
演算法學習——邏輯迴歸(Logistic Regression)
1.Logistic Regression
1.1什麼是迴歸?
英文單詞Regression翻譯成中文“迴歸”,那什麼是迴歸呢?事實上,在Logistic迴歸出現以前,人們最先引入的是線性迴歸。瞭解二者之間的來龍去脈將幫助你更深刻地認識Logistic迴歸。
迴歸一詞最早由英國科學家弗朗西斯·高爾頓(Francis Galton)提出,他還是著名的生物學家、進化論奠基人查爾斯·達爾文(Charles Darwin)的表弟。高爾頓深受進化論思想的影響,並把該思想引入到人類研究,從遺傳的角度解釋個體差異形成的原因。
高爾頓發現,雖然有一個趨勢——父母高,兒女也高;父母矮,兒女也矮,但給定父母的身高,兒女輩的平均身高卻趨向於或者“迴歸”到全體人口的平均身高。換句話說,即使父母雙方都異常高或者異常矮,兒女的身高還是會趨向於人口總體的平均身高。這也就是所謂的普遍迴歸規律。
高爾頓的這一結論被他的朋友,英國數學家、數理統計學的創立者卡爾·皮爾遜(Karl Pearson)所證實。皮爾遜收集了一些家庭的1000多名成員的身高記錄,發現對於一個父親高的群體,兒輩的平均身高低於他們父輩的身高;而對於一個父親矮的群體,兒輩的平均身高則高於其父輩的身高。這樣就把高的和矮的兒輩一同“迴歸”到所有男子的平均身高,用高爾頓的話說,這是“迴歸到中等”。
迴歸分析是被用來研究一個被解釋變數(Explained Variable)與一個或多個解釋變數(Explanatory Variable)之間關係的統計技術。被解釋變數有時也被稱為因變數(Dependent Variable),與之相對應地,解釋變數也被稱為自變數(Independent Variable)。迴歸分析的意義在於通過重複抽樣獲得的解釋變數的已知或設定值來估計或者預測被解釋變數的總體均值。
如果你對上面這段話感到困惑,不妨來看看下面這張圖。圖上有一些觀測到的樣本點,線性迴歸的任務就在於通過一條線來最大程度地擬合這些點。例如,我們已經得到了一些父輩與兒輩身高的資料,而且我們認為兒輩的身高在很大程度上依賴於父輩的身高。那麼,我們就可以把兒輩身高看成是被解釋變數(即圖中的縱軸),把父輩身高看成是解釋變數(即圖中的衡軸)。然後通過一條迴歸線來擬合這些資料,如此一來,當我們已知一個父親的身高時,就可以通過迴歸線所表現出來的線性關係推測出兒子身高的大概水平。

