失函式演算法時。
給個純粹數學的例子吧,假定我們的學習速率是0.2,sigmoid函式值是0.9,如果我們想把這個函式的值降到0.5,需要經過多少步呢?
我們先來做公式推導,
第一步,求出當前輸入的值
\[\frac{1}{1 + e^{-x}} = 0.9\]
\[e^{-x} = \frac{1}{9}\]
\[x = ln{9}\]
第二步,求出當前梯度
\[grad = f(x)\times(1 - f(x)) = 0.9 \times 0.1= 0.09\]
第三步,根據梯度更新當前輸入值
\[x_{new} = x - \eta \times grad = ln{9} - 0.2 \times 0.09 = ln(9) - 0.018\]
第四步,判斷當前函式值是否接近0.5
\[\frac{1}{1 + e^{-x_{new}}} = 0.898368\]
第五步,重複步驟2-3直到當前函式值接近0.5
說得如果不夠直觀,那我們來看看圖,
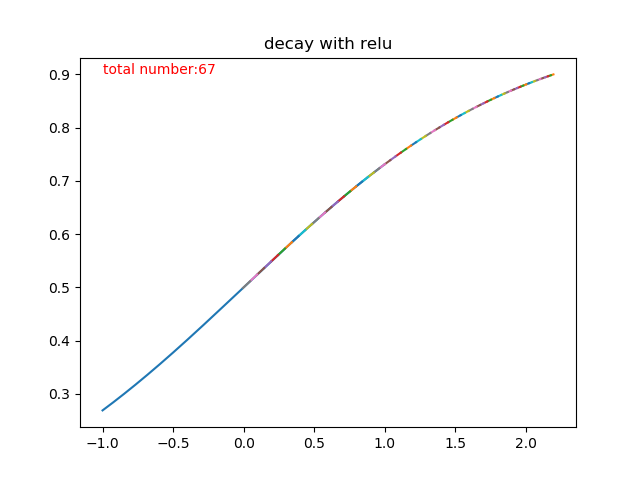
上半部分那條五彩斑斕的曲線就是迭代更新的過程了,一共迭代了多少次呢?根據程式統計,sigmoid迭代了67次才從0.9衰減到了接近0.5的水準。有同學可能會說了,才67次嘛,這個次數也不是很多啊!確實,從1層來看,這個速度還是可以接受的,但是神經網路只有這一層嗎?多層疊加之後的sigmoid函式,因為反向傳播的鏈式法則,兩層的梯度相乘,每次更新的步長更小,需要的次數更多,也就是速度更加慢。如果還是沒有反應過來的同學呢,可以先向下看relu函式的收斂速度。
此外,如果輸入資料是(-1, 1)範圍內的均勻分佈的資料會導致什麼樣的結果呢?經過sigmoid函式處理之後這些資料的均值就從0變到了0.5,導致了均值的漂移,在很多應用中,這個性質是不好的。
程式碼思路:
放到程式碼中應該怎麼實現呢?首先,對於一個輸入進sigmoid函式的向量來說,函式的輸出和反向傳播時的導數是和輸入的具體數值有關係的,那麼為了節省計算量,可以生成一個和輸入向量同尺寸的mask,用於記錄前向和反向傳播的結果,具體程式碼來說,就是:
示例程式碼:
class Csigmoid(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 記錄前向傳播結果
self.mask = 1 / (1 + np.exp(-1 * image))
return self.mask
def gradient(self, preError):
# 生成反向傳播對應位置的梯度
self.mask = np.multiply(self.mask, 1 - self.mask)
return np.multiply(preError, self.mask)不理解為啥又有前向傳播又有梯度計算的小夥伴請戳這裡
tanh函式
形式:
\(f(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}\)
\(f(z) = 2*sigmoid(2*z) - 1\)
反向傳播:
