
一致性Hash 分析和實現
一致性Hash 分析和實現
---
title: 1.一致性Hash
date: 2018-02-05 12:03:22
categories:
- 一致性Hash
---
一下分析來源於網路總結:演算法參照自己實現,共參考和指正。
一致性Hash演算法背景
一致性雜湊演算法在1997年由麻省理工學院的Karger等人在解決分散式Cache中提出的,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡單雜湊演算法帶來的問題,使得DHT可以在P2P環境中真正得到應用。
但現在一致性hash演算法在分散式系統中也得到了廣泛應用,研究過memcached快取資料庫的人都知道,memcached伺服器端本身不提供分散式cache的一致性,而是由客戶端來提供,具體在計算一致性hash時採用如下步驟:
- - 首先求出memcached伺服器(節點)的雜湊值,並將其配置到0~232的圓(continuum)上。
- - 然後採用同樣的方法求出儲存資料的鍵的雜湊值,並對映到相同的圓上。
- - 然後從資料對映到的位置開始順時針查詢,將資料儲存到找到的第一個伺服器上。如果超過232仍然找不到伺服器,就會儲存到第一臺memcached伺服器上。
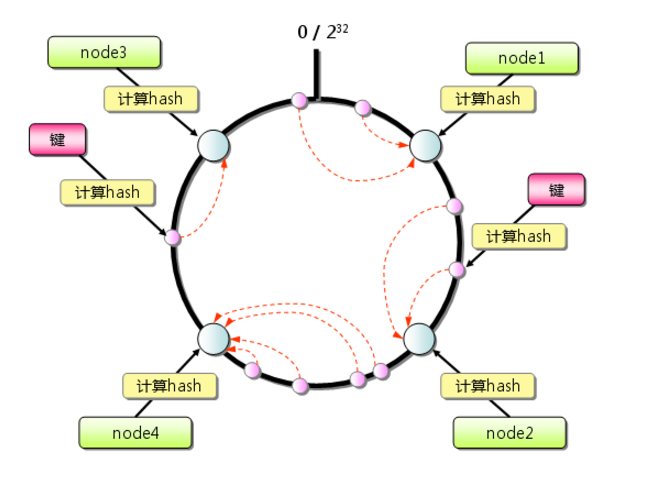
從上圖的狀態中新增一臺memcached伺服器。餘數分散式演算法由於儲存鍵的伺服器會發生巨大變化而影響快取的命中率,但Consistent Hashing中,只有在園(continuum)上增加伺服器的地點逆時針方向的第一臺伺服器上的鍵會受到影響,如下圖所示:
原理
基本概念
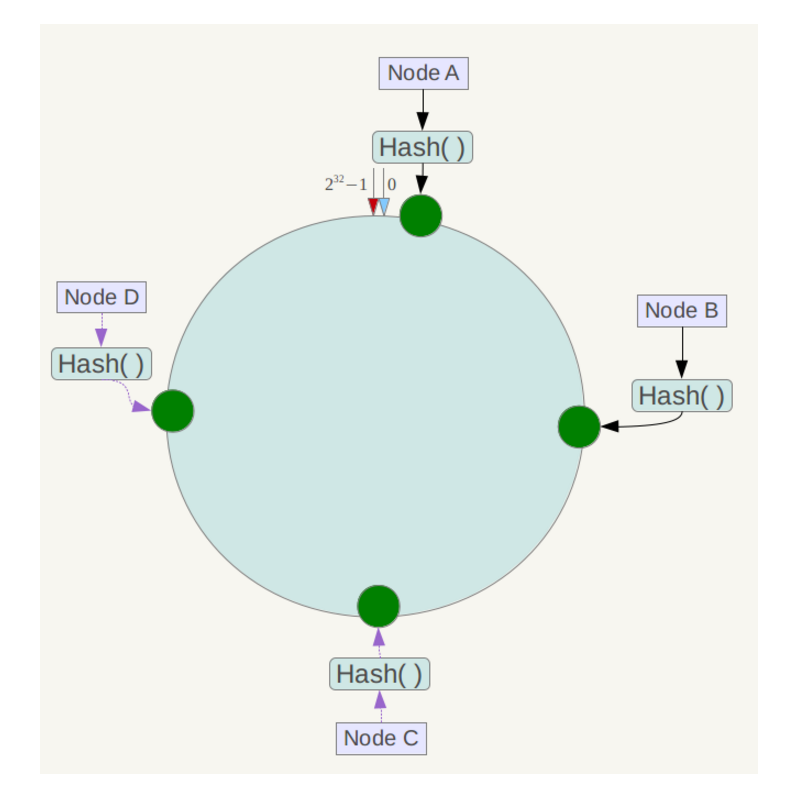
簡單來說,一致性雜湊將整個雜湊值空間組織成一個虛擬的圓環,如假設某雜湊函式H的值空間為0-2^32-1(即雜湊值是一個32位無符號整形),整個雜湊空間環如下:

整個空間按順時針方向組織。0和232-1在零點中方向重合。
下一步將各個伺服器使用Hash進行一個雜湊,具體可以選擇伺服器的ip或主機名作為關鍵字進行雜湊,這樣每臺機器就能確定其在雜湊環上的位置,這裡假設將上文中四臺伺服器使用ip地址雜湊後在環空間的位置如下:
接下來使用如下演算法定位資料訪問到相應伺服器:將資料key使用相同的函式Hash計算出雜湊值,並確定此資料在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的伺服器就是其應該定位到的伺服器。
