
目標檢測“Perceptual Generative Adversarial Networks for Small Object Detection”
解決小目標檢測問題的一般方法:提高輸入影象的解析度,會增加運算量;多尺度特徵表示,結果不可控。
方法提出
論文使用感知生成式對抗網路(Perceptual GAN)提高小物體檢測率,generator將小物體的poor表示轉換成super-resolved的表示,discriminator與generator以競爭的方式分辨特徵。Perceptual GAN挖掘不同尺度物體間的結構關聯,提高小物體的特徵表示,使之與大物體類似。包含兩個子網路,生成網路和感知分辨網路。生成網路是一個深度殘差特徵生成模型,通過引入低層精細粒度的特徵將原始的較差的特徵轉換為高分變形的特徵。分辨網路一方面分辨小物體生成的高解析度特徵與真實大物體特徵,另一方面使用感知損失提升檢測率。在交通標誌資料庫Tsinghua-Tencent 100k及Caltech上實驗。
Perceptual GAN
1. 概述
目標函式:
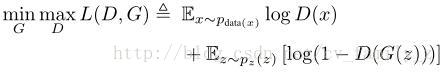
G標識生成器,D是分辨器。訓練G的過程,最大化D犯錯的概率。x,z是大物體,小物體的表示。學習G將小物體的標識轉換為超分辨的形式,使之類似於大目標的特徵。由於資訊的缺乏,這個過程比較困難。引入附加資訊,學習大物體和小物體見的殘差表示,即,
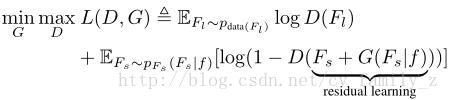
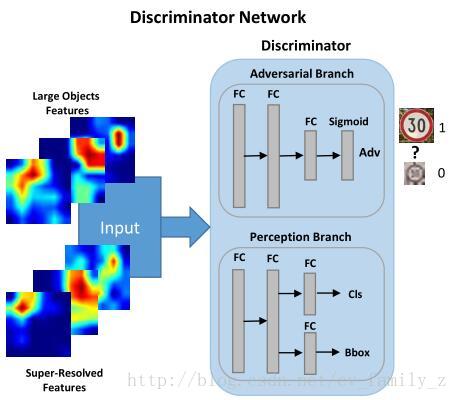
分辨器有兩個分支,對抗分支分辨生成的小物體特徵與實際大物體特徵,感知分支解釋生成表示的檢測率增益。使用交替的方式優化生成器和分辨器網路的引數,解決對抗min-max問題。訓練對抗網分支最大化分配相同標籤給小物體生成特徵和大物體特徵的概率。分辨網路是為了儘可能的找出小物體生成特徵和實際大物體特徵的不同。這樣監督生成網路生成更接近實際的小物體特徵。Perceptual GAN總體結構如下圖所示:
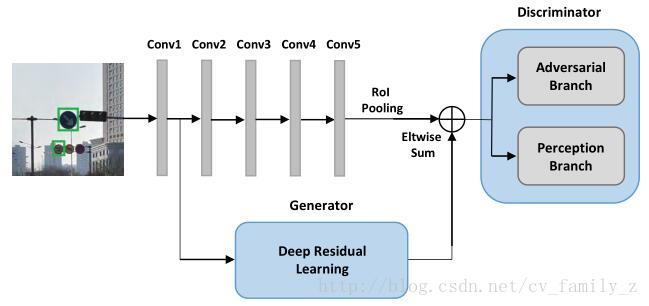
將物體分為大物體和小物體兩個子集,感知分支先在大物體特徵上訓練,獲得較高的檢測率,然後使用小物體訓練生成網路,兩個子集對抗分支。交替訓練生成網路和對抗分支,達到平衡點。
2. 生成網路
深度殘差網路,增強小物體標識,生成器將conv1的輸出作為輸入,經歷卷積,殘差塊學習大物體和小物體間的殘差表示,學到的殘差標識與原con5特徵元素加操作,得到提升的表示。
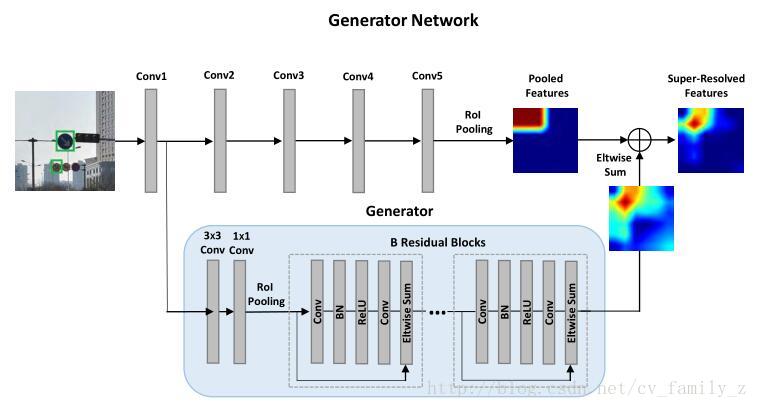
3. 分辨網路結構
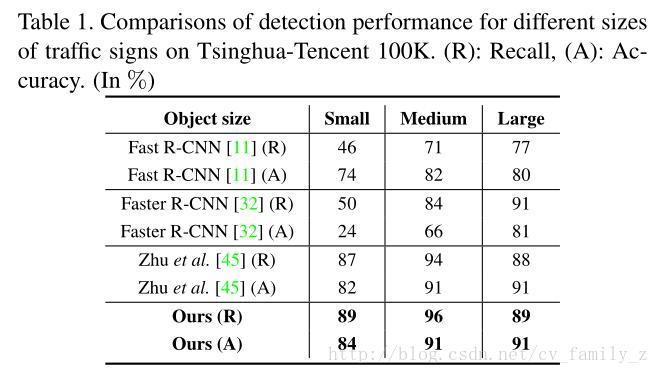
實驗結果
與Faster-rcnn相比,小物體檢測率確實提高很多,期待原始碼
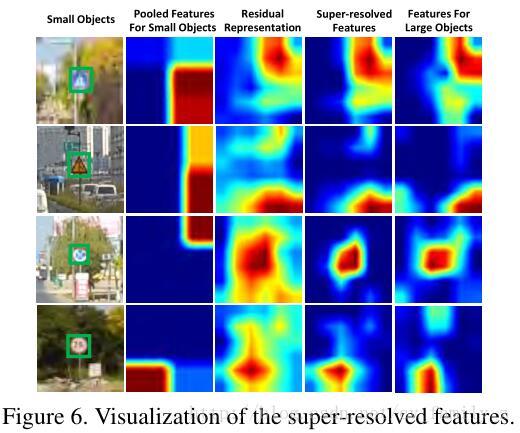
生成網路生存的特徵
相關推薦
目標檢測“Perceptual Generative Adversarial Networks for Small Object Detection”
解決小目標檢測問題的一般方法:提高輸入影象的解析度,會增加運算量;多尺度特徵表示,結果不可控。 方法提出 論文使用感知生成式對抗網路(Perceptual GAN)提高小物體檢測率,generator將小物體的poor表示轉換成super-resolved的
論文解讀:DeLiGAN: Generative Adversarial Networks for Diverse and Limited Data
前言:DeLiGAN是計算機視覺頂會CVPR2017發表的一篇論文,本文將結合Python原始碼學習DeLiGAN中的核心內容。DeLiGAN最大的貢獻就是將生成對抗網路(GANs)的輸入潛空間編碼為混合模型(高斯混合模型),從而使得生成對抗網路(GANs)在數量有限但具有多樣性的訓練資料上表現出較