\(f^{'}(z) = (1 + f(z)) * (1 - f(z))\)
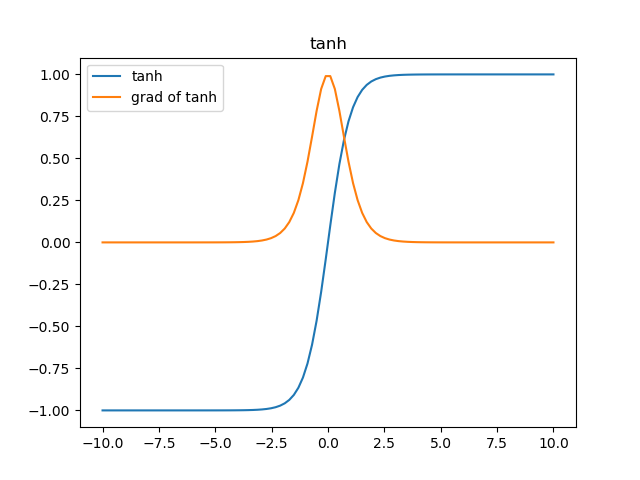
無論從理論公式還是函式影象,這個函式都是一個和sigmoid非常相像的啟用函式,他們的性質也確實如此。但是比起sigmoid,tanh減少了一個缺點,就是他本身是零均值的,也就是說,在傳遞過程中,輸入資料的均值並不會發生改變,這就使他在很多應用中能表現出比sigmoid優異一些的效果。
程式碼思路:
這麼相似的函式沒有相似的程式碼說不過去呀!比起sigmoid的程式碼,實現tanh只需要改變幾個微小的地方就可以了,話不多說,直接上程式碼吧:
示例程式碼:
class Ctanh(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 記錄前向傳播結果
self.mask = 2 / (1 + np.exp(-2 * image)) - 1
return self.mask
def gradient(self, preError):
# 生成反向傳播對應位置的梯度
self.mask = np.multiply(1 + self.mask, 1 - self.mask)
return np.multiply(preError, self.mask)relu函式
形式:
\[f(z) = \begin{cases} z & z \geq 0 \\ 0 & z < 0 \end{cases}\]
反向傳播:
\[f(z) = \begin{cases} 1 & z \geq 0 \\ 0 & z < 0 \end{cases}\]
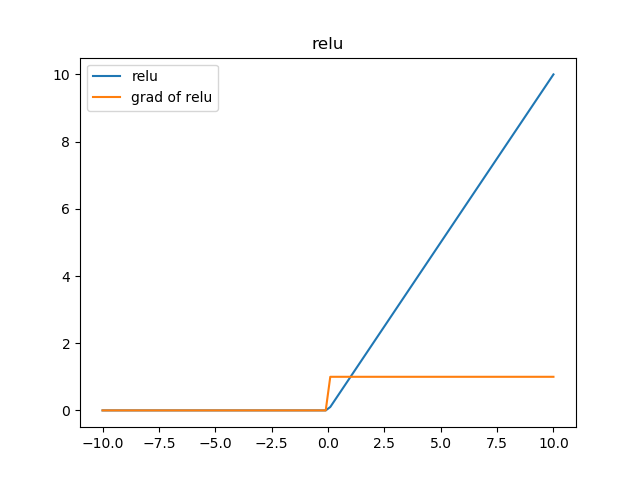
先來說說神經學方面的解釋,為什麼要使用relu呢?要說模仿神經元,sigmoid不是更好嗎?這就要看2001年神經學家模擬出的更精確的神經元模型Deep Sparse Rectifier Neural Networks。簡單說來,結論就是這樣兩幅圖:
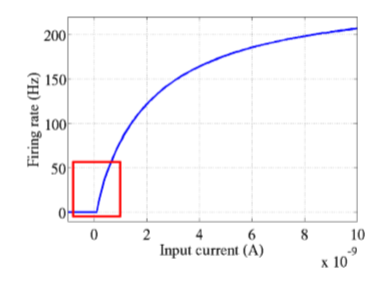
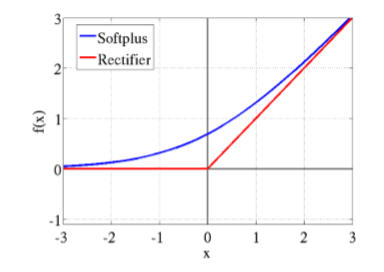
下面來解釋函式影象:在輸入的訊號比0大的情況下,直接將訊號輸出,否則的話將訊號抑制到0,相比較於上面兩個啟用函式,relu計算方面的開銷非常小,避免了指數運算和除法運算。此外,很多實驗驗證了採用relu函式作為啟用函式,網路收斂的速度可以更快。至於收斂更加快的原因,從圖上的梯度計算可以看出,relu的反向傳播梯度恆定是1,而sigmoid啟用函式中大多數時間梯度是比1小的。在疊加很多層之後,由於鏈式法則的乘法特性,sigmoid作為梯度函式會不斷減小反向傳播的梯度,而relu可以將比梯度原樣傳遞,也就是說,relu可以使用比較快的速度去進行引數更新。
用和sigmoid函式那裡更新相似的演算法步驟和引數,來模擬一下relu的梯度下降次數,也就是學習率\(\alpha = 0.2\),希望函式值從0.9衰減到0.5,這樣需要多少步呢?