線上性迴歸中,我們假設被解釋變數 與解釋變數
之間具有線性相關的關係,那麼用公式就可以將線性迴歸模型表示為
其中 表示常數項,上圖中因為自變數只有一個,所以一元線性迴歸的公式表示應該是
,顯然它是多元線性迴歸模型中最簡單的情況。
1.2Logistic的引入
已經掌握了線性迴歸的基本內容。現在我們來看一個稍微有點變化的例子。
為研究與急性心肌梗塞急診治療情況有關的因素,現收集了200個急性心肌梗塞的病例,如下表所示。其中,用於指示救治前是否休克,
表示救治前已休克,
表示救治前未休克;
用於指示救治前是否心衰,
表示救治前已發生心衰,
表示救治前未發生心衰;
用於指示12小時內有無治療措施,
表示沒有,否則
。最後給出了病患的最終結局,當
時,表示患者生存;否則當
時,表示患者死亡。
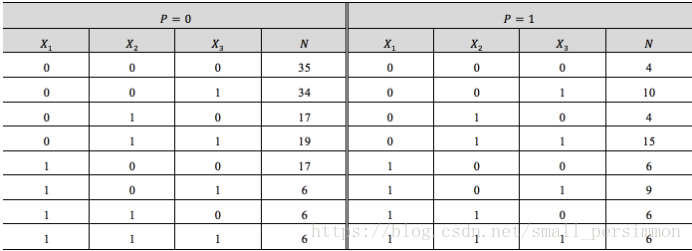
如果要建立迴歸模型,進而來預測不同情況下病患生存的概率,考慮用多重回歸來做,(注意我們將大寫換成了小寫)即
則顯然將自變數帶入上述迴歸方程,不能保證概率 一定位於0~1。於是想到用Logistic函式將自變數對映至0~1。Logistic函式的定義如下:
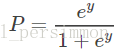
或
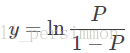
其函式的影象如圖下所示。
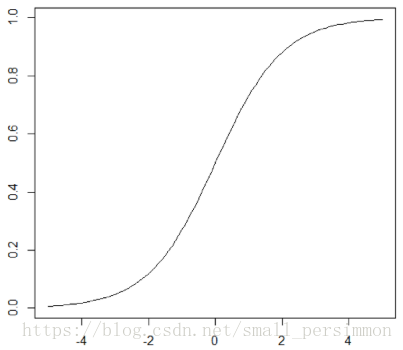
然後上面的函式定義式將多元線性迴歸中的因變數替換得到
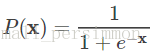
其中 ,而且在我們當前所討論的例子中
。
上式中的,⋯,
正是我們要求的引數,通常採用極大似然估計法對引數進行求解。對於本題而言則有

進而有(β 就是我們所討論的引數 )

當我們得到上面最後一個公式的時候,如果再有一組觀察樣本,將其帶入公式,就可以算得病人生存與否的概率。
以上我們就通過了一個例子向讀者演示瞭如何從原始的線性迴歸演化出Logistic迴歸。而且,不難發現,Logistic迴歸可以用作機器學習中的分類器。當我們得到一個事件發生與否的概率時,自然就已經得出結論,其到底應該屬於“發生”的那一類別,還是屬於“不發生”的那一類別。
接下來我們要從整個具體的例子中抽象出Logistic迴歸的一般化過程。併為後續一些文章的討論埋下伏筆。
所謂機器學習,最終是讓機器自己學到一個可以用於問題解決的模型。而這個模型本質上是由一組引數定義的,也就是前面討論的 ,⋯,
。在得到測試資料時,將這組引數(在Logistic迴歸中也可以認為是權值)與測試資料線性加和得到
這裡 ⋯
是每個樣本的
個特徵。之後再按照Logistic函式的形式求出

在給定特徵向量時,條件概率
為根據觀測量某事件
發生的概率。那麼Logistic迴歸模型可以表示為

相對應地,在給定條件 時,事件
不發生的概率為
而且還可以得到事件發生與不發生的概率之比為
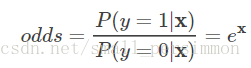
這個比值稱為事件的發生比。
概率論的知識告訴我們引數估計時可以採用最大似然法。假設有個觀測樣本,觀測值分別為
,⋯,
,設
為給定條件下得到
的概率。同樣地,
的概率為
,所以得到一個觀測值的概率為
。
各個觀測樣本之間相互獨立,那麼它們的聯合分佈為各邊緣分佈的乘積。得到似然函式為

然後我們的目標是求出使這一似然函式值最大的引數估計,於是對函式取對數得到

根據多元函式求極值的方法,為了求出使得最大的向量
,對上述的似然函式求偏導後得到

現在,我們所要做的就是通過上面已經得到的結論來求解使得似然函式最大化的引數向量。在實際中有很多方法可供選擇,其中比較常用的包括梯度下降法、牛頓法和擬牛頓法等。
2.Softmax迴歸
3. LogisticRegression 引數說明
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False,
tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None,solver=’liblinear’, max_iter=100, multi_class=’ovr’,
verbose=0, warm_start=False, n_jobs=1)[source]引數說明:

OvO OvR MvM區別與聯絡
參考文章: