
Logistic Regression(邏輯迴歸)
分類是機器學習的一個基本問題, 基本原則就是將某個待分類的事情根據其不同特徵劃分為兩類.
- Email: 垃圾郵件/正常郵件
- 腫瘤: 良性/惡性
- 蔬菜: 有機/普通
對於分類問題, 其結果 y∈{0,1}, 即只有正類或負類. 對於預測蔬菜是否為有機這件事, y = 0表示蔬菜為普通, y= 1表示蔬菜為有機.
邏輯迴歸是分類問題中的一個基本演算法, 它的猜想函式hθ(x) = g(θT*x)
其中, g(z) = 1 / (1+e-z), 該函式稱為sigmoid函式或logistic函式, 是一個增函式,輸出對映g(z)∈[0,1].

hθ(x)表示當輸入為x, (權重)引數為θ時, 預測y=1的概率.
程式碼實現:
function g = sigmoid(z)
%SIGMOID Compute sigmoid function
% g = SIGMOID(z) computes the sigmoid of z.
g = zeros(size(z));
for i = 1:size(z,1)
for j = 1:size(z,2)
g(i,j) = 1/(1+e^(-z(i,j)));
endfor
endfor
end
對於邏輯迴歸的猜想函式hθ(x) = g(θT*x), 當θT*x = 0時, hθ(x) = 0.5. 而我們規定當hθ(x) >= 0.5, 即θT
因此, 通過給定的權重引數矩陣與特徵值, 可以計算出該預測函式的決策邊界 , 通過這條邊界即可將問題進行分類.

邏輯迴歸演算法的代價函式表示當預測值與實際值產生偏差時所承受的懲罰大小, 公示表示為cost(hθ(x), y) = -log(hθ(x)), if y =1, -log(1-hθ(x)), if y = 0.
當y=1時,假定這個樣本為正類。如果此時hθ(x) = 1,則對這個樣本而言的cost=0,表示這個樣本的預測完全準確。但是如果此時預測的概率hθ
為了獲得更準確的分類決策邊界, 我們需要調節代價函式到最小值, 這時, 預測值與實際結果間偏差最小. 為了最小化代價函式, 我們需要調節引數θ. 比較常用的方法為梯度下降法.
梯度下降是迭代法的一種, 其計算過程就是沿梯度下降的方向求解極小值.
邏輯迴歸代價函式J(θ):
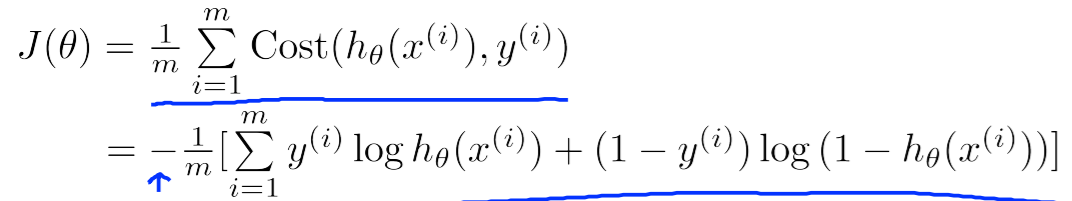
為了最小化J(θ), 需要不斷重複減小θ的值直到J(θ)收斂:

其中α為學習速率, 即每次下降的步長大小, 如果α過於大, 可能導致無法收斂, 如果α過於小, 可能導致收斂速度過慢.
程式碼實現:
function [J, grad] = costFunction(theta, X, y)
%COSTFUNCTION Compute cost and gradient for logistic regression
% J = COSTFUNCTION(theta, X, y) computes the cost of using theta as the
% parameter for logistic regression and the gradient of the cost
% w.r.t. to the parameters.
% Initialize some useful values
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
Jtmp=0;
h= zeros(m,1);
%step1:compute hx
hx = X * theta;
%step2:compute h(hx)
h = sigmoid(hx);
%step3:compute cost function's sum part
for i=1:m,
Jtmp=Jtmp+(-y(i)*log(h(i))-(1-y(i))*log(1-h(i)));
endfor
J=(1/m)*Jtmp;
%step4:compute gradient's sum part
sum1 =zeros(size(X,2),1);%#features row
for i=1:m
sum1 = sum1+(h(i)-y(i)).*X(i,:)';
endfor
grad= (1/m)*sum1;
end