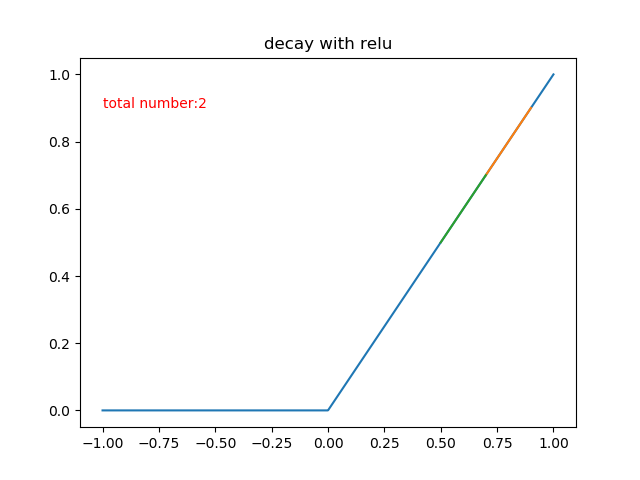
也就是說,同樣的學習速率,relu函式只需要兩步就可以做到sigmoid需要67步才能衰減到的程度!
但是如果回傳了一個很大的梯度導致網路更新之後輸入訊號小於0了呢?那麼這個神經元之後接受到的資料是零,對應新的回傳的梯度也是零,這個神經元將不被更新,下一次輸入的訊號依舊小於零,不停重複這個過程。也就是說,這個神經元不會繼續更新了,這個神經元“死”掉了。在學習率設定不恰當的情況下,很有可能網路中大部分神經元“死”掉,也就是說不起作用了,而這是不可取的。
程式碼實現:
與sigmoid類似,relu函式的前向傳播和反向傳播與輸入的大小有關係,小於0的輸入可以被簡單的置成0,不小於0的可以繼續向下傳播,也就是將輸入和0中較大的值繼續傳播,對輸入向量逐元素做比較即可。考慮到反向傳播時梯度計算也和輸入有關,使用一個mask對資料或者根據資料推出的反向傳播結果做一個記錄也是一個比較好的選擇。
示例程式碼:
class Crelu(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 用於記錄傳遞的結果
self.mask = np.zeros(self.shape)
self.mask[image > 0] = 1
# 將小於0的項截止到0
return np.maximum(image, 0)
def gradient(self, preError):
# 將上一層傳遞的誤差函式和該層各位置的導數相乘
return np.multiply(preError, self.mask)想想看,relu函式的缺點是什麼呢?是梯度很大的時候可能導致的神經元“死”掉。而這個死掉的原因是什麼呢?是因為很大的梯度導致更新之後的網路傳遞過來的輸入是小於零的,從而導致relu的輸出是0,計算所得的梯度是零,然後對應的神經元不更新,從而使relu輸出恆為零,對應的神經元恆定不更新,等於這個relu失去了作為一個啟用函式的夢想。問題的關鍵點就在於輸入小於零時,relu回傳的梯度是零,從而導致了後面的不更新。
那麼最簡單粗暴的做法是什麼?在輸入函式值小於零的時候給他一個梯度不就好了!這就是leaky relu函式的表現形式了!
