
深度學習網路篇——AlexNet
作為一個機器學習剛入門的小學生,今天和大家分享的是一篇比較經典的論文《ImageNet Classification with Deep Convolutional Neural Networks》。只是我們在學習後的知識分享和總結,有不周到的地方還請各位大大們指正。
簡要概括
AlexNet是2012年ImageNet競賽冠軍Hinton和他的學生Alex Krizhevsky提出設計的,官方資料上網路所得的top-1和top-5錯誤率分別為37.5%和17.0%。
AlexNet採用了8層的神經網路,其中包含5個卷積層(其中有3個卷積層後連線了最大池化層),3個全連線層和最後的softmax層。AlexNet裡面包含了6千萬個引數和65萬個神經元。為了防止過擬合,採用了正則化方法“Dropout”;為了提高訓練和執行速度,採用了雙GPU的設計模式。
AlexNet的重中之重!
敲黑板!!!劃重點!!!AlexNet最重要的部分就是下圖中的網路結構!可能小夥伴們看著這張圖覺得有些莫名其妙,所以大家對照著下圖思路就可以把AlexNet這塊骨頭啃下來了!(友情提示:備註要認真看哦~)
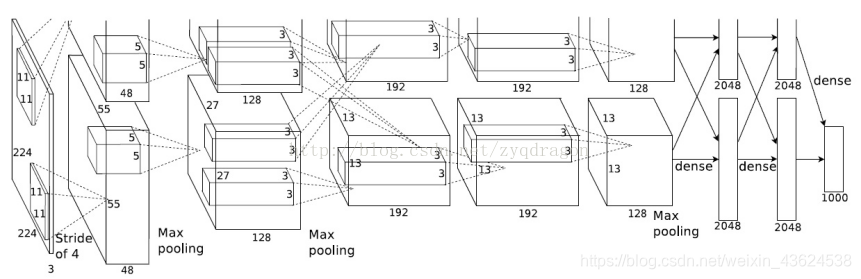
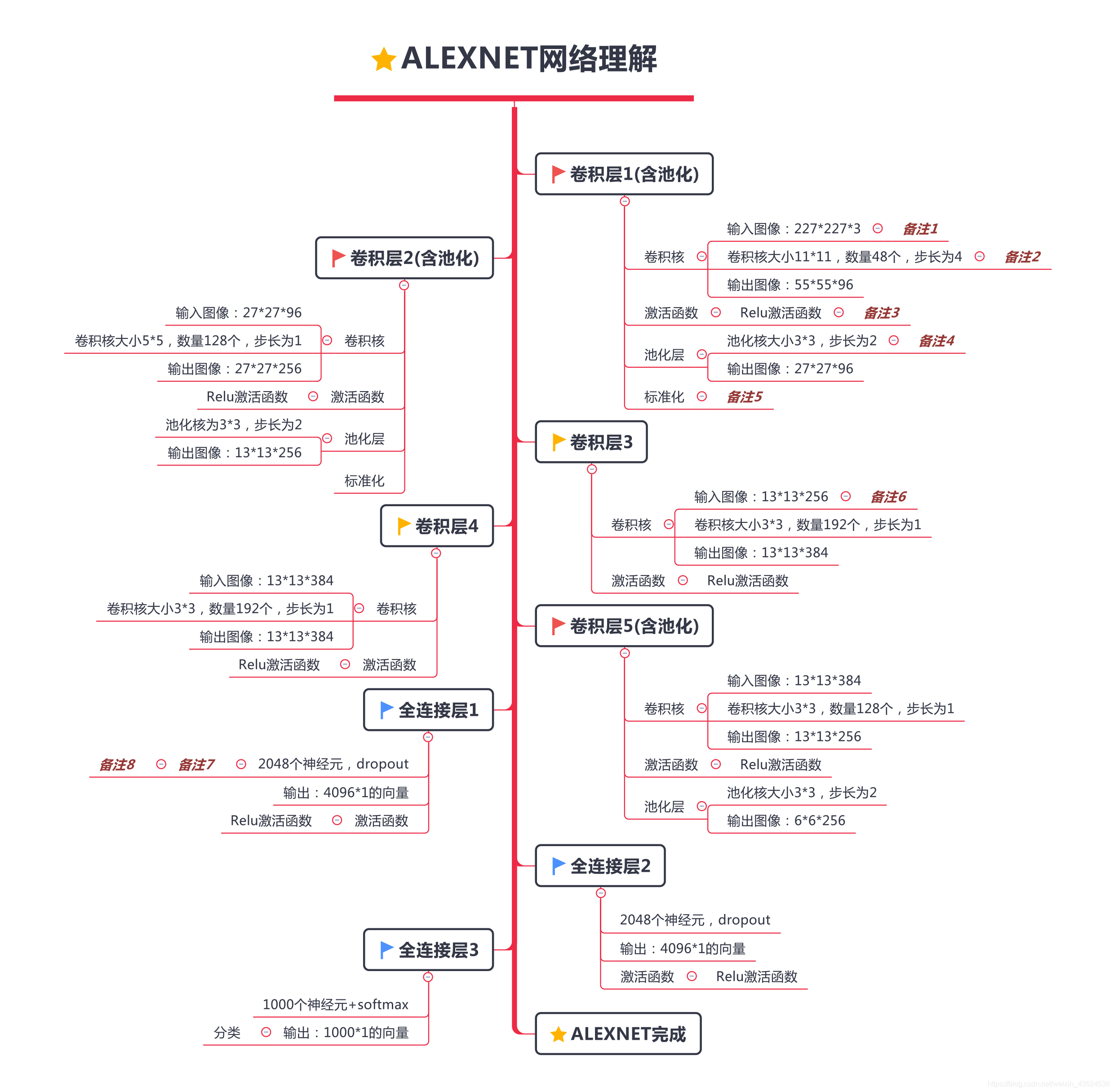

AlexNet總結
AlexNet對於在此之前的傳統的機器學習分類演算法而言可以說是非常出色了。它有很多的小tips(很多想法不是這篇文章提出的,但是在這篇文章中是閃光點,也把它們總結了一下),比如:
一、網路架構方面:
1.Relu啟用函式:效果優於tanh函式和Sigmoid函式,解決了梯度消失的問題,收斂速度更快;
2.最大池化的使用:AlexNet使用的池化步長比池化核的尺寸小,池化層輸出會有重疊和覆蓋;
3.使用了局部響應歸一化(LRN):簡單來說就是“強者更強,弱者更弱”。
二、訓練速度方面:
1.使用了兩個GPU計算,提高了準確率(說明:多卡並不會提高準確率,但是在這篇文章的第二三層卷積層之間用了兩個GPU的“串聯”,提高了準確率),增加視訊記憶體,加快了計算速度和訓練速度;
三、防止過擬合方面:
1.資料增強:AlexNet做了兩方面的資料增強;一是對於原始影象(256x256x3)做水平翻轉,隨機擷取為224x224x3的影象尺寸大小,這使得訓練樣本數量擴增了2048倍,提升了模型的泛化能力;二是對原始影象的RGB通道做了PCA主成分分析,即對於圖片的每個畫素提取RGB三個通道的特徵向量和特徵值,再乘以一個均值為0.1方差服從高斯分佈的隨機變數α;
2.正則化方法Dropout:隨機忽略一部分的神經元,設定一個keep_prob來表示這個神經元的保留概率,這迫使神經網路不會過度的依賴某個神經元或者特徵。AlexNet在訓練過程中令keep_prob為0.5,在測試過程中,令keep_prob為1(全部啟用),但所有輸出值乘以0.5;
最後的最後,因為我們也是機器學習剛入門的小學生,有些理解不到位的地方還請大大們指出。部落格最近兩個月會每週都至少更新一篇深度學習網路篇的理解(下一週是ZFNet網路哦~),網路篇的程式碼實現會在稍後附上,還請大家多多支援!蟹蟹!!!