
Trie (Prefix Tree) 字首樹
1. 什麼是Trie?
Trie,又稱字首樹或字典樹,是一種有序樹,用於儲存關聯陣列,其中的鍵通常是字串。與二叉查詢樹不同,鍵不是直接儲存在節點中,而是由節點在樹中的位置決定。一個節點的所有子孫都有相同的字首,也就是這個節點對應的字串,而根節點對應空字串。一般情況下,不是所有的節點都有對應的值,只有葉子節點和部分內部節點所對應的鍵才有相關的值。
Trie可以看作是一個確定有限狀態自動機,儘管邊上的符號一般是隱含在分支的順序中的。
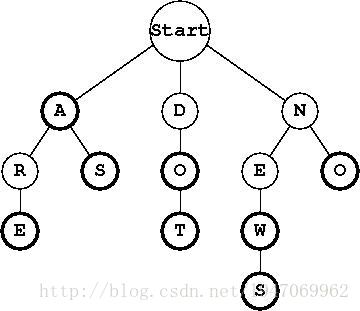
2. Trie的應用
(1) 自動補全
例如,你在百度搜索的輸入框中,輸入一個單詞的前半部分,它能夠自動補全出可能的單詞結果。
(2) 拼寫檢查
例如,在word中輸入一個拼寫錯誤的單詞, 它能夠自動檢測出來。
(3) IP路由表
在IP路由表中進行路由匹配時, 要按照最長匹配字首的原則進行匹配。
(4) T9預測文字
在大多手機輸入法中, 都會用9格的那種輸入法. 這個輸入法能夠根據使用者在9格上的輸入,自動匹配出可能的單詞。
(5) 填單詞遊戲
相信大多數人都玩過那種在橫豎的格子裡填單詞的遊戲。
3. Trie的相關操作
(1)Trie的結點結構
- 根結點一般為空
- 每個結點最多有R個孩子,每個孩子分別對應字母表資料集中的一個字母(通常情況下,R為26,字母表為26個英文字母 ).
- 每個結點都有一個boolean型別的域, 代表這個結點是否是一個key的末尾.
class TrieNode {
// R links to node children
private TrieNode[] links;
private final int R = 26;
private boolean isEnd;
public (2) 向trie中插入一個關鍵字
基本思想:
從根結點開始, 向下依次尋找當前結點的link中, 是否有與關鍵字key中相應位置的字母相同的link;
- 如果有:沿著該link到下一層繼續尋找;
- 如果沒有: 則新建一個node, 插入當前結點的link中,然後沿link到下一層繼續尋找;
向下遍歷到key的末尾時, 修改該結點的boolean指示值,表示是關鍵字末尾.
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char currentChar = word.charAt(i);
if (!node.containsKey(currentChar)) {
node.put(currentChar, new TrieNode());
}
node = node.get(currentChar);
}
node.setEnd();
}
}時間複雜度O(m), m是關鍵字字串的長度; 空間複雜度也為O(m), m是關鍵字字串的長度.
(3) 在trie中查詢一個關鍵字
基本思想:
從根結點開始, 根據關鍵字中的字母,沿著不同的link向下搜尋, 依次比較當前節點的link中是否有和關鍵字相應字母相同的link.
- 如果有,則繼續到下一層搜尋
- 如果沒有, 說明已經到一個單詞的末尾. 此時看關鍵字是否遍歷到了末尾,如果到了末尾的話, 說明匹配成功; 如果沒有到末尾,說明只匹配到了關鍵字的一個字首,匹配失敗.
class Trie {
...
// search a prefix or whole key in trie and
// returns the node where search ends
private TrieNode searchPrefix(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char curLetter = word.charAt(i);
if (node.containsKey(curLetter)) {
node = node.get(curLetter);
} else {
return null;
}
}
return node;
}
// Returns if the word is in the trie.
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEnd();
}
}時間複雜度O(m), m是關鍵字字串長度;空間複雜度O(1).
(4) 在trie中查詢一個關鍵字是否是字首
這個操作和(3)在trie中查詢一個關鍵字很相似, 不同的是, 這裡的關鍵字不必是某個單詞的末尾, 只需是字首即可.
class Trie {
...
// Returns if there is any word in the trie
// that starts with the given prefix.
public boolean startsWith(String prefix) {
TrieNode node = searchPrefix(prefix);
return node != null;
}
}時間複雜度O(m), m是關鍵字字串長度;空間複雜度O(1).
4. Trie的優點
還有其他幾種資料結構,如平衡樹和雜湊表,它們可以在字串資料集中搜索一個單詞。那為什麼我們還需要trie?
雖然雜湊表在查詢某個關鍵字時有O(1)的時間複雜度,但以下操作效率不高:
- 用共同的字首查詢所有的鍵。
- 以字典順序列舉字串資料集。
trie優於雜湊表的另一個原因是,隨著雜湊表的大小增加,會有很多雜湊衝突,搜尋時間複雜度可能會惡化到 O(n ),其中n是插入的f關鍵字的數量。當儲存具有相同字首的多個關鍵字時,Trie可以使用比雜湊表少的空間。在這種情況下,使用trie只有O(m )時間複雜度,其中m是關鍵字長度。而在平衡樹中查詢關鍵字的時間複雜度為 O(m l o g n )。
參考資料:
1. https://en.wikipedia.org/wiki/Trie
2. https://leetcode.com/articles/implement-trie-prefix-tree/