leaky relu函式
形式:
\[f(z) = \begin{cases} z & z \geq 0 \\ \alpha * z & z < 0 \end{cases}\]
反向傳播:
\[f(z) = \begin{cases} z & 1 \geq 0 \\ \alpha & z < 0 \end{cases}\]
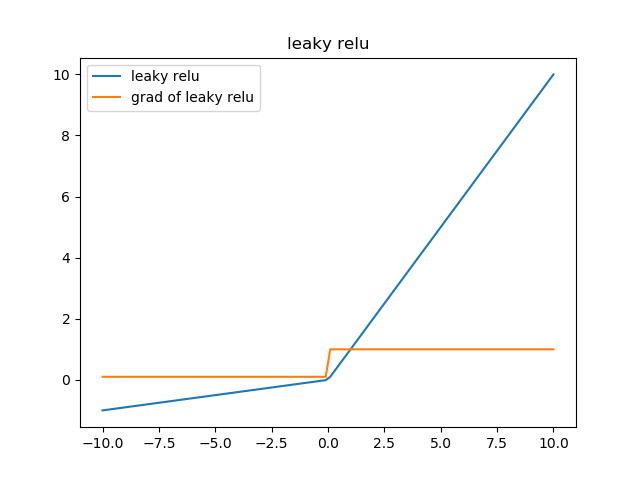
相比較於relu函式,leaky relu同樣有收斂快速和運算複雜度低的優點,而且由於給了\(x<0\)時一個比較小的梯度\(\alpha\),使得\(x<0\)時依舊可以進行梯度傳遞和更新,可以在一定程度上避免神經元“死”掉的問題。
示例程式碼:
class CleakyRelu(object):
def __init__(self, inputSize, alpha):
self.shape = inputSize
self.alpha = alpha
def forward(self, image):
# 用於記錄傳遞的結果,按照傳遞公式生成對應的值
self.mask = np.zeros(self.shape)
self.mask[image > 0] = 1
self.mask[image <= 0] = self.alpha
# 將該值對應到輸入中
return np.multiply(image, self.mask)
def gradient(self, preError):
# 將上一層傳遞的誤差函式和該層各位置的導數相乘
return np.multiply(preError, self.mask)softmax 函式
softmax函式,是大名鼎鼎的在計算多分類問題時常使用的一個函式,他長成這個樣子:
\[ \phi(z_j) = \frac{e^{z_j}}{\sum\limits_ie^{z_i}} \]
也就是說把接收到的輸入歸一化成一個每個分量都在\((0,1)\)之間並且總和為一的一個概率函式。
用一張圖來形象說明這個過程
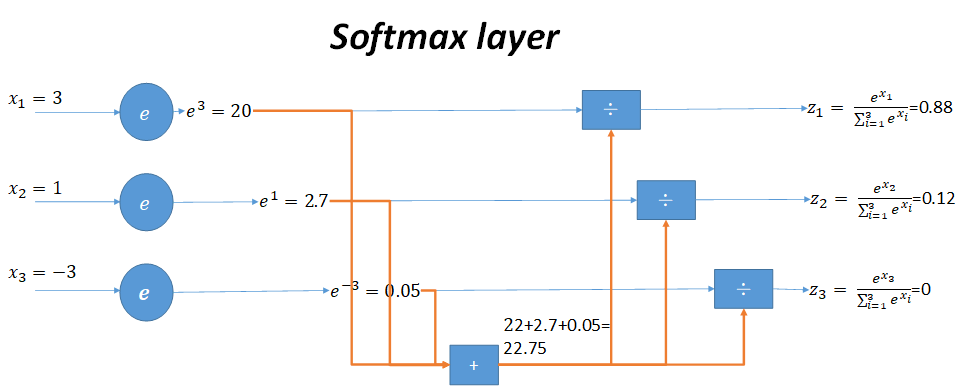
當輸入的資料是3,1,-3時,按照圖示過程進行計算,可以得出輸出的概率分佈是0.88,0.12,0。
試想如果我們並沒有這樣一個softmax的過程而是直接根據3,1,-3這樣的輸出,而我們期望得結果是1,0,0這樣的概率分佈結果,那傳遞給網路的資訊是什麼呢?我們要抑制正樣本的輸出,同時要抑制負樣本的輸出。正樣本的輸出和期望的差距是2,負樣本1和期望的差距是0,所以網路要更加抑制正樣本的結果!所以,在輸出結果相對而言已經比較理想的情況下,我們給了網路一個相對錯誤的更新方向:更多的抑制正樣本的輸出結果。這顯然是不可取的呀!
從繼承關係的角度來說,softmax函式可以視作sigmoid的一個擴充套件,比如我們來看一個二分類問題,
\[ \phi(z_1) = \frac{e^{z_1}}{e^{z_1} + e^{z_2}} = \frac{1}{1 + e^{z_2 - z_1}} = \frac{1}{1 + e^{z_2} e^{- z_1}} \]
是不是和sigmoid的函式形式非常像?比起原始的sigmoid函式,softmax的一個優勢是可以用在多分類的問題中。另一個好處是在計算概率的時候更符合一般意義上我們認知的概率分佈,體現出物體屬於各個類別相對的概率大小。
既然採用了這個函式,那麼怎麼計算它的反向傳播呢?