例如我們有Object A、Object B、Object C、Object D四個資料物件,經過雜湊計算後,在環空間上的位置如下:
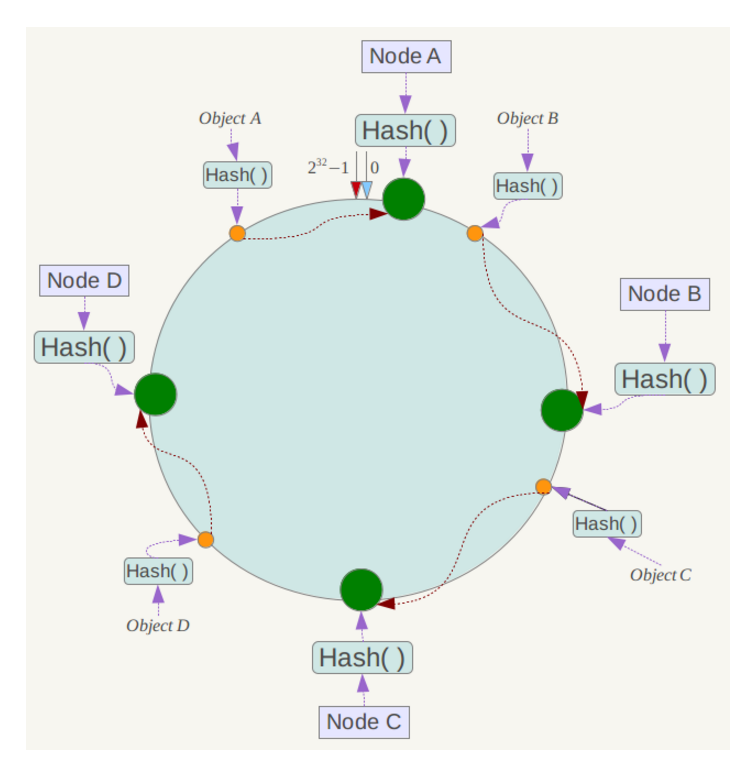
根據一致性雜湊演算法,資料A會被定為到Node A上,B被定為到Node B上,C被定為到Node C上,D被定為到Node D上。
下面分析一致性雜湊演算法的容錯性和可擴充套件性。現假設Node C不幸宕機,可以看到此時物件A、B、D不會受到影響,只有C物件被重定位到Node D。一般的,在一致性雜湊演算法中,如果一臺伺服器不可用,則受影響的資料僅僅是此伺服器到其環空間中前一臺伺服器(即沿著逆時針方向行走遇到的第一臺伺服器)之間資料,其它不會受到影響。
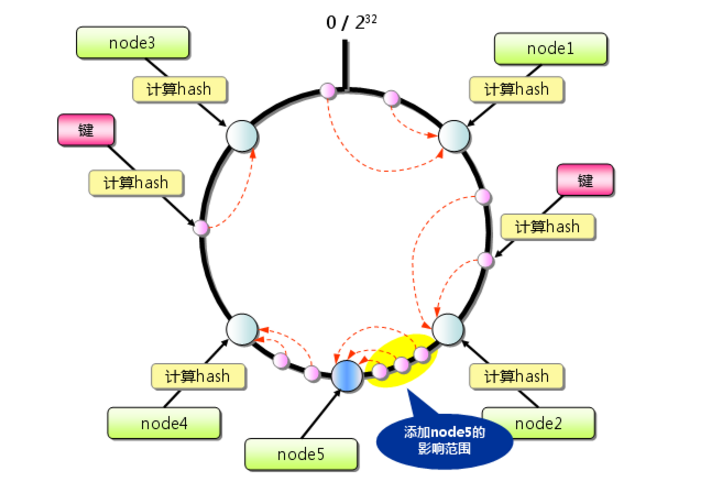
下面考慮另外一種情況,如果在系統中增加一臺伺服器Node X,如下圖所示:
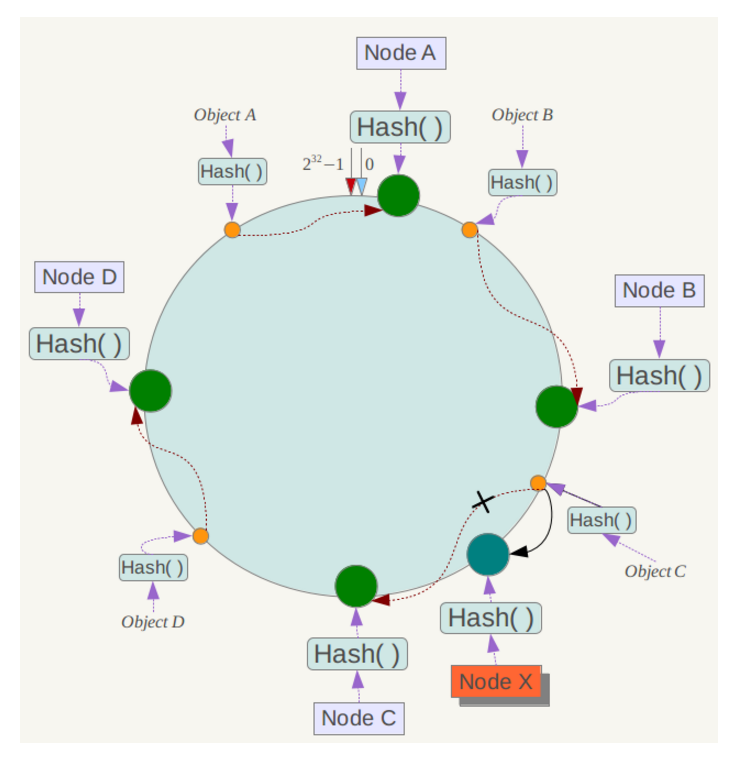
此時物件Object A、B、D不受影響,只有物件C需要重定位到新的Node X 。一般的,在一致性雜湊演算法中,如果增加一臺伺服器,則受影響的資料僅僅是新伺服器到其環空間中前一臺伺服器(即沿著逆時針方向行走遇到的第一臺伺服器)之間資料,其它資料也不會受到影響。
綜上所述,一致性雜湊演算法對於節點的增減都只需重定位環空間中的一小部分資料,具有較好的容錯性和可擴充套件性。
演算法實現:
1 package com.maozw.algorithm; 2 3 import java.util.SortedMap; 4 import java.util.TreeMap; 5 6 /** 7 * @author MAOZW 8 * @Description: 不帶虛擬節點的一致性Hash演算法 9 * @date 2018/11/22 16:30 10 */ 11 public class ConsistentHashNoNode { 12 13 /** 14 * 初始化 key表示伺服器的hash值,value表示伺服器的名稱 15 */ 16 private static SortedMap<Integer, String> serverHashMap = new TreeMap<Integer, String>(); 17 18 public static String getServer(String data) { 19 return