
python 爬蟲 入門 commit by commit -- commit1
"每一個commit都是程式設計師的心酸,哦不,心路歷程的最好展示。" -- by 我自己
最近寫好了一組文章,來這裡,當然一如我以前一樣,主要是宣傳。但是,最近發現gitbook老是掛掉,除了宣傳,我覺得,在這裡全部貼一遍,這樣就算是gitbook那邊不穩定,至少這裡還能看到。不過說實話,如果有興趣的話,我還是推薦去gitbook那邊看,因為部落格園的結構,貌似不適合這種系列型的文章。
目前所有完結版本都已經可以在https://rogerzhu.gitbooks.io/python-commit-by-commit/content/ 看到,因為部落格園一天只能貼一篇首頁的文章,所以我可能需要一點時間把所有的都貼完。當然,你可以去gitbook上看已經完結的。而程式碼,我放在了
廢話少說,搬運工作開始:
Commit1
"F12才是爬蟲開發的最好的朋友" -- by 我自己
既然叫commit by commit,那就要按照自己給自己定下的規矩來寫。在把程式碼clone到本地之後,你可以用git reset --hard 6fda96eae來退回到程式碼的第一個版本。別擔心回不去後面的版本,這commit都在github都能看到,即使你不知道一些奇技淫巧的git命令也沒啥,大膽幹。
首先,我覺得我應該說這個commit我想幹嘛,第一個commit,我是想作為熟悉的門檻,所以這個commit最開始我的本意是想獲得京東圖書程式語言第一頁上面的書名,連結。
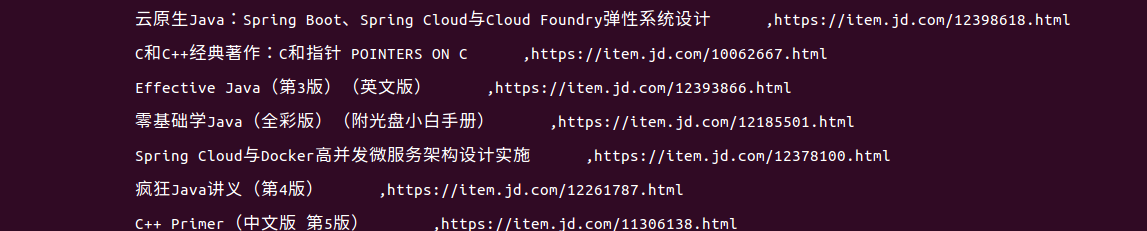
對於這個commit,當你輸入如下命令開始執行時:

你應該能看到如下的結果:
前面已經扯了兩篇了,那麼從這篇開始步入技術的正軌了,其實從骨子裡我是很討厭那種教程裡敲半個小時程式碼,最後發現就是一個輸出了一個星號組成的圖案。我覺得,入門級別的程式碼得用不超過10分鐘的時間幹出一點你能看得到,有成就感的正事才能吸引大部分的注意力。可惜啊,C++在這方面確實很難做到,而python在這方面絕對是擅長。所以,第一個commit雖然我的comment是ugly commit,但是絕對能幹活。
既然是入門級別的文章,那麼就從最基本的部分開始,當你瀏覽一個網頁的時候,實際上,你在瀏覽什麼?實際上你在瀏覽的是伺服器傳回來的一系列檔案,這一系列檔案由瀏覽器解析,然後呈現給你。比如我想看看京東圖書程式語言下面的所有圖書,我只要用滑鼠一點一點的點到我想要的地方就可以看到我需要的網頁。
開心的是,主流瀏覽器都帶有這種工具,而且獲取這一組工具的方法都是隻要簡單的按下F12就可以了,我敢保證,當你按下這個鍵的時候,你有一種打開了新世界的感覺。比如我用的火狐,按下F12之後在最左邊,你會看到這樣一個圖示:

點選一下這個圖示再移到介面上,你會發現你可以以矩形的方式選擇頁面上的元素。根據人的本能,點選一下,你會發現圖示下面的html會自動定義到選中的元素!這樣,拿到什麼資訊,你只要負責選擇就好了,瀏覽器自帶的工具會自動幫你定位。比如,我想要的圖書的名字和價格,我選中某一格的圖書,就會看到這樣的輸出:

那麼我就用上面說的小箭頭選取到我決定的方塊,可以得到標識這每一方塊的元素是<li>。而在這個HTML中,有無數的li,我們怎麼能定位到我們需要的這個li呢?這裡,讓我不得不想起一個諺語,叫贈人玫瑰手有餘香。在前端程式設計師在開發他們的網頁時,他們需要對元素進行標識,這樣他們才能在程式碼中方便的寫出想要的邏輯。而這個行為,給爬蟲程式設計師們提供了便利,你可以用他們歸類的標識來定位你需要的元素,當然,我這裡說的是在程式碼裡。而beautifulsoup這個包可以非常的方便的讓你完成這件事情,你可以選擇用id,class等等來找到你需要的元素。而在這裡,如果你按照我說的使用箭頭工具的話,會很容易的看到在這個網頁中gl-item這樣的class來標識每一個列表塊。那麼剩下的就是按照已經發現的,翻譯成為程式語言了。
在第一個commit裡面,程式碼一共22行,我都忍不住用截圖的方式展示一下以便於說明。
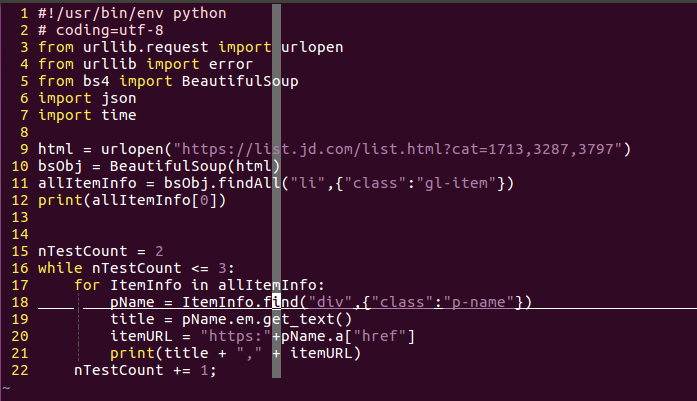
這個程式碼前7行都是shebang,coding的設定和import包。這裡你不知道shebang也一點也不影響你對於這一系列問斬的閱讀理解。所以說,正文從第九行看起就行了。
首先python提供了非常方便的方法獲取網頁的原始碼,我以前最開始的時候使用C++寫過爬蟲,怎麼形容呢?如果python爬蟲的給力程度是他孃的義大利炮,那麼c++就是純物理攻擊了。你只需要使用urllib中的request.urlopen就能直接獲取到網頁原始碼。而需要的引數僅僅是網頁的url。一如第九行所示。
當有了原始碼之後,按照前面介紹的邏輯,就是尋找對應的元素了,而這個時候就是BeautifulSoup包上場的時候了,把得到的原始碼字串作為引數傳給BeautifulSoup庫,你就會得到一個強大的方便解析的BeautifulSoup物件。而在BeautifulSoup中,使用findAll你就可以找到全部的帶有某種標識的某種元素。比如說,在我們要爬取的頁面上,有很多的書,而我們又知道每個書所存在的塊是以gl-item的class來標識的列表,那麼只要對findAll傳入元素名稱和標識規則就行了。而BeautifulSoup還提供一個find函式,用來找到第一個符合標識的物件。
既然已經得到需要的一大塊了,剩下的就是在這一大塊中找到自己想要的資訊,比如我想要的書名和連結地址。其實這後面的過程就是前面描述的過程的重複。大致就是找到頁面->按下F12->使用選擇工具->找到對應的元素塊。但是程式設計師嘛,都很懶,能少動幾下滑鼠是幾下,所以,如果一個塊中元素規模不大的並且基本都相像的情況下,我會使用這樣的一種辦法:把一大塊的html片段輸出到一個檔案裡。如果你覺得我說的有點繞了,那麼其實我想表達的就是第12行語句的意思,雖然我這裡用的是print,但是你可以使用重定向的功能將這個輸出到一個檔案中,也就是"> item.txt"類似的語句。而如果你檢視這個commit的目錄結構,你就會看到這麼一個檔案。如果好奇心仍驅使你開啟它,那麼你就可以看到一個li中的所有內容。這樣就省去了前面那四個步驟的煩惱,而且你可以反覆檢視,而不用反覆的開啟瀏覽器。

當然,這是在我下面的迴圈還沒有寫出來的時候先輸出的。
談到這個while迴圈,在這裡你可以完全忽略,或者說你可能會揣測這到底有什麼深意。其實沒啥深意,就是為了後面用的,而且還是比較後面的commit中才會用到。我只是有點懶,懶得刪除。實際上,這個程式的第15,16以及22行完全可以刪除,對於最後的結果完全沒有任何影響。
而這裡的for迴圈是肯定必要的。python的語法,按照其cookbook上說,已經非常接近自然語言了,從有的方面看真的是這樣的,比如說第17行,表示是依次取出allItem中的所有元素,對於每一個元素就是一個li塊,剩下的只要從這些li塊中再繼續尋找需要的資訊就可以了。比如,書的標題實在class為p-name的div元素之中。而在這個頁面上,真正的標題文字是放在強調標籤<em>之中。這都不能難住強大的BeautifulSoup庫,其物件可以像訪問結構中成員一般一層一層的找到需要的元素。如果想要獲得某個標籤中的文字,只需要使用get_text函式就可以獲得。用程式碼說話的話就是18,19行。
而有的時候我們不是要獲取某個標籤中的元素,而是要獲取某個標籤中的屬性怎麼辦?BeautifulSoup用近乎完全符合自然思維的方式實現了這一點。比如超連結,一般都是在<a>標籤中href屬性之中,那麼href就是a這個成員(字典)的一個關鍵詞,通過這個關鍵詞,你就可以取得其中的值,一如你看到的href="xxx"一樣,典型的key,value結構。也就是程式的第20行,通過這樣的方式,就可以取得每個圖書的連結。
剩下來,就是你怎麼呈現這個資料的部分了,我這裡就簡單大方而又明瞭的輸出,keep it simple,stupid。
這裡,第一個commit就結束了,去掉不需要while迴圈,一共就19行程式碼,在環境配好的情況下,無腦敲完不需要5分鐘,執行python myGAND.py,你就可以看到京東圖書程式語言第一頁的書名和連結列印在控制檯或者檔案中。說實話,如果是C++,你可能還在寫各種字串解析函式的過程中。