這裡為了方便起見,將\(\sum\limits_{i \neq j}e^{z_i}\)記作\(k\),那麼,
\[ \phi(z_j) = \frac{e^{z_j}}{\sum\limits_ie^{z_i}} = \frac{e^{z_j}}{k + e^{z_j}} \]
\[ \therefore \frac{\partial\phi(z_j)}{\partial z_j} = \frac{e^{z_j}(k + e^{z_j}) - e^{z_j} * e^{z_j}}{{(k + e^{z_j})}^2} = \frac{e^{z_j}}{k + e^{z_j}}\frac{k}{k + e^{z_j}} = softmax(z_j)(1 - softmax(z_j)) \]
也就是說,softmax的梯度就是\(softmax(z_j)(1 - softmax(z_j))\),之後將這個梯度進行反向傳播就可以大功告成啦~
損失函式
作用
在有監督的學習中,需要衡量神經網路輸出和所預期的輸出之間的差異大小。這種誤差函式需要能夠反映出當前網路輸出和實際結果之間一種量化之後的不一致程度,也就是說函式值越大,反映出模型預測的結果越不準確。
還是拿練槍的Bob做例子,Bob預期的目標是全部命中靶子的中心,但他現在的命中情況是這個樣子的:
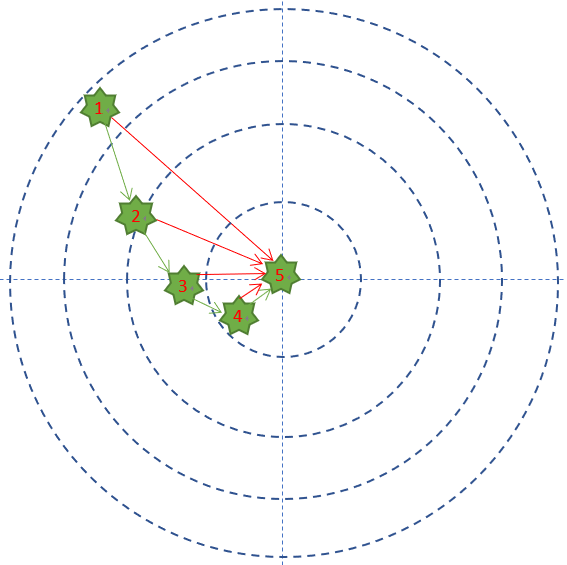
最外圈是1分,之後越向靶子中心分數是2,3,4分,正中靶心可以得5分。
那Bob每次射擊結果和目標之間的差距是多少呢?在這個例子裡面,用得分來衡量的話,就是說Bob得到的反饋結果從差4分,到差3分,到差2分,到差1分,到差0分,這就是用一種量化的結果來表示Bob的射擊結果和目標之間差距的方式。也就是誤差函式的作用。因為是一次只有一個樣本,所以這裡採用的是誤差函式的稱呼。如果一次有多個樣本,那麼就要稱呼這樣子衡量不一致程度的函式就要叫做損失函數了。
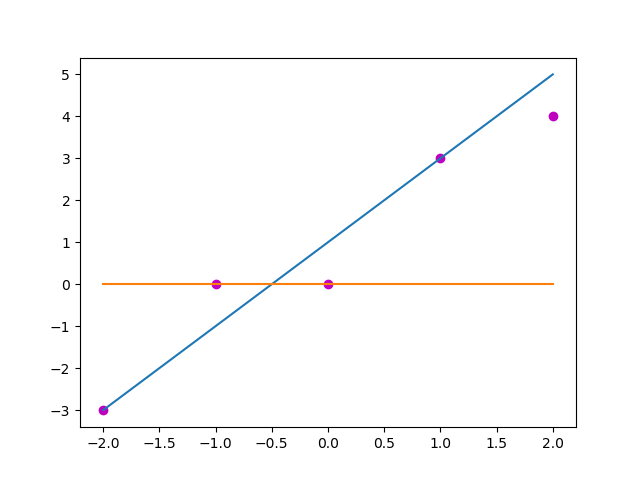
以做線性迴歸的實際值和預測值為例,若自變數x是[-2, -1, 0, 1, 2]這樣5個值,對應的期望值y是[-3, 0, 0, 3, 4]這樣的值,目前預測使用的引數是(w, b) = (2, 1), 那麼預測得到的值y_ = [-3, -1, 1, 3, 5], 採用均方誤差計算這個預測和實際的損失就是\(\sum_{i = 0}^{4}(y[i] - y_\_[i])^{2}\), 也就是3。那麼如果採用的參量是(0, 0),預測出來的值是[0, 0, 0, 0, 0],這是一個顯然錯誤的預測結果,此時的損失大小就是34,\(3 < 34\), 那麼(2, 1)是一組比(0, 0)要合適的參量。
那麼常用的損失函式有哪些呢?
這裡先給一些前提,比如神經網路中的一個神經元:
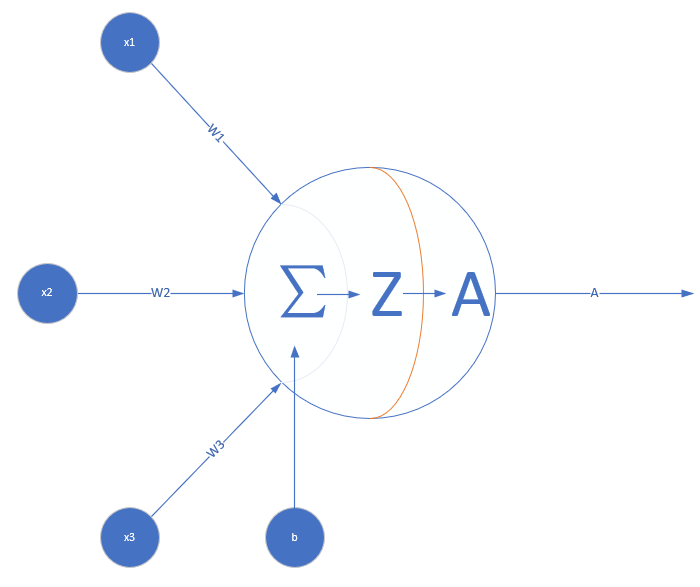
圖中 \(z = \sum\limits_{i}w_i*x_i+b_i=\theta^Tx\),\(\sigma(z)\)是對應的啟用函式,也就是說,在反向傳播時梯度的鏈式法則中,
\[\frac{\partial{z}}{\partial{w_i}}=x_i \tag{1}\]
\[\frac{\partial{z}}{\partial{b_i}}=1 \tag{2}\]
\[\frac{\partial{loss}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}x_i \tag{3}\]
\[\frac{\partial{loss}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} \tag{4}\]
從公式\((3),(4)\)可以看出,梯度計算中的公共項是\(\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} = \frac{\partial{loss}}{\partial{z}}\)。
下面我們來探討\(\frac{\partial{loss}}{\partial{z}}\)的影響。由於梯度的計算和函式的形式是有關係的,所以我們會從常用損失函式入手來逐個說明。
常用損失函式
- MSE (均方誤差函式)
該函式就是最直觀的一個損失函數了,計算預測值和真實值之間的歐式距離。預測值和真實值越接近,兩者的均方差就越小。
- 想法來源
在給定一些點去擬合直線的時候(比如上面的例子),常採用最小二乘法,使各個訓練點到擬合直線的距離儘量小。這樣的距離最小在損失函式中的表現就是預測值和真實值的均方差的和。 - 函式形式:
\[loss = \frac{1}{2}\sum_{i}(y[i] - a[i]) ^ 2\],
其中, \(a\)是網路預測所得到的結果,\(y\)代表期望得到的結果,也就是資料的標籤,\(i\)是樣本的序號。 - 反向傳播:
\[\frac{\partial{loss}}{\partial{z}} = \sum_{i}(y[i] - a[i])*\frac{\partial{a[i]}}{\partial{z}}\] 缺點:
和\(\frac{\partial{a[i]}}{\partial{z}}\)關係密切,可能會產生收斂速度緩慢的現象,以下圖為例(啟用函式為sigmoid)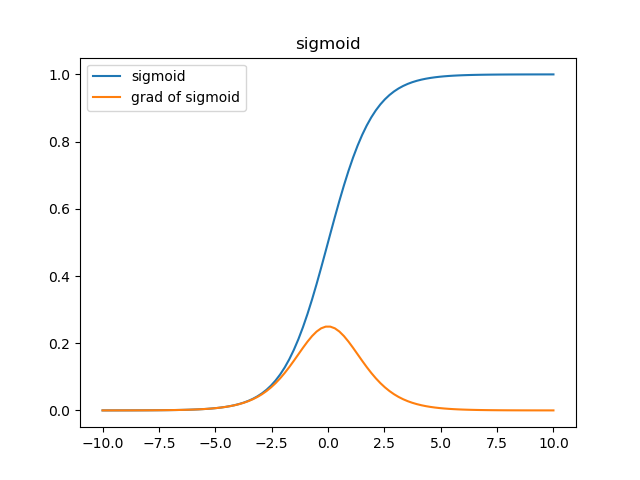
在啟用函式的兩端,梯度(黃色)都會趨向於0,採取MSE的方法衡量損失,在\(a\)趨向於1而\(y\)是0的情況下,損失loss是1,而梯度會趨近於0,在誤差很大時收斂速度也會非常慢。