serverHashMap.get(serverHashMap.tailMap(hash(data)).firstKey()); 20 } 21 22 /** 23 * 構建hash環 24 * @param servers 25 */ 26 public ConsistentHashNoNode(String[] servers) { 27 for (int i = 0; i < servers.length; i++) { 28 int hash = hash(servers[i]); 29 serverHashMap.put(hash, servers[i]); 30 } 31 } 32 33 /** 34 * FNV1_32_HASH 百度 35 * @param str 36 * @return 37 */ 38 public static int hash(String str) { 39 final int p = 16777619; 40 int hash = (int)2166136261L; 41 for (int i = 0; i < str.length(); i++) { 42 hash = (hash ^ str.charAt(i)) * p; 43 } 44 hash += hash << 13; 45 hash ^= hash >> 7; 46 hash += hash << 3; 47 hash ^= hash >> 17; 48 hash += hash << 5; 49 return Math.abs(hash); 50 } 51 52 public static void main(String[] args) { 53 //構建伺服器列表 54 String[] servers = {"192.168.1.0:098", "192.168.1.0:099", "192.168.1.0:100","192.168.1.0:111", "192.168.1.1:112", "192.168.1.2:113", "192.168.0.3:114", "192.168.0.4:115"}; 55 new ConsistentHashNoNode(servers); 56 for (int i = 0; i < 10; i++) { 57 System.out.println("data : " + i + ", hash " + hash(String.valueOf(i)) + " >>>>>>> " + getServer(String.valueOf(i))); 58 } 59 } 60 }
輸出結果:
data : 0, hash 1360261864 >>>>>>> 192.168.0.4:115 data : 1, hash 1081142246 >>>>>>> 192.168.0.3:114 data : 2, hash 1310673766 >>>>>>> 192.168.0.4:115 data : 3, hash 895667540 >>>>>>> 192.168.0.3:114 data : 4, hash 1066967047 >>>>>>> 192.168.0.3:114 data : 5, hash 1039214538 >>>>>>> 192.168.0.3:114 data : 6, hash 853429834 >>>>>>> 192.168.0.3:114 data : 7, hash 679338660 >>>>>>> 192.168.0.3:114 data : 8, hash 570677376 >>>>>>> 192.168.0.3:114 data : 9, hash 1632757952 >>>>>>> 192.168.1.0:098
另外,一致性雜湊演算法在服務節點太少時,容易因為節點分部不均勻而造成資料傾斜問題。例如系統中只有兩臺伺服器,其環分佈如下,
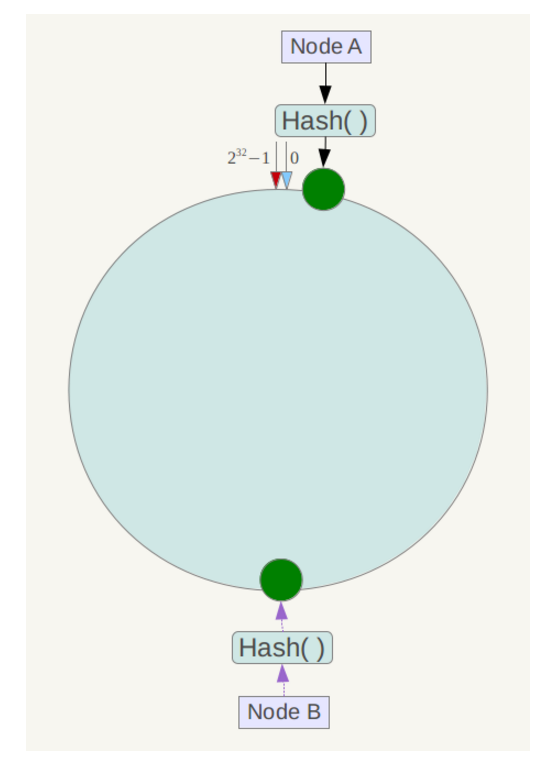
此時必然造成大量資料集中到Node A上,而只有極少量會定位到Node B上。為了解決這種資料傾斜問題,一致性雜湊演算法引入了虛擬節點機制,即對每一個服務節點計算多個雜湊,每個計算結果位置都放置一個此服務節點,稱為虛擬節點。具體做法可以在伺服器ip或主機名的後面增加編號來實現。例如上面的情況,可以為每臺伺服器計算三個虛擬節點,於是可以分別計算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的雜湊值,於是形成六個虛擬節點:
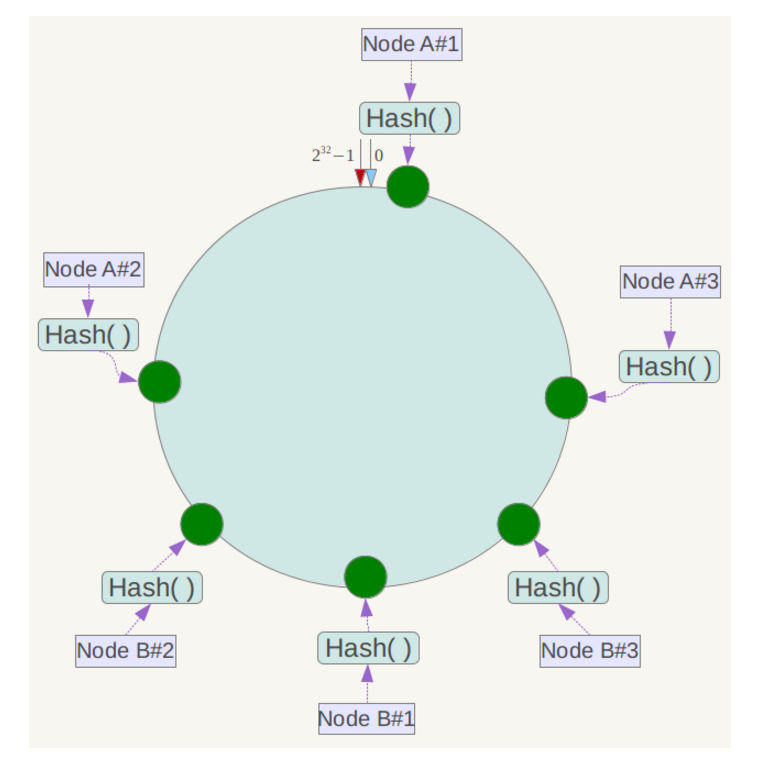
同時資料定位演算法不變,只是多了一步虛擬節點到實際節點的對映,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三個虛擬節點的資料均定位到Node A上。這樣就解決了服務節點少時資料傾斜的問題。在實際應用中,通常將虛擬節點數設定為32甚至更大,因此即使很少的服務節點也能做到相對均勻的資料分佈。
演算法實現: