
深度學習網路篇——ZFNet(Part3 ZFNet的實驗環節)
上篇ZFNet的文章中我們簡單的分享了一下ZFNet的網路結構和訓練細節,這篇文章將分享ZFNet論文上的實驗環節。ZFNet做了很多巧妙的實驗,從這邊文章中也可以看到未來深度網路發展方向的蛛絲馬跡。
一、Experiments實驗
1.ImageNet 2012
該資料集由1.3M / 50k / 100k的訓練/驗證/測試樣例組成,分佈在超過1000個類別中。
首先,使用(Krizhevsky等,2012)中指定的確切體系的模型,我們嘗試在驗證集上覆制它們的結果。
1)我們在ImageNet 2012驗證集,錯誤率達到其報告值的0.1%
2)與作者給出的錯誤率很一致。以此作為參考標準。
我們用新修改的模型,分析效能,獲得了不錯的結果。
該模型顯著地打敗了(Krizhevsky等,2012)的架構,擊敗了他們的單個模型的結果1.7%(測試top 5的成績)。
當我們組合多個模型時,我們獲得了14.8%的測試誤差,釋出效能中最佳。
我們注意到,這個錯誤幾乎是ImageNet 2012分類挑戰中頂級成績(使用非卷積網路)錯誤率的一半,它獲得了26.2%的錯誤(Gunji et al,2012)

【上圖解讀】ImageNet 2012分類錯誤率。 *表示在ImageNet 2011和2012訓練集上都訓練過的模型。
2.不同的ImageNet模型尺寸
1.對AlexNet:通過調整層的大小或刪除層(如 調整隱含層的節點個數或者將某隱含層直接刪除等)
------在每種情況下,都會使用修改後的架構從頭開始訓練模型。
2.移除全連線層(6,7)
------只會略微增加錯誤率。
------這令人驚訝的,因為它們包含大多數模型引數。
3.移除兩個中間卷積層
------使錯誤率稍微增加。
4.去除中間卷積層和全連線層,僅有4層的模型,其分類效能顯著更差。
------這表明模型的整體深度與分類效果密切相關。
5.ZFNet改變全連線層的節點個數對效能幾乎沒有影響
------增加中間卷積層的節點個數可以提高效能。
------擴大全連線層出現過擬合的可能。
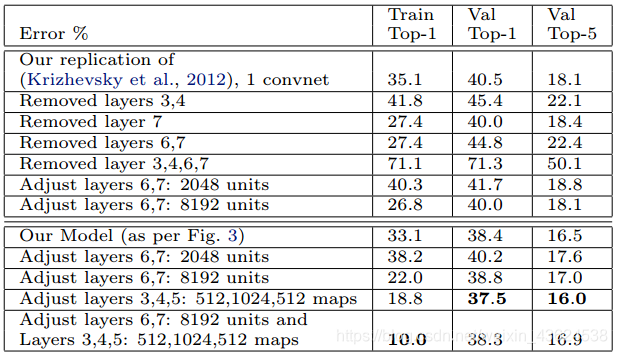
【上圖解讀】模型的各種架構變化
3.特徵泛化能力
1)為了測試模型的泛化能力,我們現在推廣到其他資料集,
------即Caltech-101(Feifei等,2006),Caltech-256(Griffin等,2006)和PASCAL VOC 2012。
2)保持模型的1-7層的訓練結果,使用新資料集的訓練影象在頂部(適當數量的類)訓練新的softmax分類器。
3)由於softmax包含相對較少的引數,因此可以從相對少量的示例中快速訓練,如某些資料集的情況。
4)其他分類器(SVM)在複雜度上很相似,也對比了本文學習到的特徵是否可用到其他分類器上。
5)從ImageNet學習的特徵表示與其他方法使用的手工製作的特徵進行比較。
6)從新訓練模型的,即將層1-7重置為隨機值並在資料集的訓練影象上訓練它們以及softmax。
Caltech-101
我們按照(Fei-fei等人,2006)的程式,每類隨機選擇15或30張影象進行訓練,並測試每類最多50張影象,表4中報告了每類精度的平均值,使用5折訓練/測試。
30張影象/類的訓練需要17分鐘。
預訓練模型擊敗了來自(Bo等人,2013)的30個影象/類的最佳結果2.2%。
然而,從Caltech-101庫從零開始訓練的網路模型確實非常糟糕,僅達到46.5%。
說明基於ImageNet學到的特徵更有效。
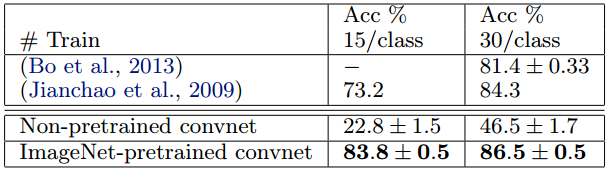
【上圖解讀】表4 Caltech-101歷史最好的2個成績與本模型成績的對比
Caltech-256
我們按照(Griffin等,2006)的程式,每類選擇15,30,45或60個訓練影象,表5中每報告類精度的平均值。
我們的ImageNet預訓練模型擊敗了Bo等人獲得的當前最先進的結果。與(Bo等人,2013年)顯著差異:60個訓練影象/類別的成績74.2%比55.2%,準確率高出19%的巨大優勢。
然而,與Caltech-101一樣,從新開始訓練的模型也很差,分類精度只有38.8%。
在圖9中,我們探討了“一次性學習”(Fei-fei et al。,2006)制度,從另一個角度描述了基於ImageNet預學習模型的成功。
使用我們預訓練的模型,只需要6張Caltech-256訓練影象就可以使用10倍的影象來擊敗領先的方法。
顯示了ImageNet特徵提取器的強大功能。

Caltech-256分類效能,因為每個類的訓練影象數量是多種多樣的。 通過我們的預訓練特徵提取器,
每個類僅使用6個訓練樣例,我們超過了最佳報告結果(Bo et al。,2013)。
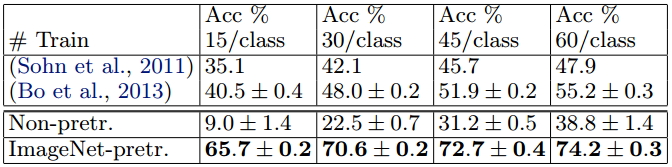
【上圖解讀】表5 Caltech歷史最好的兩個成績與本文模型成績的對比。
PASCAL 2012
我們使用標準的訓練和驗證影象在ImageNet預訓練的網路上訓練20路softmax分類器。
結果並不理想,因為PASCAL影象可以包含多個物體,而我們的模型只為每個影象提供單個預測。
PASCAL和ImageNet影象在本質上是完全不同的,兩者是不同的完整場景。
這可以解釋我們的平均表現比領先(Yan et al,2012)結果低3.2%,但是我們確實在top5上擊敗它們,有些類別優勢很明顯。

【上圖解讀】表6顯示了測試集上的結果。PASCAL 2012分類結果,將我們的與ImageNet訓練網路與歷史前兩種最好的方法進行比較([A] =(Sande等,2012)和[B] =(Yan等,2012))。
4.Feature Analysis特徵分析
Imagenet預訓練模型的每一層中的特徵是如何區別的。
改變ImageNet模型中保留的前n層,並在頂部連線線性SVM或softmax分類器。
表7顯示了Caltech-101和Caltech-256的結果。
------模型學習到的特徵同樣適用於SVM進行分類。
對於這兩個資料集,隨著保留層的增加,分類能力穩定的改進。
------當保留全部層時,獲得最佳分類結果。
這支援了:當網路變得更深時,它們會學習越來越強大的特性。
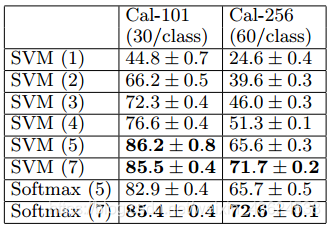
【上圖解讀】分析ImageNet預訓練卷積網路中,每層特徵對映中包含的區分性資訊。我們在來自卷積網路的不同層(如括號中所示)的特徵上訓練線性SVM或softmax。較高層通常產生更多的辨別性特徵。
二、Discussion 討論
1.本問題出了一種新的視覺化方法
這表明這些特徵不是隨機的、無法解釋的模式。相反,當我們提升層次時,它們顯示出許多直觀上令人滿意的屬性,例如組合性,增加不變性和類別區分性。
2. 使用視覺化方法發現模型問題,並得到更好模型
例如改進Krizhevsky等人(Krizhevsky等,2012)令人印象深刻的ImageNet 2012結果
3. 通過一系列遮擋實驗,模型雖經過分類訓練,但對影象中的區域性結構非常敏感,不僅僅使用場景上下文。
4. 對模型的消融研究表明(分層),網路的深度對模型非常重要
5. 用ImageNet訓練模型,驗證模型的泛化能力,推廣到其他資料集。
a) 對於Caltech-101和Caltech-256,資料集足夠相似,我們可以擊敗歷史上的最佳結果。
b) 我們的預測模型不太適用於PASCAL資料,可能遭受資料集偏差;
儘管它仍然在最佳報告結果的3.2%之內,沒有調整模型來適應分類任務。如果使用允許每個影象有多個物件的不同損失函式,我們的效能可能會提高。這自然會使網路也能夠解決物件檢測問題。
謝謝大家看到這裡,也感謝以下論文和部落格的支援。蟹蟹大家~
https://blog.csdn.net/loveliuzz/article/details/79080194
https://blog.csdn.net/chenyanqiao2010/article/details/50488075
https://blog.csdn.net/qq_31531635
https://blog.csdn.net/jningwei/article/details/80026826
https://www.cnblogs.com/taojake-ML/p/6287158.html
最後的最後,因為我們還是機器學習剛入門的小學生,有些理解不到位的地方還請大大們指出。部落格最近兩個月會每週都至少更新一篇深度學習網路篇的理解(下一週是VGG和NIN哦~),還請大家多多支援!蟹蟹!!!