在這裡我們可以參考activation中關於sigmoid函式求導的例子,假定x保持不變,只有一個輸入的一個神經元,權重\(w = ln(9)\), 偏置\(b = 0\),也就是這樣一個神經元:
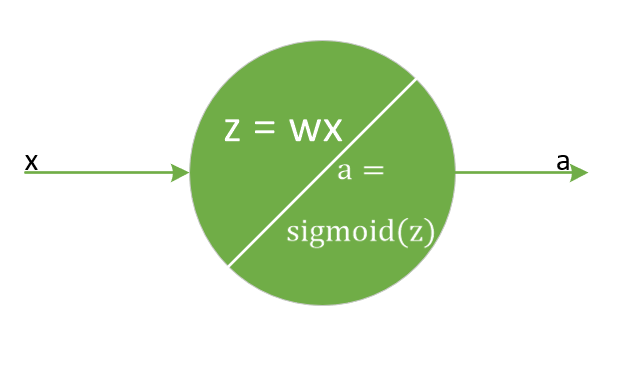
保持引數統一不變,也就是學習率\(\eta = 0.2\),目標輸出\(y = 0.5\), 此處輸入x固定不變為\(x = 1\),採用MSE作為損失函式計算,一樣先做公式推導,
第一步,計算當前誤差
\[loss = \frac{1}{2}(a - y)^2 = \frac{1}{2}(0.9 - 0.5)^2 = 0.08\]
第二步,求出當前梯度
\[grad = (a - y) \times \frac{\partial{a}}{\partial{z}} \frac{\partial{z}}{\partial{w}} = (a - y) \times a \times (1 - a) \times x = (0.9 - 0.5) \times 0.9 \times (1-0.9) \times 1= 0.036\]
第三步,根據梯度更新當前輸入值
\[w = w - \eta \times grad = ln(9) - 0.2 \times 0.036 = 2.161\]
第四步,計算當前誤差是否小於閾值(此處設為0.001)
\[a = \frac{1}{1 + e^{-wx}} = 0.8967\]
\[loss = \frac{1}{2}(a - y)^2 = 0.07868\]第五步,重複步驟2-4直到誤差小於閾值
作出函式影象如圖所示:
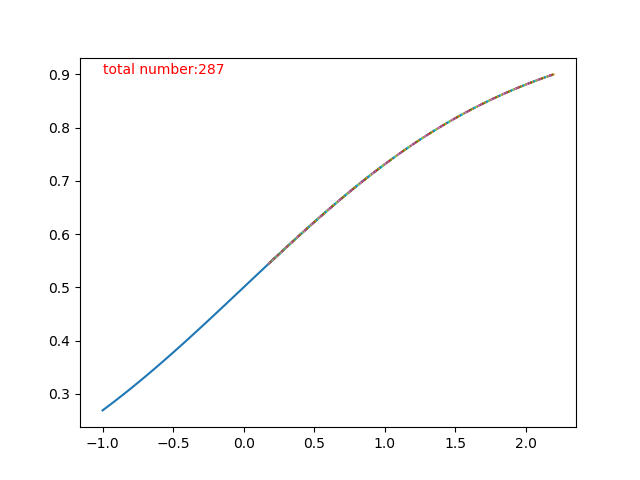
可以看到函式迭代了287次從才收斂到接近0.5的程度,這比單獨使用sigmoid函式還要慢了很多。
- 交叉熵函式
這個損失函式的目的是使得預測得到的概率分佈和真實的概率分佈儘量的接近。兩個分佈越接近,那麼這個損失函式得到的函式值就越小。怎麼去衡量兩個分佈的接近程度呢?這就要用到夏農資訊理論中的內容了。兩個概率分佈之間的距離,也叫做KL Divergence,他的定義是這個形式的,給定離散概率分佈P(x), Q(x),這兩個分佈之間的距離是
\[ D_{KL}(P || Q) = - \sum_{i}P(i)log(\frac{Q(i)}{P(i)})\]
試想如果兩個分佈完全相同,那麼\(log(\frac{Q(i)}{P(i)}) = 0\), 也就是兩個分佈之間的距離是零,如果兩個分佈差異很大,比如一個是\(P(0)=0.9, P(1)=0.1\),另一個是\(Q(0)=0.1,Q(1)=0.9\),那麼這兩個分佈之間的距離就是0.763,如果是\(Q(0)=0.5,Q(1)=0.5\),那麼距離就是0.160,直覺上來說兩個分佈越接近那麼他們之間的距離就是越小的,具體的理論證明參看《資訊理論基礎》,不過為什麼要選用這個作為損失函式呢?
從最大似然角度開始說
關於最大似然,請參看:將神經網路的引數作為\(\theta\),資料的真實分佈是\(P_{data}(y;x)\), 輸入資料為\(x\),那麼在\(\theta\)固定情況下,神經網路輸出\(y\)的概率就是\(P(y;x, \theta)\),構建似然函式,
\[L = \sum_{i}log(P(y_i;x_i, \theta))\],
以\(\theta\)為引數最大化該似然函式,即\(\theta^{*} = {argmax}_{\theta}L\)。
真實分佈\(P(x_i)\)對於每一個\((i, x_i, y_i)\)來說均是定值,在確定\(x_i\)情況下,輸出是\(y_i\)的概率是確定的。在一般的情況下,對於每一個確定的輸入,輸出某個類別的概率是0或者1,所以可以將真實概率新增到上述式子中而不改變式子本身的意義:\[\theta^{*} = {argmax}_{\theta}\sum_{i}P_{data}(y_i;x_i)log(P(y_i;x_i, \theta))\]
將\(D_{KL}\)展開,得到,
\[D_{KL}(P || Q) = - \sum_{i}P(i)log(\frac{Q(i)}{P(i)}) = \sum_{i}P(i)log(P(i)) - \sum_{i}P(i)log(Q(i)) \]
\(P(i)\)代表\(P_{data}(y_i;x_i)\), \(Q(i)\)代表\(P(y_i;x_i,\theta)\)。
上述右側式中第一項是和僅真實分佈\(P(i)\)有關的,在最小化\(D_{KL}\)過程中是一個定值,所以最小化\(D_{KL}\)等價於最小化\(-\sum_{i}P(i)log(Q(i))\),也就是在最大化似然函式。- 函式形式(以二分類任務為例):
\[loss = \sum_{i}y(x_i)log(a(x_i)) + (1 - y(x_i))log(1 - a(x_i))\]
其中,\(y(x_i)\)是真實分佈,\(a(x_i)\)是神經網路輸出的概率分佈 反向傳播:
\[\frac{\partial{loss}}{\partial{z}} = (-\frac{y(z)}{a(z)} + \frac{1 - y(z)}{1 - a(z)})*\frac{\partial{a(z)}}{\partial{z}} = \frac{a(z) - y(z)}{a(z)(1-y(z))}*\frac{\partial{a(z)}}{\partial{z}}\]在使用sigmoid作為啟用函式情況下,\(\frac{\partial{a(z)}}{\partial{z}} = a(z)(1-a(z))\),也就是說,sigmoid本身的梯度和分母相互抵消,得到,
\[\frac{\partial{loss}}{\partial{z}} = \frac{a(z) - y(z)}{y(z)(1-a(z))}*\frac{\partial{a(z)}}{\partial{z}} = a(z) - y(z)\]
在上述反向傳播公式中不再涉及到sigmoid本身的梯度,故不會受到在誤差很大時候函式飽和導致的梯度消失的影響。
總的說來,在使用sigmoid作為啟用函式時,使用交叉熵計算損失往往比使用均方誤差的結果要好上一些。但是,這個也並不是絕對的,需要具體問題具體分析,針對具體應用,有時需要自行設計損失函式來達成目標。
參考資料:
- 函式形式(以二分類任務為例):
本系列部落格連結: