
PHP7核心學習--語言的執行原理
我們常用的高階語言有很多種,比較出名的有C\C++、Python、PHP、Go、Pascal等。而這些語言根據執行的方式不同,大體分為兩種:
編譯型語言和解釋型語言。
其中,編譯型語言包括C\C++、Pascal、Go等。這裡說的編譯是指在應用源程式執行之前,就將程式原始碼編譯成組合語言,然後進一步根據軟硬體環境"翻譯"成目標檔案。一般稱完成編譯工作的工具為編譯器。而解釋型語言,在程式執行時才被“翻譯”為機器語言。但是執行一次“翻譯”一次,所以執行效率較低。直譯器的工作就是解釋型語言中,負責“翻譯”原始碼的程式。

我們對編譯型語言與解釋型語言的區別的理解,立足於原始碼被編譯成目標平臺CPU指令的時機
編譯型語言,編譯結果已經是針對當前CPU體系的指令;而解釋型語言,需要先編譯成中間程式碼,再經由該解釋型語言的特定虛擬機器,翻譯成特定CPU體系的指令被執行。解釋型語言是在執行過程中,翻譯為目標平臺的指令。常說解釋型語言“慢”,主要也是慢在這裡。
php7中執行原理
在PHP 7中,
原始碼首先進行詞法分析,將原始碼切割為多個字串單元,分割後的字串稱為Token。而一個一個獨立的Token是無法表達完整語義的,需經過語法分析階段,將Token轉換為抽象語法樹(簡稱AST)。之後,抽象語法樹被轉換為機器指令執行。在PHP中,這些指令稱為opcode(以後會對opcode做更詳細的解釋,此處可以將其看待為CPU指令)。
到AST的生成這一步,編譯型語言與解釋型語言所需經歷的過程相似。從抽象語法樹之後開始產生差異。
簡圖(最後一步的左側分支是編譯型語言的過程)
第1步:原始碼通過詞法分析得到Token。
第2步:基於語法分析器生成抽象語法樹(AST)。
第3步:抽象語法樹轉換為opcodes(opcode指令集合),PHP解釋執行opcodes。

接下來在基本步驟的基礎上,細化PHP語言的執行原理,以便更清晰地建立認知。
第1步:詞法分析將PHP程式碼轉換為
有意義的標識Token。該步驟的詞法分析器使用Re2c實現。
第2步:語法分析將
Token和符合文法規則的程式碼生成抽象語法樹。語法分析器基於Bison實現。語法分析使用了BNF(Backus-Naur Form,巴科斯正規化)來表達文法規則,Bison藉助狀態機、狀態轉移表和壓棧、出棧等一系列操作,生成抽象語法樹。
第3步:上步的
抽象語法樹生成對應的opcode,並被虛擬機器執行。opcode是PHP 7定義的一組指令標識,指令對應著相應的handler(處理函式)。當虛擬機器呼叫opcode,會找到opcode背後的處理函式,執行真正的處理。以常見的echo語句為例,其對應的opcode便是ZEND_ECHO。
注意 這裡為了便於理解詞法分析和語法分析過程,將兩者分開描述。但實際情況下,出於效率考慮,兩個過程
並非完全獨立。

下面通過一段示例程式碼,來建立PHP 7運轉的初步理解。
echo "hello world";
這段程式碼首先會被切割為Token
Token
Token是PHP程式碼
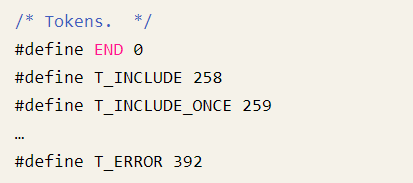
被切割成的有意義的標識。本次使用的PHP 7版本中有137種Token,在zend_language_parser.h檔案中做了定義
http://php.net/manual/zh/tokens.php
PHP提供了token_get_all()函式來獲取PHP程式碼被切割後的Token,可以在深入原始碼學習前,粗略檢視PHP程式碼被切割後的Token。對於如下程式碼片段:
./php -r 'print_r(token_get_all("<?php echo \"hello world\";?>"));'
//輸出:
Array
(
[0] => Array
(
[0] => 379
[1] => <?php
[2] => 1
)
[1] => Array
(
[0] => 328
[1] => echo
[2] => 1
)
[2] => Array
(
[0] => 382
[1] =>
[2] => 1
)
[3] => Array
(
[0] => 323
[1] => "hello world"
[2] => 1
)
[4] => ;
[5] => Array
(
[0] => 381
[1] => ?>
[2] => 1
)
)
其中,二維陣列的每個成員陣列的
第一個值為Token對應的列舉值。第二個值為Token對應的原始字串內容。第三個值為程式碼對應的行號。可以看出,詞法解析器將“<?php echo"hello world";”這段文字內容切分成了4部分。
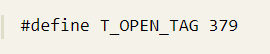
1)文字“<?php”,切割後對應的Token值為379,參考PHP 7中的原始碼:
2)echo對應的Token是T_ECHO,對應的Token值為328:
3)原始碼中的空格,對應的Token為T_WHITESPACE,值為382:
4)字串"hello world",對應的Token值為323:



可見,Token就是一個個的“詞塊”,但是單獨存在的詞塊
不能表達完整的語義,還需要藉助規則進行組織串聯。語法分析器就是這個組織者。它會檢查語法,匹配Token,對Token進行關聯。
PHP 7中,組織串聯的產物就是AST(Abstract Syntax Tree,抽象語法樹)。
AST
AST是PHP 7版本新特性。在這之前的版本中,PHP程式碼的執行過程中是沒有生成AST這一步的。PHP 7對抽象語法樹的支援,實現了PHP編譯器和直譯器解耦,有效提升了可維護性。
顧名思義,抽象語法樹具有樹狀結構。AST的節點分為多種型別,對應著PHP語法。我們可以認為節點型別是對語法規則的抽象,例如賦值語句,生成的抽象語法樹節點為ZEND_AST_ASSIGN。而賦值語句的左右運算元又將作為ZEND_AST_ASSIGN型別節點的孩子。通過這樣的節點關係,構建出抽象語法樹。
PHP-Parser工具,它可以用來檢視PHP程式碼生成的AST。
注意 PHP-Parser是PHP 7核心作者之一Nikic編寫的將PHP原始碼生成AST的工具。原始碼見https://github.com/nikic/PHP-Parser。
opcodes
AST扮演了原始碼到中間程式碼的
臨時儲存介質的角色,還需要將其轉換為opcode,才能被引擎直接執行。opcode只是單條指令,opcodes是opcode的集合形式,是PHP執行過程中的中間程式碼,類似Java中的位元組碼。opcode生成之後由虛擬機器執行。
我們知道,PHP工程優化措施中有一個比較常見的“開啟opcache”,指的就是這裡的opcodes的快取(opcodes cache)。通過省去從原始碼到opcode的階段,引擎可以直接執行快取的opcode,以此提升效能。
藉助vld外掛,可以直觀地看到一段PHP程式碼生成的opcode:(未完待續)