特徵金字塔特徵用於目標檢測:Feature Pyramid Networks for Object Detection
前言: 這篇論文主要使用特徵金字塔網路來融合多層特徵,改進了CNN特徵提取。作者也在流行的Fast&Faster R-CNN上進行了實驗,在COCO資料集上測試的結果現在排名第一,其中隱含的說明了其在小目標檢測上取得了很大的進步。其實整體思想比較簡單,但是實驗部分
【轉】論文閱讀(Chenyi Chen——【ACCV2016】R-CNN for Small Object Detection)
數據 大小 table 使用 con 改進 包括 end 修改 Chenyi Chen——【ACCV2016】R-CNN for Small Object Detection 目錄 作者和相關鏈接 方法概括 創新點和貢獻 方法細節 實驗結果 總結與收獲點 參考文獻
[論文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 這是一篇2016年的目標檢測的文章,也是一篇比較經典的目標檢測的文章。作者介紹到,現在表現最好的方法非常的複雜,而本文的方法,簡單又容
Region-based Convolutional Networks for Accurate Object Detection and Segmentation----R-CNN論文筆記
一、為什麼提出R-CNN 目標檢測效能停滯不前,效能最好的整合方法又太複雜,所以作者提出了一個既能大幅提升效能,又更簡單的R-CNN。 二、R-CNN的框架 上面的框架圖清晰的給出了R-CNN的目標檢測流程: 1) 輸入測試影象 2) 利用s
【論文筆記】Region-based Convolutional Networks for Accurate Object Detection and Segmentation
《Region-based Convolutional Networks for Accurate Object Detection and Segmentation》是將卷積神經網路應用於物體檢測的一篇經典文章。 整個識別過程可以用下面的一張圖片來清晰的表示: 首先給定一
論文筆記:Spectral Normalization for Generative Adversarial Networks [ICLR2018 oral]
Spectral Normalization for Generative Adversarial Networks 原文連結:傳送門 一篇純數學類文章,有興趣的時候再看! Emma CUH
【論文筆記】An Intelligent Fault Diagnosis Method Using: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks
ivar 單位矩陣 作用 一次 一個 http example tps 計算 論文來源:IEEE TRANSACTIONS ON INDUSTRIAL ELECTRONICS 2016年的文章,SCI1區,提出了兩階段的算法。第一個階段使用Sparse filtering
FACE AGING WITH CONDITIONAL GENERATIVE ADVERSARIAL NETWORKS
文章用於生成不同年齡的圖片,採用的模型是條件對抗網路,主要創新點是,首先通過一個網路,提取影象特徵向量,並通過身份保持網路,優化影象的特徵向量,特到特徵向量 z∗ z^*,之後便可以對於每個輸入年齡,查詢其年齡向量,並將該年齡向量與輸入圖片特徵向量
論文學習:Learning to Generate Time-Lapse Videos Using Multi-StageDynamic Generative Adversarial Networks
Welcome To My Blog 這篇論文收錄於KDD2018,有關視訊生成的,論文有個專案主頁,題目翻譯過來大致是:使用多階段動態生成對抗網路學習生成time-lapse(延時)視訊. 多階段具體來說是兩階段, 1. 第一階段(Base-Net): 注重每一幀內容的真實性
【論文翻譯】中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Image)
【開始時間】2018.10.08 【完成時間】2018.10.09 【論文翻譯】Attentive GAN論文中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Imag
Generative Adversarial Networks: An Overview文獻閱讀筆記
Generative Adversarial Networks: An Overview筆記 Abstract Generative adversarial networks (GANs) provide a way to learn deep representations w
【GAN ZOO翻譯系列】基於能量的生成對抗網路 Energy-Based Generative Adversarial Networks
趙俊博, Michael Mathieu, Yann LeCun 紐約大學計算機科學系 Facebook人工智慧研究院 {jakezhao, mathieu, yann}@cs.nyu.edu 原文連結https://arxiv.org/abs/1609.031
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image論文理解
概述: 在去雨的過程中給網路加上了attention提取,讓網路能夠更好地學到有雨滴部分的差別。 網路結構如下: 首先使用attention提取網路來獲得包含雨滴的影象的attention影象(值在0-1之間,包含雨滴的地方值較大),attention提取網路中使用通
Speech Bandwidth Extension Using Generative Adversarial Networks
owb codec 同時 ephone 參數 listen 註意 nbu 分數 論文下載地址。博客園文章地址。 摘要 語音盲帶寬擴展技術已經出現了一段時間,但到目前為止還沒有出現廣泛的部署,部分原因是增加的帶寬伴隨著附加的工件。本文提出了三代盲帶寬擴展技術,從矢量量化映
Dual Adversarial Networks for Zero-shot Cross-media Retrieval 閱讀筆記
Dual Adversarial Networks for Zero-shot Cross-media Retrieval (DANZCR):由兩個GAN組成,分別用於共同表示生成與原始表示重建,它們捕獲底層資料結構,並加強輸入資料和語義空間之間的關係,以概括已見和未
Dihedral angle prediction using generative adversarial networks 閱讀筆記
使用生成對抗網路的二面角預測 Abstract 為蛋白質結構預測及其他應用開發了幾種二面角預測方法。 然而,預測角度的分佈與實際角度的分佈不同。 為了解決這個問題,我們採用了生成對抗網路(GAN),它在影象生成任務中顯示了有希望的結果。 生成性對抗網路由兩
LSGAN (Least Squares Generative Adversarial Networks)
1.前言 傳統GAN出現的問題: 傳統GAN, 將Discriminator當作分類器,最後一層使用Sigmoid函式,使用交叉熵函式作為代價函式,容易出現梯度消失和collapse mode等問題,具體原因參考本部落格Wasserstein GAN。 LSG
Machine Learning is Fun Part 7: Abusing Generative Adversarial Networks to Make 8
The goal of Generative ModelsSo why exactly are AI researchers building complex systems to generate slightly wonky-looking pictures of bedrooms?The idea is